Ruby scripting in Hive Query Language
こんにちは。Web Game事業統括本部 データ基盤チームの lan です。
Advent Calendar 3日目の今日は、Hadoopの上に乗るデータウェアハウスであるApache Hiveについて、話をさせて頂きたいと思います。グリーでは、Hadoopをレポーティングや大規模バッチ処理などに使っています。現在は、Apache Hive 0.12.0版を導入しております。OSSコミュニティから最新の成果をできるだけ早く取り込んでいきたいと考えているからです。
レポートなどのために社内用のUDFライブラリも作っています。しかし、それでもサポートしにくいシーンがまだまだあります。そのために、小さな小さなハッキングをして、HQL内にRubyスクリプティングを利用できる機能を開発しました。RedisのLuaスクリプティングのようなものをイメージするとわかりやすいかもしれません。
今回紹介するのはrb_execとrb_inject、という二つのUDFです。
[追記] 2013-12-18 公開されました。https://github.com/gree/hive-ruby-scripting
簡単な例
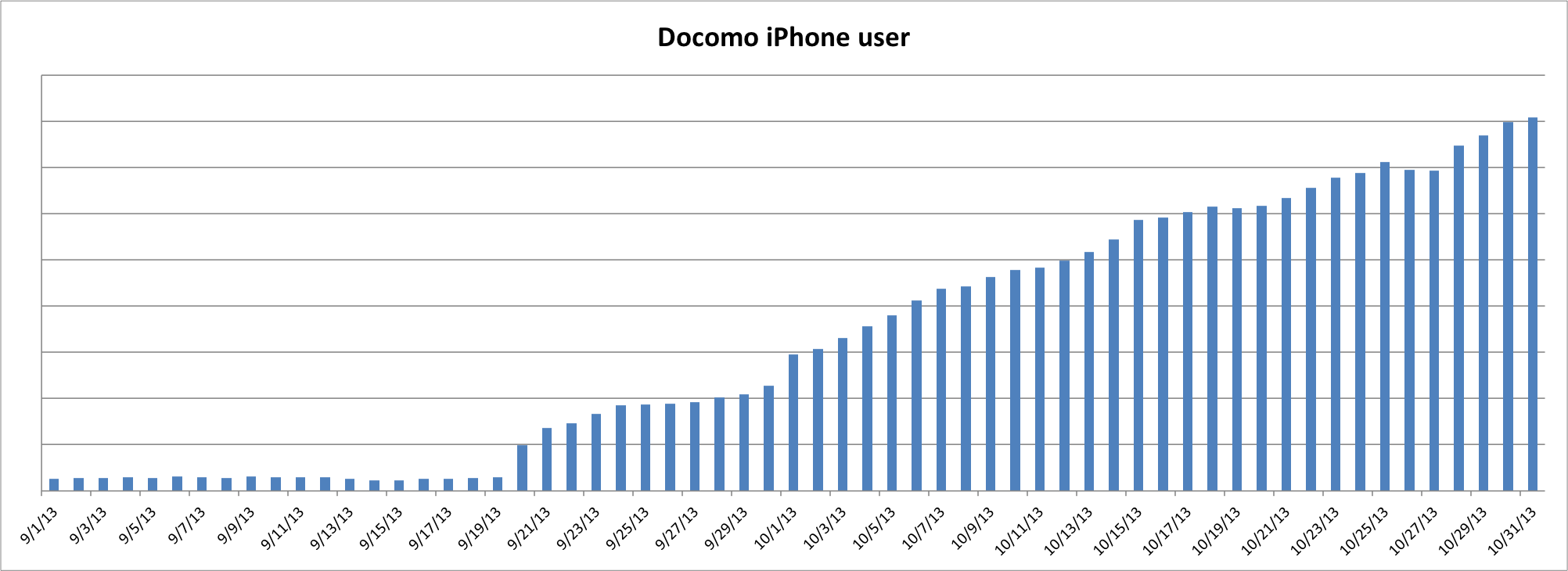
みなさんご存知の通り、9月20日からNTTドコモからもiPhoneが販売されはじめました。ある日、サービスのアクセスログから、NTTドコモのiPhoneユーザーのアクセス推移はどう変わったかを確認したいのだがどうすればよいか、と同僚に聞かれました。厳密ではないですが、アクセスログからNTTドコモのスマートフォンIPアドレスかつUser-AgentがiPhoneであるレコードを時系列で集計すれば、おおよそ分かるはずです。
ただし、あるIPアドレスが1.66.96.0/21のようなIP範囲に入っているかは、単純に文字列の正規表現とかで判断することはできません。Hiveに使えそうな関数もなさそうです。そこで,in_IP_range()みないなUDFを作ることが考えられます。コーディングすること自身は難しいことではないですが、JavaでUDFを書く、Unit Testで動作確認、Jarファイルを作る、本番Hiveに入れる... 結構時間がかかりそうですね。
このような場合、Rubyスクリプティング機能rb_execを使うと、数分でクエリを書き終えることができます!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
set rb.script = require "ipaddr" @docomo_ips = %Q[ 1.66.96.0/21 1.66.104.0/23 1.72.0.0/21 <ul> <li> 一部省略... </li> </ul> 183.75.128.0/18 ].split("n").map{|ip| IPAddr.new ip} def is_docomo_ip(ip_str) ip = IPAddr.new ip_str @docomo_ips.detect { |i| i.include? ip } ? "true" : "false" end ; select access_date, count(distinct user_id) from access where access_date >= "20130901" and user_agent like '%iPhone%' and rb_exec('is_docomo_ip', ipaddr) = 'true' group by access_date ; |
ご覧のとおり、is_docomo_ipというメソッドをRubyで定義し、クエリにNTTドコモのIPアドレスであるかの判断に使います。is_docomo_ipメソッドの中には、NTTドコモのスマートフォンIP範囲リストをループし、IPAddrクラスを使って、渡されたIPアドレスはそれに入ったかどうかを判断します。もしIPアドレスがNTTドコモの範囲であればすぐにtrueを返す、もしなければfalseを返します。Rubyのdetectのおかげで、一行で処理を書けました。
これを使って、グリーのあるサービスの9月から10月末までのアクセスログに対して集計してみます。発売日の9月20日からアクセスが順調に増加していることがわかりました!rb_execを使って、稀なAd Hocクエリも楽に書けるようになりました。
実装
Hiveの中で、Rubyスクリプトを処理できるのはJRubyのお陰です。
なぜPythonやScalaとかではなく、Rubyにしたかというと、
主流なJVM言語の中に、性能面と書きやすさ(勉強コストも)のバランスから考えると、やはり現時点ではRubyが一番いいのではないかと思うからです。個人的に、RubyのEnumerableクラスのメソッド群は大好きです。HiveのArray型かMap型のデータに対してeachやfindやmapなどRubyのEnumerableクラスのメソッドを使って処理をするのはかっこいいと思いませんか?
JavaからJRubyを呼び出すにはRed Bridgeを使っています。さらに性能をより向上するために、JRubyのsharing variables機能を禁止しています。Rubyで定義したスクリプトとその中のメソッドはより効率がいいparse once, call many timesな方法にしました。
rb_execの実装を簡単に説明すると、以下の流れになります。
- GenericUDFを拡張
- UDFの初期化の時にJRubyのContainerと実行コンテキストの準備を行う
- UDFの実処理をするevaluate関数の中に
- 指名されたJRubyメソッドの名前と引数たちをHiveからもらって、型変換などをする
- 引数たちを指名されたJRubyのメソッドに渡し、実行させる
- JRubyメソッドの返り値をevaluateの結果としてHiveに返す
Hive 0.11.0版から、GenericUDFは初期化の段階に一回Mapredジョブのコンテキストにアクセスするチャンスが追加されました。(詳細はこちら JIRA:HIVE-1016) それによって、Hive Sessionにset文を使って定義したRubyスクリプトはUDFの中でもアクセスすることができるようになりました。一方、その前のバージョン(hive-0.10.0-cdh4.4.0など)では、Rubyスクリプトをset文で事前に定義するのではなくて、rb_exec関数の引数の一つとして渡さなければなりません。
最後にもう一つの課題があります。どうやってRubyメソッドの結果の型をHiveに伝えるか、という点です。
GenericUDFを定義する時、初期化の時にUDFの結果の型(ObjectInspector)をHiveに伝える必要があります。下記のinitializeという関数のことです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
/** <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_0"> Initialize this GenericUDF. This will be called once and only once per </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_1"> GenericUDF instance. </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_2"> </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_3"> @param arguments </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_4"> The ObjectInspector for the arguments </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_5"> @throws UDFArgumentException </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_6"> Thrown when arguments have wrong types, wrong length, etc. </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_7"> @return The ObjectInspector for the return value </h3> <h3 id="hs_5b00fb0968b39bbcdd877b498d76a482_header_8">/ </h3> public abstract ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException; |
しかし、Rubyは動的言語なので、スクリプトからメソッドの返す型を自動判断するのは困難です。その解決方法として、返り値を常にStringとして返すことも考えられます。(実際、HiveのNativeなreflect関数は0.11版以前はずっと結果をStringにしてから返すようでした) ただし、Hiveの配列データに対してRubyのmapメソッドで変換しながら、結果は配列ではなくStringに変換されてしまうと残念です(笑)。
最終的にユーザーがUDFの結果の型のヒントをHiveに教えるという実装にしました。デフォルトの場合は自動的にStringを返すことにし、それ以外の場合は、結果と同じ型の値を一番目の引数に入れて、Hiveにヒントとして伝えることにしました。例えばMap<String,String>型の結果であれば:
rb_exec(Map('k','v'), 'gen_map', args...)
という記述になります。HiveのMap定義関数を使って、一つキーバリューペアしかいないMapを作ってrb_execに渡せば、rb_execはUDFの返り値の型もそれと同じのMap<String, String>であるのを認識してくれます。問題解決!
UDAFもRubyスクリプティング
Hiveでは、一般的なUDFの他、UDAF(user defined aggregate function)というもう一種類のよく使われている関数があります。countやsumなどのような複数の行入力から一行の結果を算出する関数のことです。Rubyスクリプティング機能を一般的なUDFだけではなく、UDAFにも利用できるようにしました。それがrb_injectという関数です。( ただし、UDAFの処理には行入力に対する処理と部分的な結果をマージする処理などいくつかの段階がありますので、Rubyスクリプティング機能の実装もUDFより複雑になっていますが、今回はそれに関する話をスキップさせていただきます。)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<ul> <li> sum UDAF implemented w/ rb_inject</li> </ul> set rb.script = def sum(memo, arg) memo + arg end ; select user_id, rb_inject('sum', coin) as coin_all from user_coin group by user_id ; |
ご覧の通り、Rubyのinject関数と非常に似ています。まずRubyスクリプトの中に、sumというメソッドを定義します。memoに現在の要素を加えて返す単純な加算です。memoは前回の戻り値か初期値です。 そのあと、クエリの中に、rb_inject UDAFに呼びたいRubyメソッドとメソッドに渡したい引数を渡します。ここではcoinというカラムです。これでHiveのnativeなsum関数と同じ集約処理をRubyでも定義できました。実際、配列のunionやintersectionとか、group byしたあとのサンプリングとか、rb_injectを使ってAd Hocな集約処理も非常に便利に書けるようになります。
パフォーマンス
Rubyで書く処理の性能はどうでしょうか、おそらく多くの方がJavaで実装されたnativeなUDFと比べると遅くなるだろうと想像するはずです。それはその通りです。基本的にはnativeなHive関数より処理時間がかかっています。JRuby自身の性能の関係もありますし、HadoopのWritable ObjectとJavaの標準なObject、JRubyのObjectの間の型変換にはかなりなオーバーヘッドがあります。一方、Hiveジョブの多くはI/Oバウンドな処理なので、性能への影響は大きくないかもしれません。軽く比較テストを行ったので、その結果を紹介します。
テスト用のMapreduceタスクのJVM(v1.7.0_25)設定は以下の通りです:
- -server
- -Xmx1500m
- -XX:+UseParallelOldGC
- -Djruby.compile.invokedynamic=true
- -Dfile.encoding=UTF-8
- -XX:+AggressiveOpts
- -XX:+UnlockDiagnosticVMOptions
- -XX:+UnlockExperimentalVMOptions
- -Djruby.compile.invokedynamic=true
- -Djruby.ji.objectProxyCache=false
いくつか種類のクエリをそれぞれNativeなUDFとrb_execで実行し、3回の中から最も早かったケースの時間で比較すると:
| 数値計算 | 文字列処理 | JSON lookup | Arrayソート | |
|---|---|---|---|---|
| native UDF | 77s | 82s | 56s | 42s |
| rb_exec | 80s | 122s | 114s | 44s |
| 比較 | -3.9% | -48.8% | -103.6% | -4.7% |
あまり差がないシーンもありますが、悪いケースだと2倍くらいの処理時間となってしまってます。でも、書ける処理の柔軟性とのトレードオフとしては十分に受け入れられるレベルじゃないかと思います。実はRubyスクリプティングで実行するクエリは必ずnativeなUDFを使うクエリより遅くなるわけでもありません。例えば以下の二つクエリ:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
<ul> <li> 特に意味がないテスト専用クエリ </li> <li> use native UDF </li> </ul> select count(v) from ( select elapsed_time, abs(round( sin( log2( pi() * rand() * 2 * elapsed_time ) + elapsed_time ))) as v from access ) t; <ul> <li> use rb_exec </li> </ul> set rb = ' @r = Random.new def cal(x) Math.sin(Math.log2(<a href="#hs_5b00fb0968b39bbcdd877b498d76a482_footnote_1" id="hs_5b00fb0968b39bbcdd877b498d76a482_footnotelink_1" title="Math::PI * @r.rand * 2 * x ) + x ">*1</a>).round.abs end '; select count(v) from ( select elapsed_time, rb_exec('cal', elapsed_time) as v from log ) t; |
実際にこれを2億行くらいのテーブルに対して性能テストをしてみたところ、Rubyスクリプティングのほうが早いという結果になりました!rb_execのほうは74秒で完了しましたが、native UDFのほうは92秒かかってしまいました。理由は、おそらくnativeの演算にはUDFを使い過ぎで、UDFの呼び出しにかなりなオーバーヘッドが発生してしまうのではないかと考えています。
まとめ
Apache HiveにRubyスクリプティング機能を追加したことを紹介させて頂きました。これによって、Hiveクエリの表現力と柔軟性は大幅に向上できました。なお、完全にnativeな関数の代わりにするつもりはないですが、以下のいくつかのシーンでは活用できると思っています。
- Ad Hocなクエリ
- ラピッドプロトタイピング
- Hiveのcomplex型データに対する処理
- Rubyのライブラリを活用
明日は、勝又 健太さん!!このブログでも使っているWordPressの冗長構成についてのお話です!!!!
Yuyang Lan、編集:橋本泰一
*1: Math::PI * @r.rand * 2 * x ) + x