Deep Learning を用いた画像識別モデルの導入
背景
僕の開発担当しているチームでは、プロダクト( SNS、Web ゲーム等 )におけるユーザの任意投稿をオペレータによって目視で監査し、サービス運営上、不適切な投稿の検知と削除を行っています。
しかし、ユーザ投稿すべてを目視で監査するのはオペレータの負荷が高いため、不適切と思われる投稿をシステムで選別した上で、オペレータの目視監査に回しています。
ここで、具体的に不適切な投稿とは
- 異性との出会いを希望・誘導する投稿(青少年の健全な育成)
- 個人情報を掲載する行為(個人情報保護)
- わいせつ、およびグロテスクな内容(サービスクオリティ維持) 等
グリーが禁止している行為を指します。
上記、システムの精度向上が僕らチームの目標となっています。中でも画像付きの投稿はシステムによる選別が難しく、大量に目視監査に回すことでサービスのクオリティを維持しているという課題がありました。
そこで今回、ユーザの画像付き投稿を Deep Learning で自動識別するモデルを導入することになりました。
方針
本システムを導入する上で選択肢として、Google Vision API と Tensorflow が挙がりました。
- Google Vision API
- Google が提供する画像認識 API
- 不適切なコンテンツ検出(セーフサーチ)、テキスト抽出(OCR)等が可能
- Tensorflow
- 同じく Google が提供する機械学習ライブラリ
- データフローグラフを使用、複雑なネットワークを分かりやすく記述可能
上記、選択肢の中から以下の理由を考慮して
- グリーの判定基準が特殊
- 不適切と判定する基準はグリー独自のものであり、Vision API の基準と異なる
- GREE は全年齢対象サイトである為、基準は一般的なレベルよりも厳しめ
- 運用コストの考慮
- 投稿件数 × API 使用料よりも自前モデル生成、運用の方がコストが低い
Tensorflow を用いた自前のモデル生成で実装を進めることにしました。
学習データの準備
識別モデルを生成するため、オペレータの目視監査ログから以下のデータを学習データとして利用しました。
- ham データ@25,000件
- 適切と判定を受けた画像
- spam データ@25,000件
- 不適切と判定を受けた画像
上記、2種類のデータを学習データ(40,000件) / 評価データ(10,000件)に分割し、Tensorflow で用いる tfrecords 形式に固めて準備しておきます。
モデル学習
準備した学習データを用いて2値分類( ham / spam )するモデルを学習させました。
学習用サーバとして、AWS EC2 の GPU インスタンスを構築
- OS:Ubuntu 14.04
- インスタンス名:g2.2xlarge
- 台数:3台
※別途 python & Tensorflow 環境構築
学習モデルは画像認識で定番の CNN を採用しました。

VGGnet を 6層に減らした軽量化版
- Convolutions 4層
- Fully Connection 2層
- dropout
- softmax_linear
最適化アルゴリズムに Adam を選定し、20万 step 学習を行いました。(約12時間)
問題点
上記環境にて、学習 > 評価 > 精度が良いモデルを本番データ(未知データ)に適用を繰り返していましたが、評価データで精度が良いモデルでも、本番データに適用すると精度が落ちるといった問題が発生しました…
(原因)
- GREE サービスの仕様上、1つの入力フォームから複数の画像を添付可能
- 我々のチームで扱うシステム監査の単位が「投稿」ごと
つまり、1つの「投稿」に複数の画像が添付されている場合、いずれか1つの画像が不適切と判定されるとその他の適切な画像も spam データとしてログに残ってしまいます。このログをそのまま学習データとして利用していたため、適切な画像がノイズとなりモデルの精度が上がりませんでした。
また、単に不適切と言っても画像の種類は様々なので、それぞれの判定精度を上げるためには 2値分類では限界がありました。
(対策)
問題となる仕様を踏まえ、以下の見直しを実施しました。
- spam データの選別 ノイズ除去
- 「投稿」を画像単位に分割
- ham(適切)判定の画像を除去
- spam データの細分化 識別精度向上
- ham / spam の2値分類から画像の類似度を考慮して多クラス分類に変更
- 例
- ham(0):オペレータが適切と判定
- spam(1):オペレータが不適切と判定(卑猥な画像)
- spam(2):オペレータが不適切と判定(個人情報を記載した画像) 等
:
上記2点の見直しを行うため、spam データを一覧で参照できるツールを用意してオペレータに再度ラべリングを実施してもらいました。
この作業により、最適な学習データを用意することが出来たので、再度モデルを学習させました。
モデル結果
上記モデルを本番データに適用した際に、サービスクオリティに影響ない範囲で誤識別を考慮し、既存システムと比較して目視監査の件数を半分にすることが出来ました。
運用システム
モデルは完成したので、実際の運用システムをご紹介します。
画像の判定は、API サーバを構築してそこにリクエストを送る形式としました。
冗長性を持たせるため、3台構成で運用します。
以下、処理の流れ
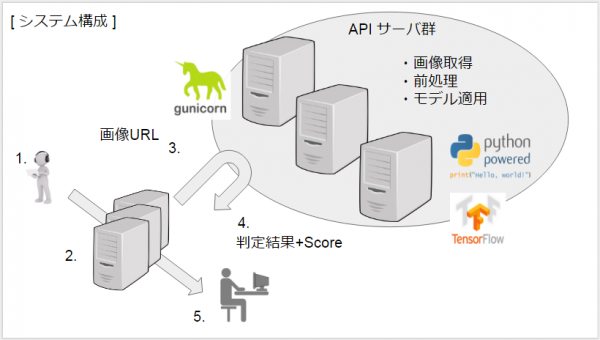
- ユーザ投稿(画像付き)
- 画像URL取得
- API リクエスト
- API サーバ
- モデルの読み込み
- URL リストを受け取って、画像を取得
- 画像を tensor に変換
- モデル判定
- 画像ごとに各クラスのスコアを計算した結果を返す
- API レスポンス
- オペレータによる目視監査
また、モデルの判定結果により、目視監査の対象にならなかったコンテンツを一部目視監査に回すことで、モデルの精度低下を検知出来るような仕組みにしてます。
所感
僕の所属するチームでは、監査業務の効率化のため、これまでにも様々な手法でテキスト、画像の識別に機械学習を取り入れてきました。
僕自身は、機械学習の専門家ではなく、このような業務に取り組む機会がほとんどなかったのですが、前任の方を含め、社内の知見のある方にアドバイスを頂きながら、チームメンバーと試行錯誤して最終的に成果を出せたことは良かったなと思います。
本システムを導入する上で利用した Tensorflow は、ドキュメントが充実していて、コード記述も簡潔に書けるため、僕のような初心者でも少ない学習コストでシステム導入することが出来ました。(むしろ機械学習の基礎知識のインプットが大変…
今では、Tensorflow と Theano 用の Deep Learning ライブラリ Keras もあるので、機械学習に興味ある方は、業務でなくとも色々触ってみるのは楽しいかなと思います。
今回の施策は明確に目標と期限が決まっていたこともあり、限られたリソースの中である程度、モデルやパラメータを決め打ちで取り組んでいました。
試していない手法や分野はまだまだ沢山あるので、これを機に今後も機械学習に触れていけたらなと思います。