VTuberアプリのGCPデータ基盤について
こんにちわ、そしてメリークリスマス。データエンジニアグループの鈴木です。
前回はDialogflowを利用したチャットボット導入事例をご紹介しました。
今回は、VTuber視聴・配信アプリのREALITYのGCPデータ基盤のシステム構成や各コンポーネントの役割についてお話しします。
一つ一つのアーキテクチャの解説は少ないですが、全体のシステム構成を振り返っていくので、GCPデータ基盤を検討している方にはお役に立てる内容があるかもしれません。
(システム構築をしたのが2018/9なため、情報が古い可能性があります。)
背景
以前の記事で紹介されたとおり、今回のプロダクト環境はGCPを多く利用しています。
弊社のデータ基盤環境はオンプレやAWSで長く運用しており、その既存基盤にデータを蓄積することも勿論可能でしたが、GCPコンポーネント同士の連携のしやすさや技術検証なども兼ねて、今回はGCPでシステム構築することになりました。
システム構成
早速ですが、今回構築したデータ基盤システムの概要図です。
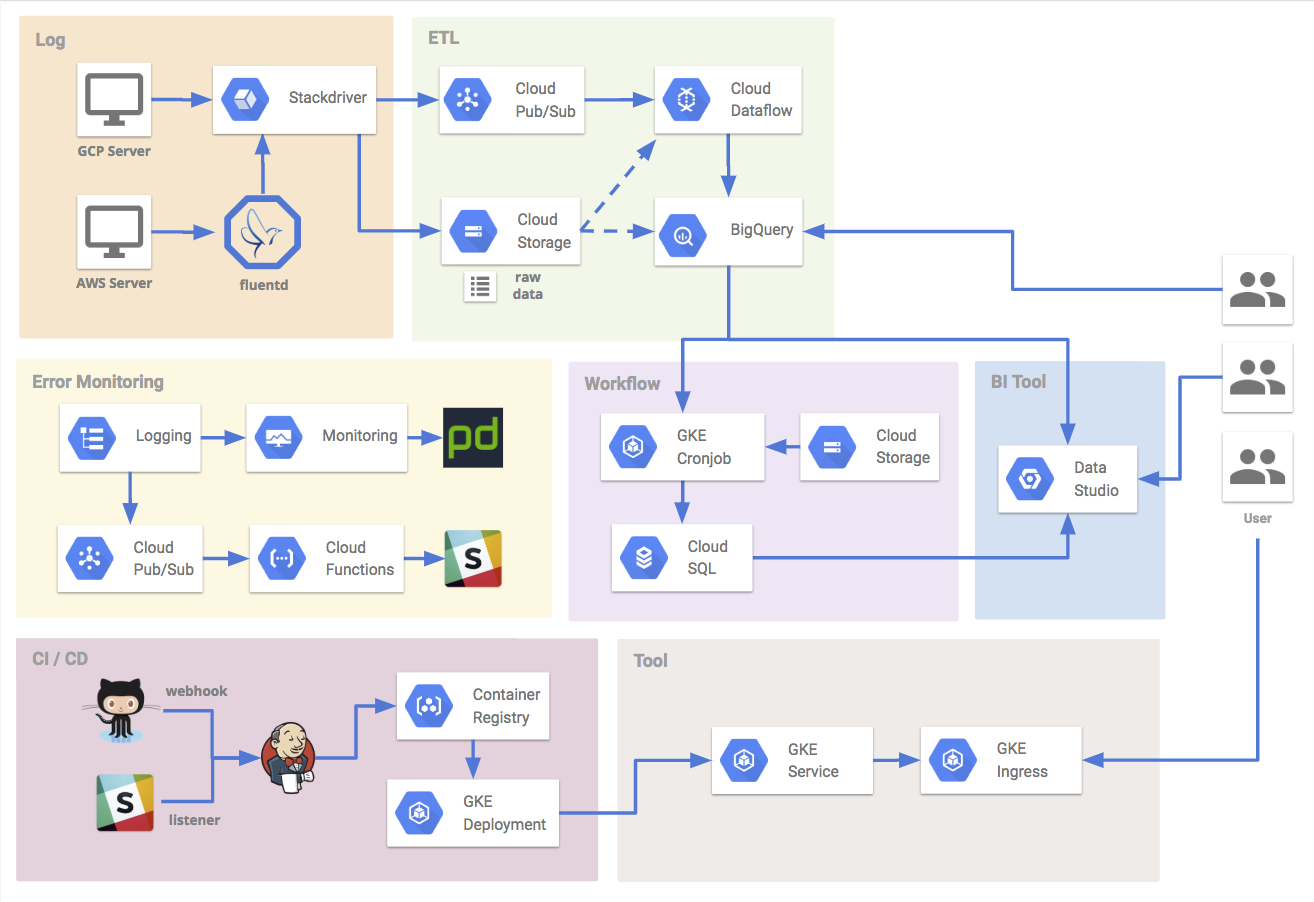
主に下記のような機能役割があり、それぞれの役割やコンポーネントについて簡単に説明していきます。
- ログ受信担当
- ETL担当
- ワークフロー担当
- BIツール担当
- エラー監視担当
CI/CD担当比較的よくある構成ですが、GKEをベースとしたアーキテクチャとなっており、運用簡素化やヒューマンエラー防止のために工夫したポイントなどもご紹介します。
ログ受信担当
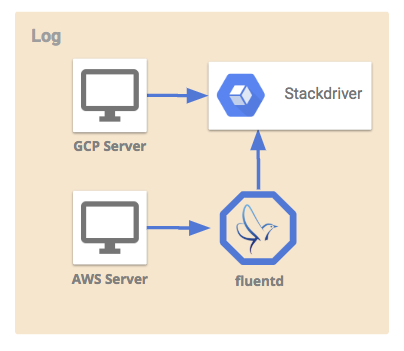
Stackdriver Logging
Stackdriver Loggingは、GCPプロダクト環境のログエージェントから分析ログを集約する役割を担っています。
Pub/Subに直接ログを送信することも可能でしたが、Stackdriverを採用した主な理由として、他コンポーネントとの連携のしやすさが挙げられます。
Stackdriverからログのexportルールやシステム指標を設定することが可能です。Stackdriverにだけログを送信しておけば、別コンポーネントにも簡単にログを同期することができるため、ログを二重に送信する必要がなくシステムをシンプルに保てます。
また、Pub/SubのmessageIdでも同様のことはできますが、Stackdriverへログ送信されたときに一意に決まるinsertIdを利用すれば、ログの重複・欠損の調査も楽に監視することができました。
ただし、Logging APIのQuotasが小さいため直接API経由でログ送信する際は注意が必要で、ボトルネックとなりやすいです。ログエージェント経由で書き込むこと問題回避することができ、スケールしやすい作りにすることが可能です。
ETL担当
Pub/SubやCloud Storageに保存されたログを整形して、DWHに保存するまでの部分を担当しています。
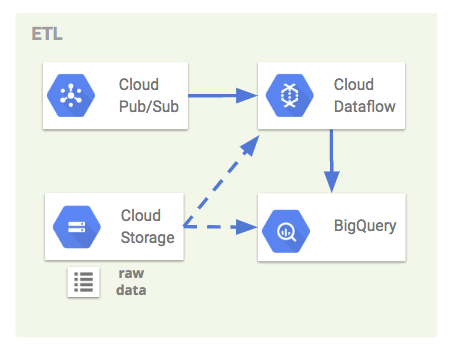
Cloud Pub/Sub
Stackdriverから送られたリアルタイムデータを、BigQueryへストリーミングインサートする際のQueueの役割を担っています。
メッセージブローカーのため非同期にレコードを処理して、ログ量が急増しても高可用性を担保できるモデルとなっています。今回のシステムではStackdriverログをサブスクライブするTopicを作成し、DataflowでそのSubscriptionのエンドポイントからBigQueryへデータを追記しています。
Pub/Subからの大規模なデータ処理は、基本的にDataflowを利用する場面が多い(料金が発生する)ため、ストリーミング処理が必要でない場合は、Stackdriverのexport機能を利用するのが良いでしょう。
Cloud Storage
Cloud Storageは、生ログのバックアップ先として利用しています。Stackdriver Loggingのexport機能で、1時間毎にシンクしています。
普段の運用時には特に利用する場面は少ないですが、エラーでDataflowのログ処理が停止した場合や、障害などでログの重複欠損が発生した場合に、このバックアップ用のGCSからBigQueryへログをインポートして、ログ復旧できる作りになっています。
Dataflow
DataflowはApache Beamベースの分散処理サービスで、Pub/Subのストリームレコードを並列処理してBigQueryへニアリアルタイムに繋ぐパイプラインとしての役割を担っています。
ほぼ同様のコードで、データソース先をPub/SubかCloud Storageを選択するだけで、動的にストリーミング処理とバッチ処理を使い分けることができるので、様々な場面での利用が可能です。
データ量が急増した場合でもオートスケールして処理量を増やすことができるので、メンテナンスコストを削減することができています。
開発当初は、インサートするTableを動的に決められずに、TableごとにJobを同時実行して料金が高くなってしまう課題に直面しました。
Dataflowでは事前にモデルを定義して、作成されたモデルにデータを流していくパイプライン思想となっているため、事前にモデルに対応したTableを定義するのが一般的です。
その回避策として、DynamicDestinationsクラスを利用し、Tableカラムに応じて動的にinsert先を変更する対応を入れています。
こういった動的Table機能やAuto Parametar機能などがPythonでサポートされていない部分が多かったたため、今回はJavaを選択して開発しています。
DataflowのJob実行には、ローカル環境やGCE環境など選ばないのですが、Job実行後にその環境が不要となることやマシン環境を統一させたい理由から、Kurbernetes Jobを利用するのをオススメします。
BigQuery
自社でクラスタ管理する場合、負荷状況によってワーカー数をスケールさせたりと運用コストがかかりやすいですが、BigQueryは裏側で大量のコンピュータリソースで分散並列処理しているため、スケール考慮する必要なくほとんどのクエリを数秒以内に集計することが可能です。
クエリ時にパーティションカラムの指定がなければエラーにするflagがあったりと、初学者にも優しい作りになっています。
分析クエリ料金はデータ処理容量で決まるため、Tableを日毎に分割するのが定石パターンとなっています。現在Tableの分割タイプは、取り込み時間による分割方法と時間カラムでの分割方法があります。カラムナーDBのため、スキーマ変更コストは高まりますが、パフォーマンス面で優れる時間カラムでの分割がオススメです。
ただしUTCでパーティションされているため、JSTでデータ集計する場合などには注意が必要です。
スキーマ変更・削除の際は、基本的にTableの作り直しが必要になります。現状はBigQueryのextract・load自体に料金は発生しないため、GCSなどにデータを退避させて作り直すのが良いでしょう。
ワークフロー担当
BIツールから都度BigQueryへクエリコストをかけたくないため、TSDBとしてデータマートを定期抽出する部分を担当しています。
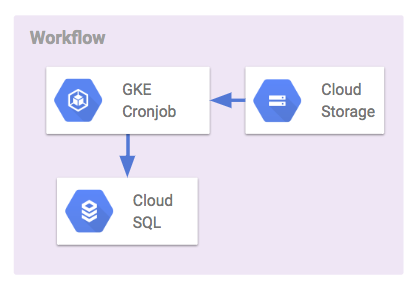
Kubernetes Engine
今回、クエリの定期実行にKubernetes CronJobを利用するようにしています。
類似したサービスとしてBigQueryスケジューラ、Cloud Composer、OSSのワークフローツールが挙げられますが、下記の理由からKubernetes CronJobを利用した独自ワークフローシステムを採用しました。
- 1時間ごとのクエリ実行が必要(BigQueryスケジューラは最短3時間の間隔をあける必要がある)
- 非ENも触るためクエリ完結させたい
- タスク依存関係の考慮は必須ではない(Composerなどのスクリプト型ワークフローほど高機能性は必要ない)
- ジョブの履歴管理と失敗時のリトライ処理を利用したい(k8sのrestartPolicyが利用できる)
- backfillや冪等性担保などのカスタマイズ性は持たせたい
- 開発工数の低さ(OSSのワークフローだと開発工数がかかりやすい)また、GAE CronJobでなくGKE CronJobを採用したのは下記の理由になります。
- GKEでは細かいインフラ管理(失敗時のリトライ処理や履歴管理など)ができる
- GKEではCronJobを別々に登録・管理できる
GKEではファイアウォールのIP制限が1つのサービスごとに設定できる今後タスクの依存関係まで考慮する必要が出てくればワークフローエンジンを検討する可能性はありますが、現状のシステムでも不自由なく運用ができていると思います。
Cloud SQL
BIツールから取得する時系列データマートの役割を担当しています。DataStudioからデータストアにアクセスする際、BigQueryの場合はストリーミングバッファにデータが含まれているため、キャッシュを利用せずに都度クエリを叩いてしまいます。
BigQueryのクエリ料金面はとても安いので気にならないレベルですが、BIツールはよく閲覧されるため、レイテンシが無視できなくなってきます。そのため、間にCloud SQLを挟んでレイテンシの改善に繋げています。
BIツール担当
DataStudio
ビジュアライズが豊富なため、アドホック分析以外のKPI可視化はDataStudioで完結することが多いです。
特に、探索的分析をすることができるのが便利で、フィルター機能とHyperLink機能を組み合わせることで利用することができます。
エラー監視担当
GCP内で発生したエラーを監視し、SlackやPagerDutyへ転送する仕組みを担当しています。
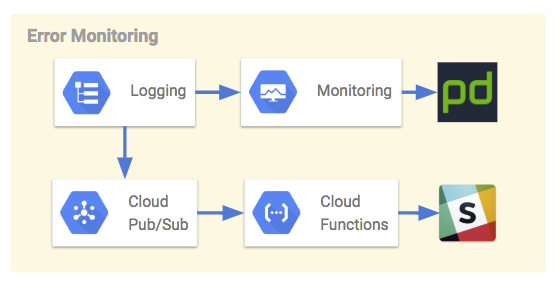
Stackdriver Monitoring
Loggingの指標をフィルターにとしてMonitoringで参照できるようになります。
エラー件数などの閾値ルールを設定して、PagerDuty通知やWebhookを利用することができます。
Cloud Functions
Functionsを利用すると、LoggingからexportしたPub/Subからイベントドリブンに処理ができるようになります。
ログレコードごとの単純な通知処理の場合は、Functionsが連携しやすかったです。
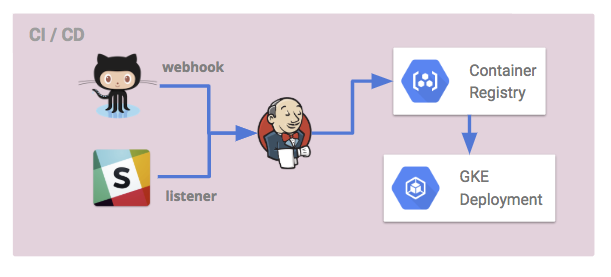
CI/CD担当
今回のデータシステムは、GKEをベースとしたコンポーネントが多い構成となっています。
GKE運用時に陥りやすいポイントとして、開発者ごとに微妙にk8sのversionが異なることによるデグレや、複数の環境(Cluster、Namespace、Project)運用によるapplyミスなどが発生しやすいかと思います。
環境統一したCI/CD環境を導入することで、作業の自動化はもちろんのこと、GKE運用のヒューマンエラーを防止することが期待できます。
今回導入したのは、Github、Slack、JenkinsをトリガーとしたCI/CDです。
開発環境では、master branchにmergeされたタイミングで自動的に環境反映してほしいため、Github Webhookをトリガーとして、Container RegistryのBuildと、GKEのDeploymentのImage更新を実施しています。
本番環境では、開発テストが完了したタイミングで手動で反映したいため、SlackコマンドListener経由か、Jenkins経由でBuild・DeployのJobを利用できるようにしています。
まとめ
以上、GCPで作成するデータ基盤システムの各コンポーネントをざっくりとご紹介しました。
GCPはAWSと比較すると記事や書籍も少なく、version前後の互換性変更や仕様更新それなりにあった気がします。調査力は必要ですが、公式ドキュメントやコードが充実しているので、それを参考にするのが一番近道なことが多かったです。
ただ日本語の記事は少なく、書いたら需要ありそうだったこともあり今回書いてみました(笑)
今回のデータシステムを開発運用してみて、GCPのマネジメントサービスはどれも可用性が高くスケールしやすいシステムとなっているため、ログ量の増加による問題はほとんど発生していないです。
既存のマネジメントサービスでほとんどのニーズをカバーできるので、フルスクラッチでツールを開発することも少なく、開発工数を大幅に削減ができました。
一度運用にのれば、リソース管理などのメンテナンスコストがほぼかからないのも良いポイントかなと思います。
データエンジニアリンググループでは、データ分析基盤や機械学習に関心のあるエンジニアを募集しているので、興味ある方はぜひお願いします。
今後も機会があれば、システム事例の紹介をしていければと思います。
それでは、Happy Hacking and Merry Christmas :)