A year of using Presto in production
I'm Yuyang Lan @ Data Infrastructure team.
Here is the 14th entry of GREE Advent Calendar 2014.
Please enjoy it!
Presto (distributed SQL query engine for Big Data open sourced by Facebook) has already been used in GREE's production environment for more than 1 year, and is now an indispensable part to our Big Data toolbox.
In this article, I will present you how we use presto and hope that would be helpful for you.
Why Presto
One of the most frequent questions to ask when you see someone using a Big Data SQL tool must be "Why this, but not others like Impala, Hive on Tez, Apache Drill, BigQuery, Redshift, ...". My answer for it may be pretty "official": they're all great tools, just choose the one that suitable for you.
Here in GREE, we manage our own data center infrastructure, and have developed an on-premise Hadoop cluster. So cloud services like BigQuery or Redshift are not optional for us at the present stage, while our US branch, in where all servers are AWS-based, has actually employed Redshift for data warehouse solution(For detail).
For Impala, we've tried it before Presto. We encountered some crashes caused by memory problem, but the performance was impressive. Which actually made us decide to keep on looking up is the opacity of its development and the difficulty to apply customization or contribution.
We haven’t got time to test Hive on Tez yet. But in GREE, Hive is the essential part of our data pipeline and has been heavily used in ELT & analytical workflows, so we would rather value the stability and matureness of the traditional Hive at the present stage.
Another choice, Spark SQL, still in its early phase and seems immature for enterprise usage. But its foundation, Spark, is actually being used in our production environment for training user model and building recommendation. We extremely value Spark's interactive shell for quick prototyping, and its in-memory computing ability, which is a perfect match for Machine Learning scenario.
On the other hand, from the very beginning, Presto showed us to be a solid choice. Not only because its outstanding performance comparing to Hive, but also its Java stack and its well designed architecture that allow us to customize it for better integration.
System overview
Like almost all other systems in GREE, the Presto system is built inside our own data center. Here's a picture illustrating how it looks like:
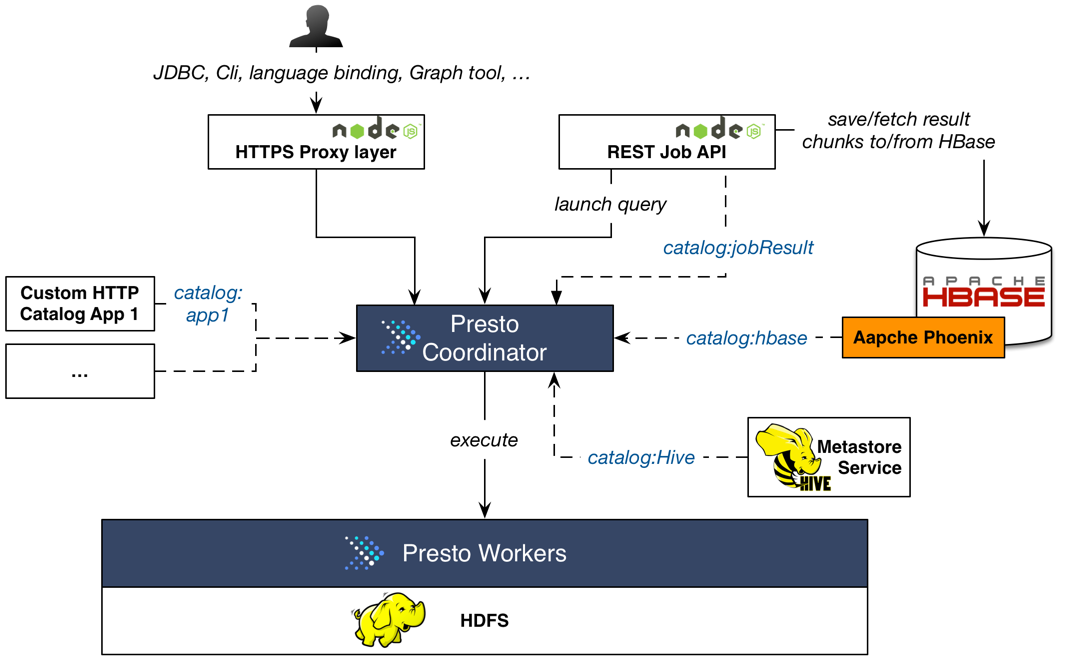
As I’ve mentioned before, we already have an on-premise Hadoop cluster consists of dozens of servers and Hive is our essential tool for ETL and data pipelines. So we setup-ed Presto in all datanodes with a fixed amount of resource assigned, in aim to make the most of leveraging data locality and maximizing the resource usage of servers. Every day, there're ~ 1k queries issued by internal users to query across hundreds of TBs of data in Hadoop, and 85% of them got completed in less than 10 seconds.
The presto service stays behind a proxy layer(Node.js), which provides HTTPS encryption, Authentication-check as well as basic query check. We encourage our internal users to use presto instead of Hive for interactive/Ad-hoc analysis. Users connect to Presto from office by using JDBC or Cli, or 3rd-party libraries. Not only the same data set managed by Hive can be queries through Presto, but also data hold in other systems like HBase or 3rd-party Cloud service is query-able by leveraging our custom connectors (will be described later). Moreover, internal applications that need to access huge data set in a low latency fashion are also welcomed to use Presto. The text tool described in our previous blog post is such an example.
The evolution over the past year
Although now we're quite satisfied with our Presto system, it doesn’t mean that our time with Presto were always trouble free.
There used to be many limitations for using Presto. For example, count(distinct col) expression wasn't support before, as well as some other useful stuff like cross join, views, create tables, UDTF function and distribution join. Moreover, complex data type in Hive like Array/Map/Struct were presented as JSON string in Presto, and could only be accessed by using JSON functions. We had to spend extra time to explain to users (most of whom used Hive before) that what they can't do with presto currently and how to get a work around.
Thanks to the hard work of Presto team & its contributors, new releases with solid fixes and new features are being shipped frequently (usually every 1 or 2 weeks). All of the missing features I mentioned above have been implemented during the past year (yes, even distribution join).
At the meantime, we're also keeping tuning & solving issues in our own deployment of Presto. We were once suffering from a socket input buffer leak problem, which happened frequently especially when huge query was executed. Unlike in MapReduce, that task JVM will end up its lifetime and clean up everything after finishing a fixed number of tasks, Presto processes run as daemons, so the leaked memory in socket buffer will keep increasing and finally cause the server to freeze. We had no choice but to restart Presto process manually whenever we found there’s accumulated considerable leaked memory. Fortunately, later after some debug work, we finally figured out the leak is caused by bug inside DFSClient and fixed it (the same one in HDFS-5671).
Customization for better integration
As I have mentioned before, one important reason we chose Presto is because its Java stack and well-designed structure, which enable us to apply customization and improvement more easily. In this section, I will describe some of our work on Presto in order to better integrate it with our existing systems and meet our needs in GREE.
Authentication, HTTPS & Access Restrictions
It's simple but a necessary for enterprise usage, where user usually connect to Presto from office network directly, and table access permission need to be managed based on role system or something similar. Also, it's worth to add limitation for maximum allowed partitions in a single query for huge tables, since Presto's performance regresses when processing extremely huge data set, which is often unintended by query author.
Implicit conversion of data type
Hive provides implicit conversion on data types, which we found very handy. Especially in our environment, for some legacy reasons, there’re tables with columns that stand for the same thing but defined as different data types (e.g., column "date" may be varchar here in this table but bigint in another one). Presto has a much more strict type system, so it's not uncommon for our users to run into wrong data type errors. To solve this, we implemented basic implicit conversion for comparison expression in WHERE and JOIN clauses.
New Functions
Presto provides a sufficient set of box-of-the-box functions that there's few chances for us to build new function just because the lack of functionality. Our development of new functions is actually driven by the following requirements.
- To keep compatible with Hive
There’re functions that our user rely on heavily in Hive. So we would like to just provide the same set of functions in Presto for reducing the learning cost as well as the cost for migrating existing Hive SQL. - To boost performance
Sometimes query performance is bound to some key functions, and optimizing such functions can improve query time dramatically. For example, our custom JSON extract function json_get (which employs Alibaba's fastjson for deserialization) provides 4~6x performance boost comparing to the original json_extract/json_extract_scalar functions in Presto.
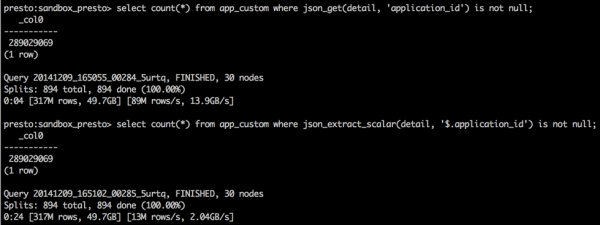
- To keep backward compatibility
Sometimes new release of Presto came with backward incompatible (but necessary) features. Like migrating Array/Map data type from JSON encoded string back to their real types in 0.78 release. To ensure our users’ existing queries won’t break after the version up, we overloaded the most important JSON functions to let it support both Varchar(JSON encoded string) and JSON/Array/Map data types at the same time.
Better scheduling
Scheduling is one of the most important factors to Presto's performance. Bad scheduling will cause inefficient data transfer and unfair resource assignment. Besides carefully tuned the relative configurations, we’ve applied some customization work to help achieve better scheduling, including Hadoop-like script-based rack awareness mechanism (by default, Presto use the first 3 numbers in node's IP address to detect which rack it belongs, but unfortunately it's not suitable for us), per user query queue, and so on.
More verbose error messages
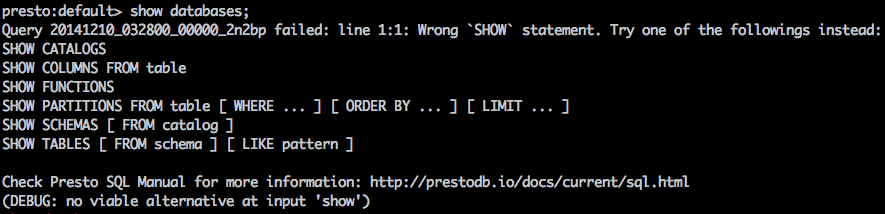
Presto use ANSI SQL, which is quite different comparing to Hive QL. It’s common for beginners to run into SQL error when they tried to write SQL like 'show databases' which is common in Hive or MySQL. So we did some work to catch SQL parsing errors inside Presto and inject additional guide for most common mistakes. Here's is an example:
Custom connector
Another key feature of Presto is that users can build custom connector to integrate new data source other than Hive. During the past year, there're great connectors being added into Presto including connectors for Cassandra, MySQL, Kafka and so on. Here I want to share three custom connectors we built inside GREE and found very useful.
Phoenix
In GREE, we have a small HBase cluster, which holds data and metrics for OLAP. When we introduced Presto, we started to look for a way to integrate Presto with HBase. The solution we found is to leverage Apache Phoenix (relational database layer over HBase). Phoenix helps to create relational schemas against existing HBase tables. By building a custom connector talks to Phoenix through its JDBC interface, we are able to query HBase data directly from Presto. Furthermore, the range predicate pushdown feature works perfectly, as it pushes down the expressions specified in WHERE clause into Phoenix, and Phoenix translates them into native HBase API calls, thus only the minimum chunk of data will be fetched back to Presto workers.
Jobresult
Another way that we use HBase in GREE is to store query results from the Job API (as you can see in the system structure above). The Job API is a set of easy-use HTTP APIs that allow even more convenient way to issue queries against our big data infrastructure. There’re plugins inside GREE to enable interactive queries from Microsoft Excel or Atom by using the Job API. Query result will be split into chunks and saved into HBase with its schema for later reference. We noticed that sometimes it would be convenient and efficient if we can iteratively explorer the result of previous queries (kind like how we use Spark's interactive shell), so we built another custom connector to exposure the result data inside HBase as tables inside catalog jobresult. Thus, interactive analysis through our Job API can refer to any previous result set. Here's an simple example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
-- extract the date and time cost of Presto queries in November, 2014 select date_trunc('day', starttime) as dt, date_diff('second', starttime, endtime) as timecost from hbase.default.query_log where id between '20141101' and '20141201' and type = 'presto' and state = 'success' and lower(query) like '%select%' and ... ; -- return with job_id = 20141210_172019_d7f9438fd0 -- then let's run analytic queries against the result set -- average query time select avg(timecost) from jobresult.default."20141210_172019_d7f9438fd0"; -- count and average time per day select dt, count(*), avg(timecost) from jobresult.default."20141210_172019_d7f9438fd0" group by dt order by dt; -- how much time do 90% queries cost select approx_percentile(timecost, 0.9) from jobresult.default."20141210_172019_d7f9438fd0" ; -- ... |
General_HTTP
Besides data in Hive and HBase, there're still many miscellaneous data pieces that we want to bring into our enterprise data hub, some may stored inside Apache Solr, some as CSV files uploaded by users, some may in Google Drive, and some may even be hard coded inside a PHP script. Rather than dumping all of such things into Hadoop (which is what we used to do) or building new Presto connectors for each of them, it would be much easier for us to create a general purpose HTTP connector in Presto, which fetches catalog meta and data splits from remote web applications, and leaving the work of parsing & assembling the original data to the implementation side. This approach is very same to Presto's own example-http connector. Here's a typical catalog definition for exposuring information defined inside PHP script as tables.
|
1 2 3 4 |
## etc/catalog/php.properties connector.name=general_http hosts=example.php.domain:port path=data_to_presto/v1 |
Then all we need is to let data provider implements the necessary HTTP endpoints (e.g., GET /data_to_presto /v1/schemas, GET /data_to_presto/v1/data/${SCHEMA}/${TABLE}/split?id=1, ..) in preferred language & environment (although in the example above we probably have to choose PHP). By doing so, we can gather data pieces to a universal access interface and even staff that has no idea about the internal of Presto or Java can build plugin data set.
Summary
The performance boost provided by Presto has much improved our efficiency in using and analyzing data, which is critical in gaining better insights and building better products. Moreover, the ease of customization & integrating with new data source has resulted a much more robust and scalable (in both capacity and diversity) enterprise data infrastructure.
We’ve started to contribute our customization work back to open source community.
Tomorrow's entry of Gree Advent Calendar 2014 will be
Goto-san's <初めてのHTTP/2サーバプッシュ>.
Please look forward to!