OpenStack Swiftによる画像ストレージの運用
こんにちは。インフラストラクチャ本部の竹辺です。このエントリはGREE Advent Calendar 2014 4日目の記事です。
GREEのSNSでは、ユーザのみなさまが投稿した画像を保存するためのストレージを運用しています。2年ほど前から、この画像のストレージにOpenStack Swift(以下Swift)を使い始めました。その後、既存のストレージからのデータ移行やユーザのみなさまからの投稿などにより、現在では9億ファイルを超える画像が格納されています。
日本最大のメッセージングサービスでは一日の130億件のメッセージがやりとりされているという時代に9億などというとププッと笑われてしまうかもしれませんが、Swiftに大量の画像ファイルを格納するにはいくつかの性能上の問題を解決する必要があり、9億ファイルを格納するのもそれほど簡単ではありませんでした。この記事では、弊社の画像ストレージの運用で発生した性能問題とその原因の分析、回避策を説明いたします。
なおこの記事はある程度Swiftをご存知の方を対象に書いています。Swiftって何? という方はOpenStackのサイトや後述のSwiftStackのサイト等をご覧になってからの方が理解しやすいかもしれません。
Swiftの性能問題と原因分析
一番の問題は、連続してファイルを書き込んでいくと、格納されているファイル数が増えるにつれて書き込みが遅くなるということです。以下のグラフは、ある設定のクラスタに3400万ファイルが格納されている状態から、さらに約4000万ファイルを連続して書き込んだときのスループットを示しています。
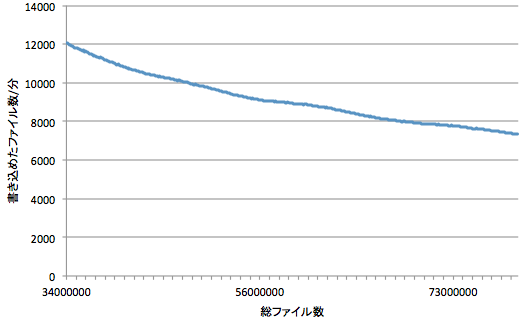
※実際のスループットはこのようになめらかなものにはなりません。このグラフは分かりやすさのため移動平均をとって平滑化しています。
3400万ファイルから7500万ファイルへとファイル数が約2倍に増加しただけでスループットがほぼ2/3に低下しており、どこかでファイル数に比例する処理がおこなわれているかのように見えます。なぜこのような現象が起きるのかを把握するためには、Swiftのレプリケーションの仕組みを理解しておく必要があります。分かりやすい図がSwiftStackのWebサイトにあったので引用します。
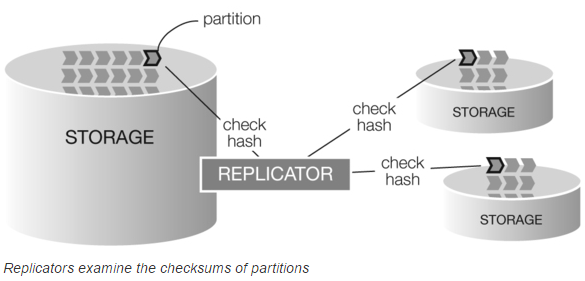
出典: https://www.swiftstack.com/openstack-swift/architecture/
Swiftでは各ファイルはパス名から計算したハッシュ値をもとに特定のパーティションに割り当てられます。各パーティションには3つのレプリカがあり、レプリケータはバックグラウンドでそれらの同期を取り続けています。レプリケータには3種類ありますが、ここで重要なのはファイルの同期を取るobject-replicatorです。常に全ファイルの同期を取り続けていては大変な負荷がかかりますので、object-replicatorはパーティション内のファイルのチェックサム(以下ではパーティションのハッシュ値と書きます)を調べ、それらが異なっている場合のみrsyncによりファイルの同期を取るという仕組みになっています。
ここで気になるのが、パーティションのハッシュ値とは具体的にはどのように計算される値なのかということです。ファイルを書き込んだり削除するときにパーティションのハッシュ値も更新する必要がありますが、その計算に同じパーティションの他の全部のファイルの情報が必要になるようなことがあれば、書き込み時間がO(n)であるかのようなふるまいをすることの説明がつくように思えます。ググっても何を計算しているのかよくわからなかったのでソースコードを読んでみることにします。
まずファイルの書き込みの方から見ていきます。PUTのハンドラから追っていくと、特にパーティションのハッシュ値を更新している処理はなさそうで、最終的にDiskFileクラスのputというメソッドが呼ばれています。このメソッドの中でinvalidate_hashという関数が呼ばれています。
https://github.com/openstack/swift/blob/.../swift/obj/server.py#L617
https://github.com/openstack/swift/blob/.../swift/obj/server.py#L705
https://github.com/openstack/swift/blob/.../swift/obj/server.py#L313
この関数は名前の通りで、このパーティションのハッシュ値をhashes.pklというファイルから読み込んで書き込まれたファイルに対応する個所をNoneに設定しhashes.pklに書き戻しているだけです。ファイルの書き込み時にはパーティションのハッシュ値は無効になりますが、再計算の処理が走ることはないようです。
https://github.com/openstack/swift/blob/.../swift/obj/replicator.py#L157
ちなみにこのhashes.pklは、ハッシュ値が全て有効な場合には150KB程度のサイズになります。これは、各パーティションは4096個のサブディレクトリに分割されており、それぞれについて32バイトの文字列表現のMD5ハッシュ値を格納するためです。NASAの支援を受けておきながら、ファイルを一つ書き込むたびに150KBのファイルを読み込み一部変更し書き戻すという設計はいかがなものかという気もしますが、O(1)であることは確かです。
ファイルの書き込み時にはパーティションのハッシュ値を無効化する処理だけということは、再計算自体はバックグラウンドプロセスでやられていそうです。ということで今度はobject-replicatorの方を見ていきます。
object-replicatorのget_hashesという関数でhashes.pklの読み込みがおこなわれていますが、ここで無効なものがあればhash_suffixという関数を呼んでいます。これが再計算をする関数のようです。
https://github.com/openstack/swift/blob/.../swift/obj/replicator.py#L161
https://github.com/openstack/swift/blob/.../swift/obj/replicator.py#L197
何をしているかというと、パーティションのディレクトリ以下にあるファイルの一覧を取得し、全てのファイル名のMD5ダイジェストを取っているようです。ファイルの中身は見ておらず、ファイルの名前だけを見ています。
https://github.com/openstack/swift/blob/.../swift/obj/replicator.py#L84
https://github.com/openstack/swift/blob/.../swift/obj/replicator.py#L92
Swiftのパーティションの数は一定ですので、パーティションあたりのファイルの数は全ファイル数に比例します。実際には計算というよりはファイル一覧取得のI/O負荷が大きいですが、この処理は全ファイル数に比例して時間がかかる処理になります。
ところで、get_hashesを呼びだしているのはバックグラウンドプロセスのobject-replicatorだけではありません。object-replicatorはパーティションの他のレプリカがあるサーバにREPLICATEというコマンドを投げて他のレプリカのハッシュ値を問い合わせるようになっており、これを受け取るのはobject-serverです。重いハッシュ値再計算の処理が、ユーザからのリクエストを処理するのと同じプロセスでも走るという設計になっています。
https://github.com/openstack/swift/blob/.../swift/obj/server.py#L908
object-serverではどのリクエストの処理でもスレッドプール等のリソースが共有されています。ファイル数が増えるにつれて、バックグラウンドプロセスが遅れていくだけではなく、書き込みのスループットも落ちてしまうというのはこのあたりに原因があるようです。
まとめると以下のことが分かります:
- ファイルの書き込み処理はhashes.pklに書かれているパーティションのハッシュ値を無効にするだけなのでO(1)
- object-replicatorはパーティションのハッシュ値が無効であればディレクトリ一覧を取ってきてファイル名のハッシュ値を計算する。この処理はO(n)
- object-replicatorが投げたREPLICATEコマンドを受け取ったサーバでもパーティションのハッシュ値が無効であればディレクトリ一覧の取得とハッシュ値再計算がおこなわれる。この処理もO(n)
ファイルの書き込み処理自体はファイル数に依存しないということが分かりましたので、バックグラウンドプロセスであるobject-replicatorの実行頻度を下げてやればスループットが改善できそうです。前述の7500万ファイルのクラスタでもobject-replicatorを一時的に停止することでスループットを回復することができました。
運用による回避策
ここからは、画像ストレージのSwiftクラスタで上記のような問題を解決するためにおこなっている運用上の回避策と、実際にはおこなっていませんが有効と思われるアイデアをいくつか紹介します。
object-replicatorを停止する
既存のストレージからのデータ移行のように大量に書き込みを続ける場合には、一時的にobject-replicatorを停止するというのが有効です。これにより、格納されているファイル数が増えてもそれほどスループットの低下なくデータを移行することができます。その代わり、object-replicatorを再開した時に全部のパーティションのハッシュ値の再計算をおこなうのには 書き込みが発生したパーティション x ファイル数 に比例して時間がかかるようになります。データ移行中にディスク障害やネットワーク障害が発生した場合に、復旧により長い時間がかかってしまうので、こうした障害が頻繁に発生するようなクラスタの場合は注意が必要かもしれません。グリーの構成ではハードウェアの信頼性が高くディスク障害の頻度が低いのと、9億ファイルであれば2週間程度でobject-replicatorが全パーティションの再計算をおこなえるため、現在のところ既存のストレージからのデータ移行時にはobject-replicatorを停止するようにしています。
object-replicatorとobject-auditorのI/O優先度を下げる
以下のような簡単なスクリプトを走らせてobject-replicatorとobject-auditorのI/O優先度を下げています。
|
1 2 3 4 5 6 7 8 9 10 11 |
#!/bin/bash for i in `ps aux | grep swift-object-replicator | grep -v grep | awk '{print $2}'` ; do sudo ionice -c3 -p $i sudo ionice -p $i done for i in `ps aux | grep swift-object-auditor | grep -v grep | awk '{print $2}'` ; do sudo ionice -c3 -p $i sudo ionice -p $i done |
前節で説明したようにREPLICATEコマンドはobject-serverが実行するため、パーティションのハッシュ値計算にともなう全てのI/Oの優先度を下げることはできませんが、object-replicatorのI/O優先度を下げるだけでも多少は改善が期待できます。
object-auditorは上記の性能問題とは直接関係ありませんが、このプロセスもバックグラウンドでファイルをreadし続けますのでI/O優先度を下げておいた方が無難でしょう。
リングファイル生成時にパーティション数を大きめに設定する
一般的なSwiftの運用ではパーティション数はディスクの本数の100倍程度にするのがよいとされています。これは主に各ディスクに割り当てられるパーティション数のバランスを考慮したもので、各ディスクにだいたい100個のパーティションが割り当たれば、ディスクあたりのパーティション数の差が1%以下におさえられるからというのがその根拠です。
しかし、画像ファイルのように小さいファイルを大量に格納する場合にはディスクの本数もそれほど多くは必要ないので、このガイドラインにそって設定してしまうとパーティション数が少なくなりすぎ、パーティションあたりのファイル数が多くなってしまいます。グリーの画像ストレージでは、当初の見積もりを元にパーティション数を 2^13 = 8192 に設定していますが、パーティションあたりのファイル数を考えるとこれは少なすぎたかもしれません。ファイル数が多い用途の場合はこの値はガイドラインよりも大きめに設定しておいた方がよいように思います。あまり大きくするとSwiftプロセスのメモリ使用量が増えたりレプリケーションに時間がかかるなどの問題が起こるようですが、2^17程度のパーティション数であれば少ないディスク本数で運用しても特に害はなさそうです。
値の目安ですが、各パーティションは4096個のサブディレクトリに分割されますので、格納したいファイル数 / 4096 よりも大きな値にしても効果はなさそうです。10億ファイルでしたら 10億 / 4096 = 244140 なので 2^17 = 131072 で十分でしょう。
コンテナあたりのファイル数を制限する
これまでに説明した問題とは別に、Swiftでは1つのコンテナに入っているファイルの一覧が1つのSQLiteファイルに格納されているという問題もあります。このため、目安としては1つのコンテナに100万個以上のファイルを格納するとSQLiteファイルのサイズの増大により性能が劣化すると言われています。グリーでの運用では、画像ファイルを1000個のコンテナにシャーディングして格納し、今のところ1つのコンテナあたりのファイル数が100万個程度になるように運用しています。
書き込み/読み込みキャッシュを設ける
グリーの画像ストレージでは、ゲームでのイベント等により一時的に大量の画像の書き込みが発生する場合があるため、ユーザのみなさまが投稿したファイルを直接Swiftに書き込むのではなく、Flareという自社製のKVSにまずキャッシュするようにしています。このためにHTTPのリクエストをFlareのmemcachedプロトコルに変換するゲートウェイサーバをHaskellで開発しています。読み込み側に関してもVarnishを使ってキャッシュしています。
ファイルの書き込みをパーティション順にする
画像ストレージのように毎日少しずつファイルが増え続けるような用途では使いづらいですが、空のSwiftクラスタに大量に既存のデータを移行するときなどには有効と思われる方法です。
swiftコマンドで普通にファイルをアップロードすると、ファイルのパス名の順番で書き込まれるため、ランダムなパーティションに書き込みがおこなわれます。このため、同じパーティションのファイルがディスク上の離れた場所に書き込まれ、パーティションのハッシュ値計算時のディレクトリ一覧の取得に時間がかかる原因にもなってしまいます。Swiftにアップロードしたいファイルのパス名が分かっている場合には、これらのファイルが格納されるパーティションをあらかじめ計算しておき、同じパーティションに入るファイルをまとめてアップロードすれば、ディスク上の近い位置に書き込まれるため、ディレクトリ一覧取得時のI/O負荷を低減することが期待できます。
参考までにサーバ3台の規模が小さいクラスタで簡単な実験をしたので以下に示します。
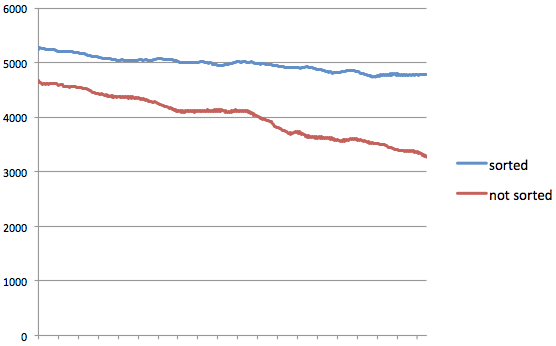
ソート時と未ソート時のスループット
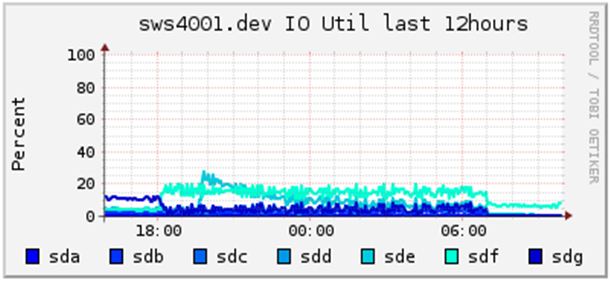
ソートせずにアップロードしたときのI/O util

ソートしてアップロードしたときのI/O util
パーティション順にソートして書き込んだものとパス名順に書き込んだものとを比較すると、明らかにパーティション順にソートしたものの方が高速にファイルを書き込むことができ、ディスクのI/O utilも低くなっています。
注意点としては、ディスクの本数が多い実際のクラスタに書き込む場合には、完全にパーティション順にソートしてしまうと同じディスクばかりに書き込みがおこなわれるため、並列度を上げてもディスクI/Oがボトルネックになりスループットが上がらなくなってしまいます。別のディスクに配置されているのであれば別のパーティションであっても同時に書き込むようにソートした方がよいでしょう。
まとめ
この記事では、画像ストレージの運用の際に筆者が経験したSwiftの問題点を主に取り上げることになってしまいましたが、Swiftは、システム構成がシンプルでありSPOFもなく、ノード追加で簡単に容量が増やせるなど、運用の容易さや可用性、拡張性の面では優れたストレージです。画像ファイルのような小さいファイルを大量に格納するという用途に最適に設計されているとは言えませんが、仕組みが単純であるため、問題点を理解してしまえばかなりの部分は運用で回避することも可能です。みなさんもSwiftを使って130億ファイルの画像ストレージの構築に挑戦してみてはいかがでしょうか。
明日はがらっと話を変えて、インフラストラクチャ本部の山田さんによる3Dモデリングツールの紹介です。お楽しみに!