DynamoDBを使ったKPI保存システム
こんにちは!データエンジニアリングチームの長谷川と田畠です。
グリーのデータ分析基盤を良くする仕事をしています。
これはGREE Advent Calendar 2015の6日目の記事です。昨日のRobinさんの記事はVR開発に取り組んだことがあるからこそ書ける記事で、みなさんにとっても新鮮だったのではないでしょうか?
今日はゲームから少し離れて、KPIダッシュボードのバックエンドをオンプレミスからAWSに移行した話をしたいと思います。最後までお付き合いよろしくお願いします。
はじめに
KPI分析を定常的に行うことは、プロダクトの改善のために非常に重要であり、グリーにおいても多くのプロダクトがKPIを閲覧/分析するためのシステムを利用しています。
社内の分析環境では、KPIのデータは時系列データベースに保存されており、内製のグラフ描画ツールにアクセスすることでグラフとして閲覧することができます。今までは一部のKPIのデータをオンプレミス環境にあるOpenTSDBに保存していました。OpenTSDBはHBaseをストレージとしたOSSの時系列データベースで、大量の時系列データを保存することができます。既に内製グラフツールがあったため使用していませんでしたが、OpenTSDBはグラフを作成するインタフェースも提供しています。
しかし、今年の夏にHBaseが動いているサーバーを移設させる必要があり、それをきっかけにKPIのデータ保存先について見直すことにしました。
見直すことにした理由としては、
- OpenTSDBは高機能にも関わらず実際に使用している機能は少ない
- もともと初期検証用のHadoopクラスタを転用したため現在の用途にはサーバー台数が多く余計に費用がかかる
- 保存しているKPIのデータ量は大きくなく、移行先がしっかり用意できればデータの移行自体は実現可能な時間でおわる
OpenTSDBの環境をどうやって移行するか検討した結果、DynamoDBをバックエンドとしたKPI保存システムを作成することにしました。
もちろんDynamoDBではなく、RDBMSやNoSQL、他の時系列DBでも同じことは可能だと思いますが、フルマネージドなサービスを使用することによる運用コストの低さ、リソースのコントロールによるコストの最適化、開発チームのメンバーの熱意などを考慮して、上記の構成で新システムSouffle(スフレ)を作成することにしました。
実装前に考慮したこと
まず、内製グラフツールで表示されたKPIの例(図1, 図2)を用いて私たちが使用している用語の定義を説明します。
図1は日次のUUとPVをデバイス別で集計したデータを表しています。図2はデバイス別DAUを描画したグラフになります。これらはダミーデータから作成しています。
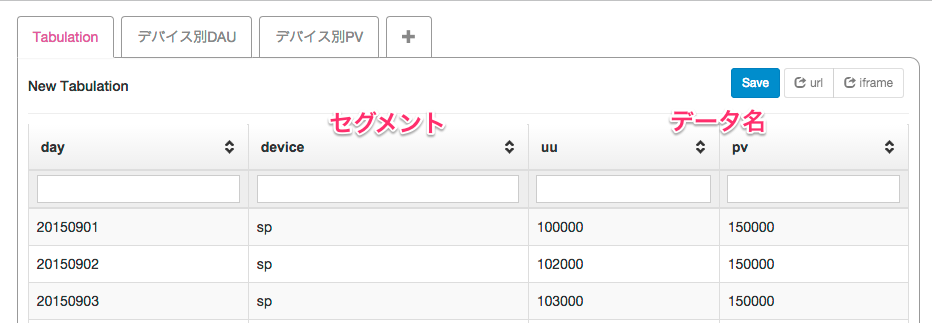
図1 データ表
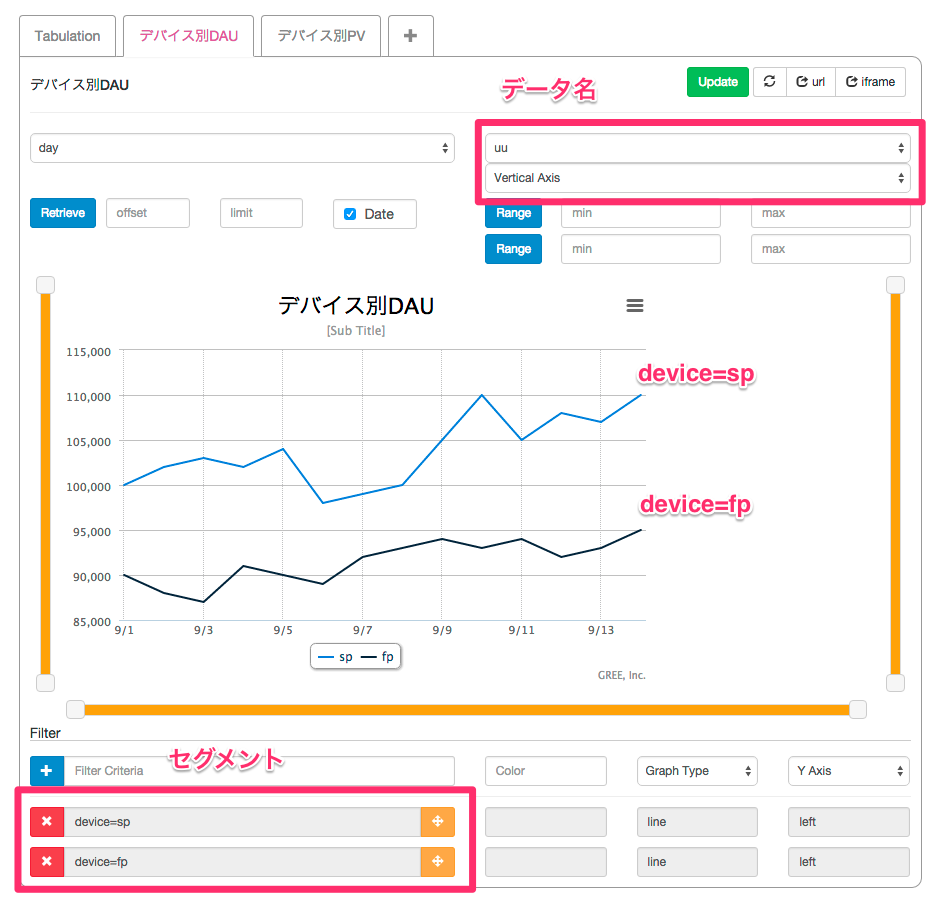
図2 内製グラフツールによる描画
- メトリック
- 1つの指標を指します。ここでは「デバイス別DAU 及び PV」に当たります。1メトリックから複数のグラフ(デバイス別DAU、デバイス別PV)を作成します。
- セグメント
- 指標における区分です。ここでは「device=fp」や「device=sp」に当たります。指定したセグメント毎に折れ線が描画されます。
- データ名
- 数値の名前です。ここでは「uu」と「pv」に当たります。
次に、Souffleを作成するにあたって、必須機能と今までOpenTSDBを利用してきて要望の多かった機能を洗い出しました。
必須機能
- データの保存
- 時系列でソートされたデータの取得
- 作成者に紐付いたメトリック一覧の取得
要望の多い機能
- メトリック名の変更
- メトリックの削除
- セグメント名の変更
- セグメントの追加
- データ名の追加
必須機能は言わずもがなですが、細かい機能も必要性を感じることが多く、OpenTSDBでは簡単にはカスタマイズできないため実現できなかった機能もあります。
例えば、メトリック名やセグメント名の変更をしたいケースとして、後日作成したデータが入っているかどうか確認した際にタイポを指摘されるようなケースがあります。そのような場合、一度入れたデータを消さずに黒歴史を葬り去らなければなりません。
他にも後になってから、「UUあたりの平均PV」を見たくなった場合は、「pv_per_uu」のような新しいデータ名を追加したいこともあります。
このような要望を考慮してDynamoDBのテーブルを設計しました。
基本的な方針としては、セグメントやデータ名などのメタデータを持つテーブルと、時系列データを持つテーブルで分けて考えました。メタデータ用のテーブルにはメトリック、セグメント、データ名を保存する3つのテーブルが含まれます。DynamoDBはrange keyというキーでテーブルをソートすることが可能であり、時系列データ用のテーブルは時刻をrange keyとして保存しています。
これらのメタデータの考え方はOpenTSDBの設計を参考にしながらも、HBase特有の行キーによって制約させていた面をより柔軟にしました。また、保存する時系列データのサイズが大きくなるとDynamoDBの消費unit数が増え費用がかさんでしまうため、なるべく小さくなるよう注意しながら設計しました。検討していた際には改めてOpenTSDBのキー設計の秀逸さを認識させられました。
もしOpenTSDBに興味が出た方はこちらの資料に設計について簡単に書いてあるので読んでみてください。
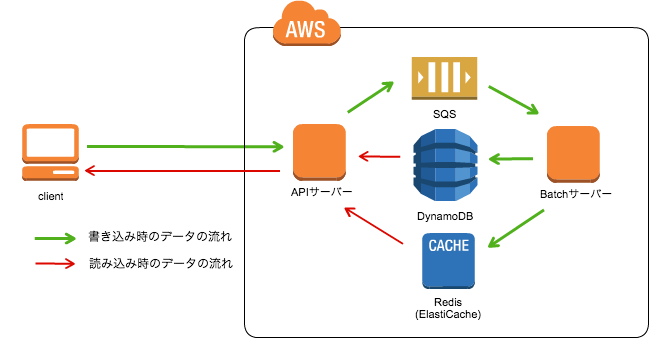
アーキテクチャ
AWS上のおおまかなサーバー構成は以下のようになります。

アプリケーションサーバーとして、APIサーバーとBatchサーバーを作成しました。APIサーバーは文字通りクライアントからリクエストを受け取ってデータを返す役割です。一方で、BatchサーバーはDynamoDBにWriteしなければならない処理を請け負います。
DynamoDBは良い意味でも悪い意味でも、設定したスループットによって課金されます。特にWriteの課金は同じデータサイズのReadの課金と比較してとても高価にもなります。そのため、なるべくWriteのスループット設定を抑える必要がありますが、その一方で、書き込みがスループットを超えてしまいデータをロストすることは防がなければなりません。
そこでSouffleのAPIサーバーは書き込み処理が必要なリクエストを受け取った場合、一度SQSにEnqueueし、BatchサーバーがそれをDequeueするという方式をとっています。SQSはメッセージをDequeueした後に明示的にDeleteしない限り再びDequeueすることができます。よって、一時的に書き込みが増えスループットを超えてしまっても再度入れ直すことが可能です。このときにデータの不整合が起きないように冪等性を心がけて実装をしました。さらに、このSQSがあるおかげで、新しいメトリックを作るときに過去分を一気に入れたいという要望があっても、クライアントは何も気を使うことがなく多数のリクエストを投げることができます。
また、DynamoDBのReadのスループットを低減するためにRedis (ElastiCache)を利用しています。今回のようなKPIのデータを保存するようなシステムでは、多くの場合直近60~90日が見れれば十分であり、過去の施策がどうだったか確認するときのみ過去の期間の数値を閲覧します。この性質を考慮し、SouffleではReadのスループットを抑えるために直近のデータをRedisに保存しています。よって、KPIの一覧ページを見るときでもほとんどDynamoDBにはアクセスがいかず、低いスループットに抑えることが可能であり、レスポンスの高速化にもつながります。
運用について
運用を始めてからは時間帯によってDynamoDBのスループットを変更しています。DynamoDBは1日に4回までスループットを下げることができるという特徴があります。
以下が大まかな1日の使われ方です。
4:00 ~ 8:00 日次バッチが走るためWriteが多い
9:00 ~ 20:00 指標の確認をするためReadが多い
21:00 ~ 大多数が退社するため、ReadもWriteも少ない
月初のみ特別扱いしてReadをあげていますが、他の日はだいたい同じ使われ方をするため、予測がしやすく効率的にDynamoDBを使うことができます。
ここはオンプレミスにある環境とは大きく異なる点であり、AWSの恩恵に預かることができました。
さらに、デプロイではCodeDeployを利用しており、新たにデプロイツールを作成せず、Jenkinsでビルドしたファイルを配るだけでリリースが終わるというフローになっています。CodeDeployは東京リージョンでは開始して間もないですが、導入もすぐにでき、今のところ問題なく動作していて非常に助かっています。
実装してみて
Souffleはサーバーの移行期限が決まっていたために、1ヶ月程度で作る必要がありましたが、ほぼ2~3週間程度で作ることが出来ました。
実装をした2人ともAWSのクライアントを使うのは初めてであり、SQS互換のElasticMQやDynamoDB互換のDynamoDBLocalの存在なくしてはなかなか難しかったと思います。
さらに、私たちが所属するデータエンジニアリングチームでは、昨年からSparkを利用しており、今後も更なる利用が見込まれるため、勉強も兼ねてScalaで実装をしました。フレームワークはSprayを利用しています。
弊社ではグリーチャットがScalaで実装されてから、利用事例も増えつつあり、他にもScalaで実装された内部システムもあります。
Souffleを実装する際には、事前にAWSで動くScalaプロダクトを作成したチームにヒアリングし、ノウハウの共有をしてもらいました。おかげで監視を含めAWSの準備をしてくれるインフラのチームともスムーズにコミュニケーションをとることができました。
まとめ
KPIを保存するシステムをHBaseをストレージとしたOpenTSDBから、DynamoDBをストレージとしたシステムに置き換えました。
オンプレミスからAWSに移ったことで運用コストを低減できるだけでなく、DynamoDBのスループットを調整することにより費用も抑えることができました。
余談ですが、実はre:Inventに参加させてもらっていたので、ここでAWSアピールできて良かったです:)
※※※
明日はテストエンジニアの山本さんの記事です。お楽しみに!