
SREcon19 Americasに参加してきました
開発本部インフラストラクチャ部の岩堀・反田です。
私達は部内のチームへの所属の他、Monitoring Unitというチームに属しており、サーバ監視システムの運用を担当しております。
今回Unitとして3/25-27にブルックリンにて開催されたSREcon19 Americasへ参加してきましたので、簡単にレポートさせて頂きたいと思います。
SREconについて
SREconについての説明は以下公式からの引用ですが
SREcon is a gathering of engineers who care deeply about site reliability, systems engineering, and working with complex distributed systems at scale.
という一文から始まっており、主に大規模分散システムを扱うエンジニアを対象としたカンファレンスとして定義されており、SRE的な文脈で扱われる様々なトピック(SLO、エラーバジェット、サーバ監視、運用、on callアラート対応にまつわるものなど)が扱われます。
今回のSREcon19 Americasは3日間行われ、600人以上が参加しました。
基本は朝から夕方まで休憩をはさみつつセッションが続く形となります。
30分のセッションがメインですが、2日目は長めの時間が取られワークショップが行われます。

会場のマリオットホテル

エントランスの様子

Refreshmentsはヨーグルトや果物が提供されます

twitterがスポンサーの朝食
セッションの紹介
Testing in Production at Scale
Uberにおいてマイクロサービスをプロダクション環境でどのようにテストしているか紹介されていました。
テスト専用環境を構築するのに比べて、プロダクション環境をテストに使うのは、テスト環境構築コストが下がるだけではなく、より精度が高いテストができるなど多くのメリットがあるそうです。
プロダクション環境で安全にテストするために、プロダクション環境を仮想的に複数のテナンシに分離し、リクエスト毎に宛先テナンシを設定することで、テスト用リクエストがプロダクション用のテナンシで処理されないようにするそうです。
プロダクション環境とほぼ同等の環境でテストすることで、関連するマイクロサービスへの影響を事前に検証でき、パフォーマンスを直接比較できることは大きなメリットがあり、すばらしい取り組みだと感じました。

Sublinear Scaling in Practice: The 1k SRE Project
GoogleのSREチームにおいて、少ない人数でより多くのサービスを運用するために行ってきた自動化の取り組みを紹介されていました。
サービスの別DC移行を例にして、"Declarative Automation"(宣言的な自動化)にすることが重要と話されていました。これは期待するシステムの状態 (移行先DCで移行対象サービスが起動している)をまず定義し、その状態へ遷移するために必要な条件を確認しながら、条件を満たすための処理を実行していくという自動化の方法です。全体として複雑になるものの、再利用しやすく、事前状態に左右されない堅牢な自動化が実現できるそうです。
自動化の具体例としてレビューやアラート対応などを紹介されていて、現在は40人のチームで400個のサービスを担当しているそうです。
"Declarative Automation"はKubernetesの自動化の考え方に近く、その点でとてもGoogleらしい発表だと思いました。自動化を整備するための初期コストは高く、規模によっては現実的な選択肢にならないこともあると思いますが、何かを新しく自動化する際に比較対象として考えるようにしようと思いました。
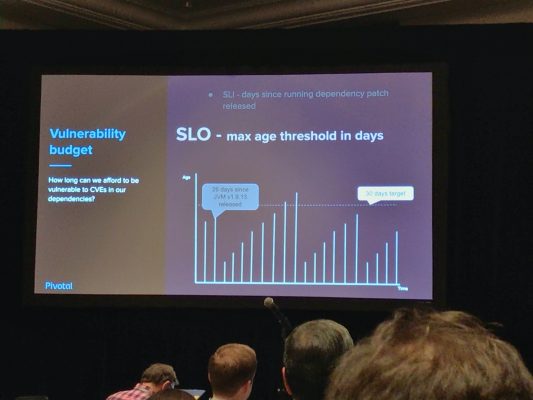
Extending the Error Budget Model to Security and Feature Freshness
Pivotalのエンジニア二名による本セッションはSREにおけるエラーバジェットモデル(SLOに対してSLIが閾値に近づいた時=サービスレベルが下がっている時に何らかのアクションを取る)を、セキュリティと機能の鮮度に対してもそれぞれパッチ適用までの期間、機能のアップデートから更新を取り込むまでの期間をSLIとして定義することで適用する手法について紹介しています。
セキュリティについてはvulnerability budget、機能の鮮度についてはlegacy budgetを定義し、具体的に閾値(SLO)を設定することでシステムの健全性についての指標、明確にアクションを行うべきポイントを設定するような内容になっています。
(鮮度、というとイメージがしづらいですがスライド内ではkubernetesのバージョンを例としてあげています)
Error Budgetの仕組みは目指すべきサービスレベルに対してアクションを取るべきことを明確にする、という点に着目してそれを同様のモデル(セキュリティにせよ、機能の鮮度にせよ決して100%になり得ない&運用負荷とのバランスを求められるという意味において)を適用する取り組みは、実際の運用に際しては多々考えることはあるにせよ良いアイデアだと感じました。
Lessons Learned in Black Box Monitoring 25,000 Endpoints and Proving the SRE Team's Value
U.S. Digital Serviceというアメリカ政府のサービスを担う機関のセッションです。
25000のエンドポイントについての監視システムをHAProxy+BlackboxExporterで実装し、さらにそれをAPI Gateway+Lambdaに構成変更しコスト削減とサービス上の課題を解決した事例について紹介されています。
BlackboxExporterによる監視で同一IPからの大量リクエストが行われたことによりAWSからabuseメールが来た、といったエピソードや大量のエンドポイント監視を行うことで設定の管理やチューニング、ダッシュボード表示がそもそも難しいといった苦労が見えるセッションでした。
URL外形監視の仕組みはSaaSのサービスもたくさんあり、自前で実装して管理するという選択肢を取るにはそれなりの規模がないとなかなかシステム自体のメンテナンスコストと見合わないのではないかと思いますが、本事例では最終的にLambda+API Gatewayという構成になっており、サーバそのもののメンテナンスコストも抑えているのはサーバレスの文脈でも良い事例だと感じました。
おわりに
今回はじめてSREconに参加しましたが、(オープニングトークでも触れられていたのですが)人数的には決して大規模なイベントではないものの、参加者の国籍、所属企業はかなりバラけており、多様なバックグラウンドを持ったエンジニアがそれぞれのノウハウを持ち寄り、我々含め皆実践的なプラクティスを持ち帰ろうという姿勢が大変強いカンファレンスだと感じました。
Fastlyの方のクロージングのセッションでも語られていましたが、「ベストプラクティスは普遍的なものではない」のでグリーにおけるワークロードと照らし合わせつつ、取り入れられる部分について取り入れ、成果があがればまたチームとして発信していきたいと思います。
