Schema.org を利用してユーザーに優しい検索結果を提供しよう
このエントリは GREE Advent Calendar 2015 の 3日目の記事です。
こんにちは!藤田(@tgfjt)です。
フロントエンドエンジニアやってます。
まだ全く年末気分でもクリスマス気分でもないので週末に飾り付けでもしたいです。
昨日は奥村さんの「 グリーの CSIRT “GREE-IRT” の歩み」 の記事でした。
「セキュリティ的に何か良からぬことが起きた時に駆り出される中の人たち」というところが強く…心に残っています。
さて突然ですが、皆さんはインターネットで何かを調べる時、どんな風に検索結果の表示をを見ていますか?
私の場合、例えば、表示されたタイトルやキャプションを見て、「このページが面白そうだ!役に立ちそうだ!」と思ったものをクリックして見に行くことが多いです。
しかし場合によっては、そのページが一体どんなWebサイトのどんなページなのか分からず、クリックをためらうことも時々あったりします。
情報化が進み、一つの単語から膨大な数のページを検索できるようになったからこそ、皆さんにもそんな経験はありませんか?
実は、検索結果に表示されるのはタイトルやキャプションだけではありません。
そんなの当たり前だ!と思われるかもしれませんが、一体どんな情報が表示されているか、ということを意識して見る機会はなかなか少ないのではないでしょうか。
最近、Webサイトがモバイルフレンドリーかどうかを判定して検索結果に反映し、「スマホ対応」と表示する対応を、Google が始めました。
これだけではなく、何かを検索した時にはタイトルや概要を始め、サイトのパンくず階層や評価の★マークのようなものまで、Webページの持つ情報が集約された結果 が一覧として表示されます。
逆に言えば、Webサイトの作り手側からすると、外部ユーザーに向けて一目見て分かりやすい検索結果を表示する、ことが可能です。
今回のテーマはずばりこれです。
具体的な話に入りましょう。
提供している情報をより簡潔に反映させるためには、
検索エンジン(クローラ)に対して情報を正しく詳しく伝えてあげる必要があります。
Schema.org を使った情報構造の表現
ちにみに、Schema.org とは?
Google、Microsoft(Bing)、Yahoo、そして、Yandex という検索エンジンベンダーたちが共同で定義している、検索エンジンに詳細な情報を伝達するための語彙の集まりです。
これらの語彙を利用し、構造化されたデータ (Structured Data) として情報をマークアップすることで、
検索エンジンに対して情報を正しく詳細に伝えられ、Webページの情報についてクローラーも認識しやすくなります。
つまり、検索結果表示を見る時にユーザーも認識しやすくなるということですね。
エンジニアの方々は、この語彙のひとつひとつを、Class のようなものだと考えると、親しみやすくなると思います。
では実際にその例を見てみましょう。
会社情報の構造化データ例
マークアップとして埋め込むにはいくつかの方式(microdata, JSON-LD 等)がありますが、
microdata を HTML に埋め込んでマークアップしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<section itemscope itemtype="http://schema.org/Corporation"> <h1 itemprop="name">リミア株式会社</h1> <link itemprop="url" href="http://limia.jp/"> <link itemprop="sameAs" href="https://www.facebook.com/limiajp"> <link itemprop="sameAs" href="https://twitter.com/limiajp"> <table> <tr> <th>設立</th> <td itemprop="foundingDate" datetime="2015-7-1">2015年7月1日</td> </tr> <tr> <th>本店所在地</th> <td itemprop="address" itemscope itemtype="http://schema.org/PostalAddress"> <span itemprop="addressRegion">東京都</span> <span itemprop="addressLocality">港区</span> <span itemprop="streetAddress">六本木6-10-1 六本木ヒルズ森タワー</span> </td> </tr> </table> </section> |
Google謹製の構造化データテストツール
という便利ツールがあるので、どう認識されるのかを確認してみましょう。
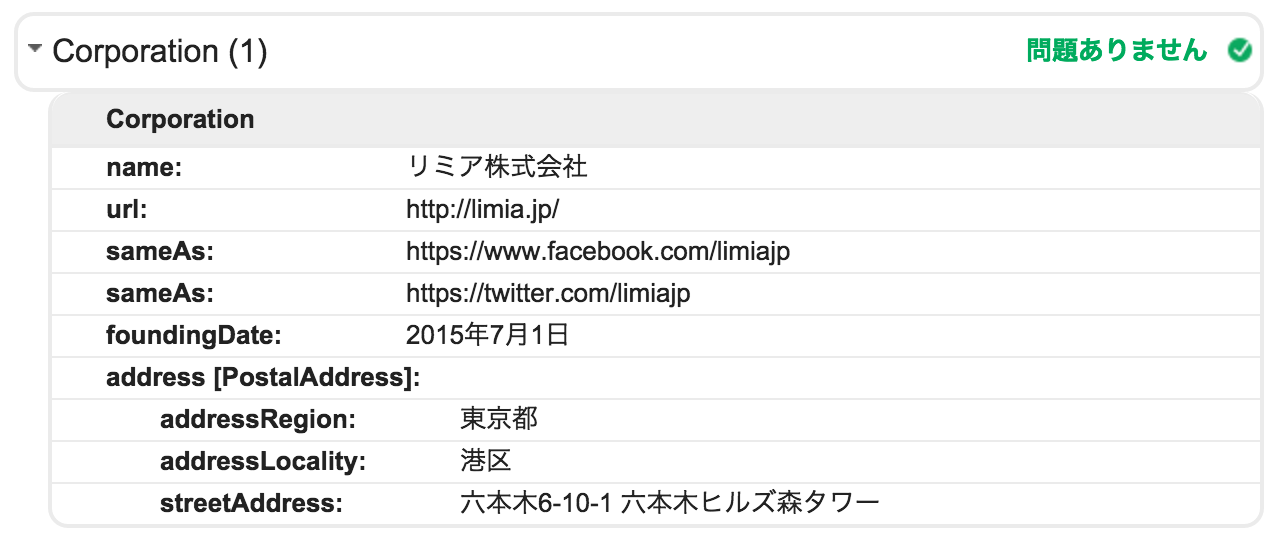
ブラウザで見た時に表示されるのは、社名、設立日、住所のみですが、
表示されない情報でも、クローラには会社概要のメタ情報として正しく伝わります。
その他の語彙(vocabulary)
上のデータ例で、Corporation、PostalAddress が出てきました。
その他にも様々な語彙がありますので少しだけご紹介します。
Review
検索結果で評価結果(★★★★☆)を見たことはないでしょうか?
これは、クローラが「Review」(とその中にある、Ratings)という語彙を認識して検索結果に反映しています。
リッチスニペットと呼ばれているものの1つです。
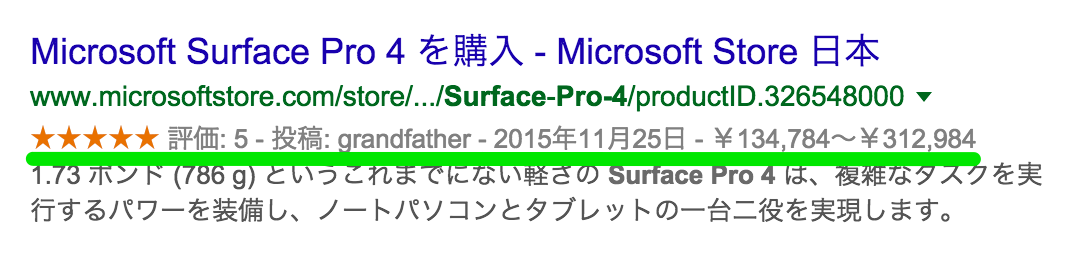
ちなみに、Review は特定の Product や Brand、Restaurant などを対象とするのは良いのですが、
いくつかの商品をまとめて集計した結果であったり、ブログの記事を対象とするのはガイドライン違反となります。
ガイドラインは、Google が公開している Review の記事を参考にしてみてください。
Recipe
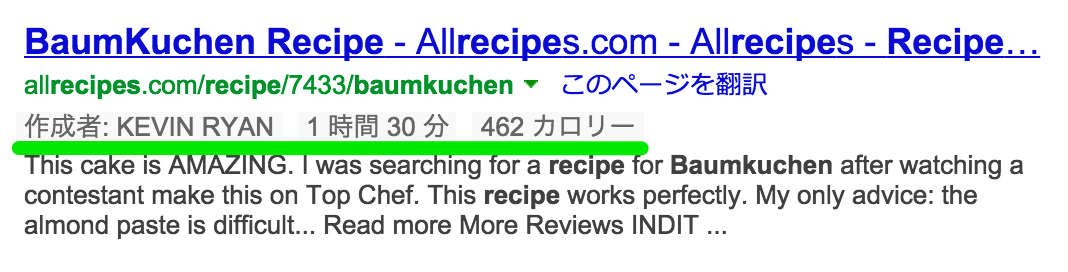
Recipe も非常に分かりやすい検索結果となります。
こちらも評価が表示されるのに加え、調理の所要時間や料理のサムネイル、カロリーも表示されます。
「baumkuchen recipe」と検索してみましたが、Google と Bing では検索結果に表示されています。
Google:

Bing:
具体的な埋め込み方などは、Google が公開している Recipe の記事をご覧ください。
EmailMessage
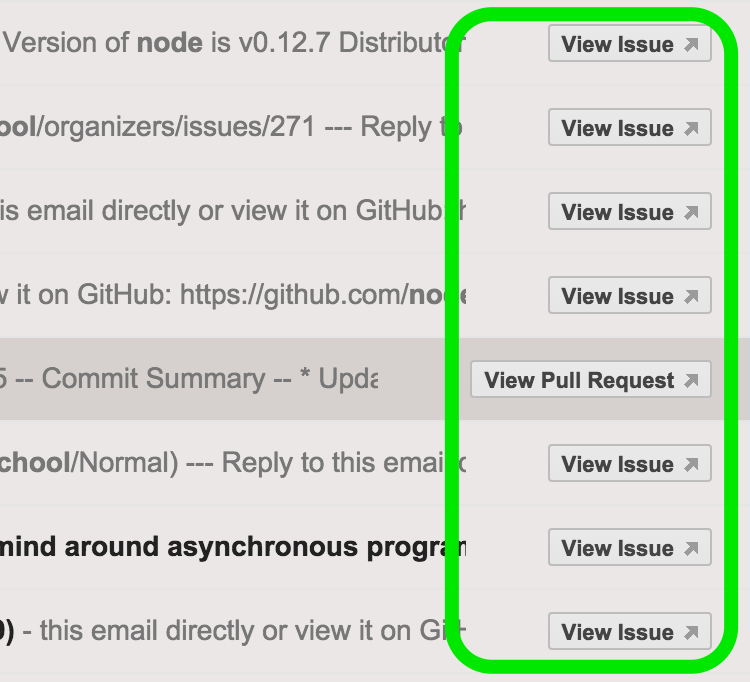
Gmail をお使いの方であれば、GitHub からこんなメールを受け取ったことはないでしょうか?
これは、Go-To Actions と呼ばれており、語彙のひとつである EmailMessage が埋め込まれています。
これによって、ユーザーはメールの中身を見ずともワンクリックで特定の対象URLを開くことが出来ます。
メール関係では、他にも出欠確認が出来る RSVP Action もあります。
その他色々と Gmail Actions が定義されているようです。
※ ちなみに私はまだ試したことはありません。
埋め込まれた構造化データの実例
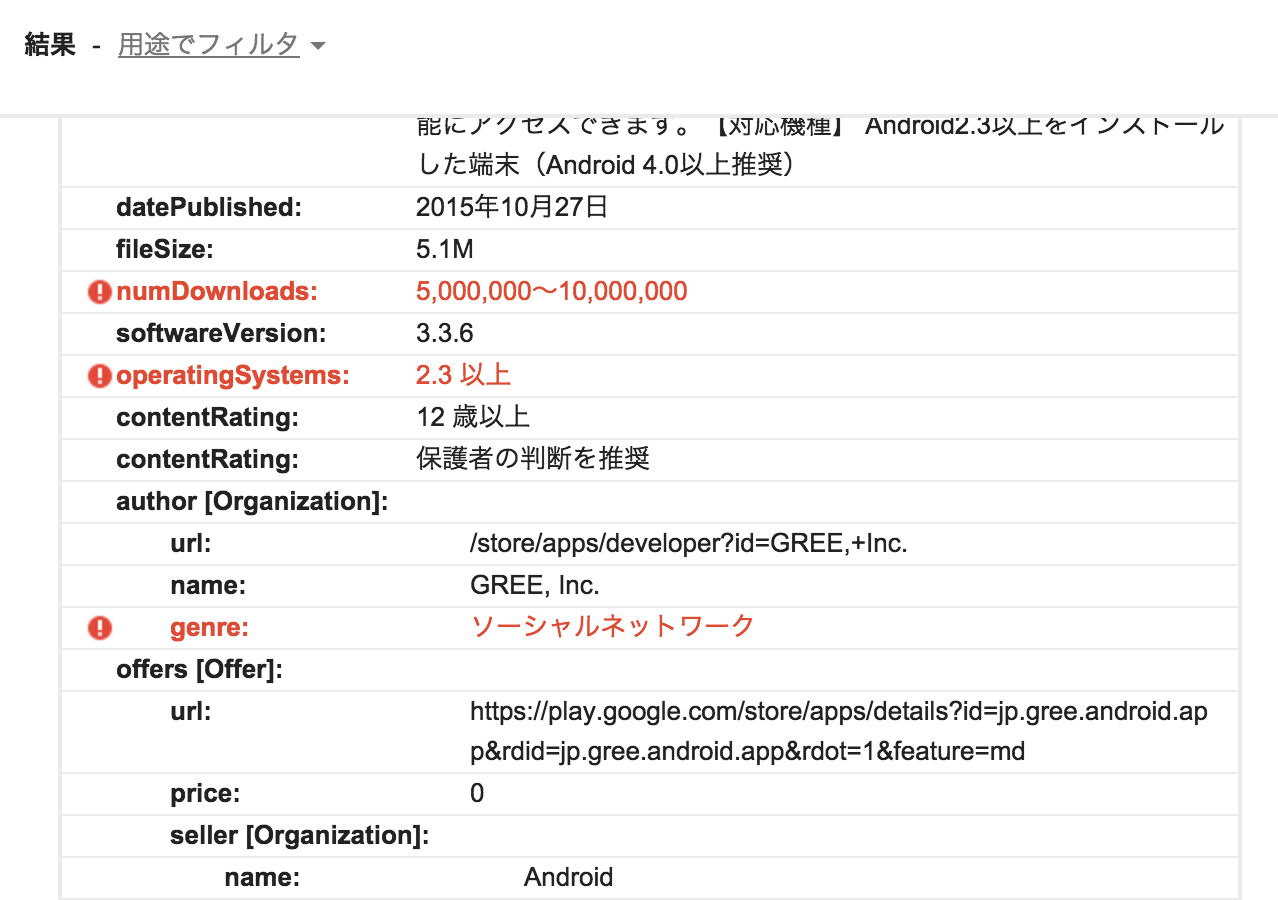
Google Play にある、GREE (グリー) のページを先ほどのツールで確認してみると、
アップデート日やバージョン、コンテンツのレーティング、レビュー件数などとあわせて、
詳細なレビューの平均点数など様々なデータが、Schema.org に準拠してマークアップされていることが分かります。
ツールで確認した際に表示される項目の一部をキャプチャしたものがこちらです。
実際にはもっと多くのデータが埋め込まれています。是非ご自分で確認してみてください!
検索結果に反映された実例
GREEは先月5日、住まいのビジュアルプラットフォームとして LIMIA というサービスを開始しました。
(SNSとしても利用でき、雑誌感覚で読んでも面白く、ためになるので是非閲覧してみてください!※宣伝です)
※ LIMIA プレスリリース
この LIMIA では、パンくず構造や記事詳細などのデータを埋め込んでいます。
その結果の一部をご紹介したいと思います。
Google で「オランダ 国会議事堂図書館」と検索した結果の一部をキャプチャしたものが以下です。

記事タイトルの下にパンくず構造が表示されてあり、このページがサイト上でどういう階層にあるのか構造が一目で分かります。
また、この記事がいつ書かれたものなのかということもすぐに分かります。
このページには、これらの情報に関するいくつかの構造化データが埋め込んであります。
キャプチャにある「2015/11/20」 という日付の表示も、Article の datePublished というひとつのメタ情報から反映に影響を及ぼします。
パンくず構造や記事詳細などのデータを埋め込んでいない例がこちらになります。

データを埋め込んでおりませんので、パンくずの階層ではなく、URLがそのまま表示されています。日付の表示もありません。
Webサイトの性質によっては作成日時などを表示しなくとも問題ないこともあるので一概には言えませんが、例えば検索結果に他にも同じようなページがあった場合、ユーザーにとっては日付の表示があった方が判断しやすい情報となりますよね。
パンくず構造はどのように定義しているかというと JSON-LD を使ってマークアップしています。
これによりURLではなく「アイデア」や「アーキテクチャ」といったテキストが検索結果に表示されることに繋がります。
※ 該当のページのソースもご覧頂ければと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
<script type="application/ld+json"> { "@context":"http://schema.org", "@type":"BreadcrumbList", "itemListElement":[ { "@type":"ListItem", "position":1, "item":{ "@id":"/", "name":"LIMIAトップ" } }, { "@type":"ListItem", "position":2, "item":{ "@id":"/idea/", "name":"アイデア" } }, { "@type":"ListItem", "position":3, "item":{ "@id":"/ideas/architecture", "name":"アーキテクチャ" } }, { "@type":"ListItem", "position":4, "item":{ "@id":"/idea/2617/", "name":"オリエンタルな雰囲気漂うオランダの国会議事堂図書館。" } } ] } </script> |
Webページから伝えたい情報を整理する
言ってみればそもそも、HTML というものが情報構造を表現するためものなのですが、
Webサイトを開発している時には、見た目の美しさや配置、導線の確保等が真っ先に優先されることが多いような気がします。
もちろん、視覚的に気持ちの良い配置を考えたり、競合に負けない要素を考えたりする工夫は大事なことですが、いかに素早く情報を伝えられるかということも大変重要です。
また検索する立場からしても、一覧に表示された情報がきちんと整理されているのといないのとでは、それらを区別判断するのに少なからず違いが出ると思います。
こういった構造化データをきちんとマークアップしようと思った時、サイトの情報構造が整理されていないと難しくなってしまいます。
複雑すぎるサイトの作りになっていたり、クローラに渡すデータに実際の内容が沿っていないような場合には、仮にそれらを検索結果に表示したとしても閲覧者にとって意味のないものになってしまうからです。
反対に、閲覧者が検索結果に表示された一部の情報を見て、そのサイトがどういった構造になっていてどういった内容を取り扱っているか、いつ書かれたか、サイト内にどんな評価基準を持っているかと言ったことを一目で理解できれば、それは情報価値の高いサイトであると言えると思います。
加えてそれをクリックした時、より詳しい内容や得たい知識と合致した内容、そこからの新しい発見があった場合には、非常に高い満足度を得られます。
それを実現する為には、初期のサイト設計の段階から構造のシンプル化や合理化を考える必要があります。
その際、上記で紹介したような情報構造のデータは、単なる検索結果に向けたメタ情報としての役割だけでなく、分かりやすく短く情報を整理する為の一つのメソッドとして利用することもできます。
エンジニア目線からすれば、
綺麗に構造化されたデータは見ていても書いていても楽しいものです。
つまり、業務効率も改善されます!
誰にとっても良いことばかりです!
実際に埋め込んでみても、とてもシンプルなのであまりコストもかかりません。
パッと見た時のページの見た目からは分かりづらいかもしれませんが、
是非 Schema.org に準拠したマークアップを導入してユーザーにより良い検索結果を提供しましょう!
構造化データ マークアップ支援ツール もありますよ!
明日は 大山(@ohyama00) さんによる「オンプレミスからパブリッククラウド移行で変わった事」の記事です。お楽しみに!