Managed Prometheusを用いたGKE監視基盤の話
こんにちは、インフラの小林です。
GCP環境の監視基盤が一段落し実績も積めてきたので、アーキテクチャについて簡単に紹介します。この記事ではメトリックに焦点を当てています。Prometheusを用いたGCP監視基盤を検討している方や、Managed Prometheusを検討している方の参考になれば幸いです。
アーキテクチャ
比較のためにAWS EKS環境と合わせて紹介します。
AWS (EKS)
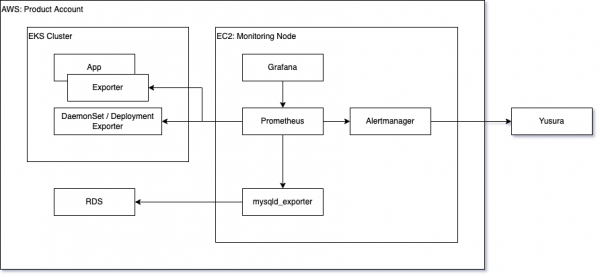
AWS EKS環境では、監視用EC2インスタンスがあり、k8s Cluster内にはExporterのみが存在します。
k8s Cluster外部からkubernetes_sd_configを用いたService Discoveryを行い、メトリックを回収します。AWS環境はプロダクトによってVM, コンテナの利用がまちまちなため、両ケースに対応できるよう監視インスタンスはコンテナではなくVMとして独立しています。
RDSなどManaged Serviceは後述するMulti Target方式でメトリックを回収しています。
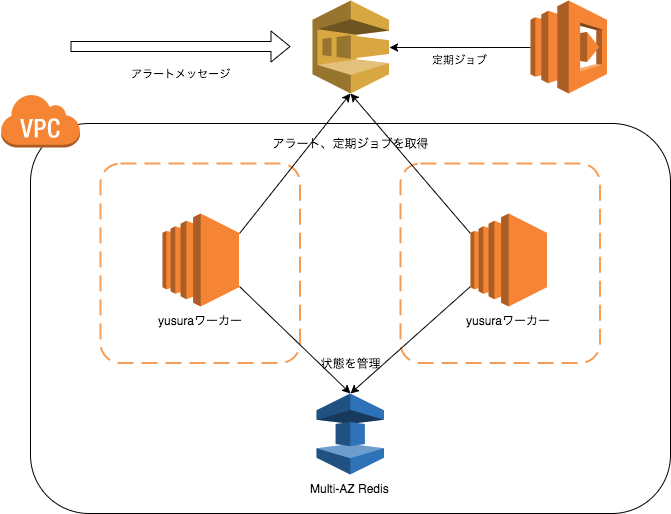
Yusuraとは、社内で作成されたアラート通知基盤です。アラートの振り分けや集約、抑制処理を行いPagerDutyやSlackへ通知します。詳細は以下の記事で触れられています。
SQS、ElastiCache、Lambdaで作る高可用なアラート通知システム
インフラのいわほり(@egmc)です。 サーバ監視を構成するシステムは色々ありますが、今回はAWS環境上での監視に使われているアラート通知の仕組みについて紹介させて頂き…
GCP (GKE)
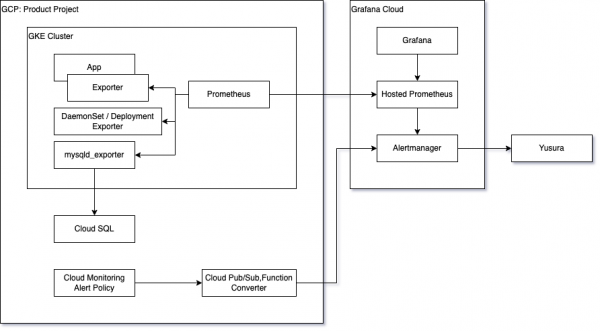
GCP環境は基本的にコンテナベースという社内方針のため、監視エージェントもコンテナベースとなりました。
Prometheusの構成管理には kube-prometheus-stack を利用し、Prometheus Operator CRD(PodMonitor, ServiceMonitor)でscrape configを管理しています。また、PrometheusのLong Term Storageには Grafana Cloud のHosted Prometheus(Cortex)を利用しています。
Cloud SQLなどManaged Serviceに対してMySQLなどのExporterを利用する場合は、AWS同様Multi Target方式でメトリックを回収します。Cloud FunctionsなどGCP固有のServiceに関しては、Cloud Monitoring Alert Policyでアラートを評価しています。
アラート抑制をAlertmanagerで統一する都合上、Payloadを変換するFunctionを実装しています。
設計時に考慮したこと
AWS EKS環境と比較し、GCP GKE環境はコンテナベースである点、Managed Prometheusを利用している点でアーキテクチャが異なります。
これらについて設計時の考慮事項をいくつか述べます。
AWS環境とUI/UXを揃える
利用者の学習コストを下げるため、AWS環境と使い勝手をそろえています。
- AWS環境と共通のExporterを利用することでメトリックを共通化
- アラートの一時的な抑制にはAlertmanagerを利用
- アラート通知基盤はYusuraを利用
社内のメトリックは既存のオンプレミス, AWSともにOpenMetricsフォーマットへ統一され、ラベルこそ違いはありますがメトリックはほぼ共通のためダッシュボード, アラートルールの転用が容易になっています。
アラートの抑制についてはラベル単位で抑制する要件があるため、Cloud Monitoring Alert Policyで設定したアラートをAlertmanagerフォーマットに変換しています。
アラート通知の振り分け設定についてもAWS環境と同様の運用フローを取れるため、GCP環境のために手順が分岐するようなことなく運用できています。
Container Native, Communityに寄せる
AWS環境の監視基盤は7年以上, 検証期間を含めるとPrometheus v0.13から運用されています。当時社内ではコンテナでなくVMが主流であったり、Long Term StorageのOSSが存在しないのでdownsamplerを実装したりと、構成管理・安定運用するためにさまざまなツールが社内で作成されました。実績があり安定している一方で、アーキテクチャが独自進化し、新規メンバーの学習コストという面では課題がありました。
そこで1つの試みとして、GCP環境では監視基盤もVMベースからコンテナベースへ変更するという選択を取りました。Prometheus Operatorやkube-prometheus(-stack)など、コンテナベースの構成管理についてはコミュニティで非常に便利なものがあります。VM Imageの作成・管理が不要になる、Deploy, Auto Healingはk8sが受け持ってくれる、など運用コストのメリットも受けられました。また、kubernetes-mixinで定義されているアラートルールやレコーディングルールはAWS EKS環境にも反映され、AWS EKS環境の品質を上げることもできました。
Managed Prometheusの採用
AWS環境ではLong Term Storageは独自の機構でしたが、最近ではThanosやCortexなどLong Term Storageのミドルウェア界隈が活発です。合わせてGrafana CloudのHosted Prometheusや、AWSのAmazon Managed Service for Prometheusなど、PrometheusのManaged Serviceがここ数年で立て続けに登場しました。
多様な事業形態やさまざまな都合上、弊社ではプロダクトごとにPrometheusを分離しています。Long Term Storageは巨大な1クラスタを運用する上ではコストメリットに優れていますが、小さなクラスタを大量に管理するのは運用負荷が高くなってしまいます。
そこで2つ目の試みとしてManaged Prometheusを利用しました。検証当時はAMPがちょうど発表されたころで、GAされているものとしてはGrafana Cloud1択でした。今ならGoogle Cloud Managed Service for Prometheusも有力な選択肢になりそうです。
直面した課題
検証や実運用の過程で直面した課題とその対応について紹介します。
Time Series削減
Default deployments of preconfigured Prometheus-Grafana-Alertmanager stacks like kube-prometheus scrape and store tens of thousands of active series when launched into a K8s cluster. A vanilla deployment of kube-prometheus in an unloaded 3-Node cluster, configured to remote_write to Grafana Cloud will count towards roughly ~50,000 active series of metrics usage.
k8sのモニタリングではメトリックが多くなりがちです。現状Managed Prometheusの多くは、メトリックとラベルの組み合わせであるtime seriesの単位で課金が行われます。kube-prometheus(-stack)を利用し、うっかりすべてのtime seriesをremote writeしてしまうと想定以上の金額になってしまいます。ダッシュボードやアラートで利用されているか、そのメトリックを見ている人はいるか、など需要と要件を整理しつつ、地道にtime seriesを削減します。
需要と要件では具体性があまりないので、我々がとったアプローチを3点紹介します。
scrapeするmetricsを減らす
node-exporterのcollector optionやkube-state-metricsのresources optionなど、コマンド引数でメトリックのexportを停止します。exporter optionで制御が難しい場合は、Prometheusのscrape config(PodMonitor,ServiceMonitor)のrelabelingでdropします。node-exporterはfilesystemやnetworkが、kube-state-metricsはconfigmap, secretがカーディナリティ高めで削減効果がありました。
remote writeするmetricsを減らす
Local Prometheusにメトリックを保持しながらも、Remote Prometheusには保存しないという割り切りをします。remote write時のrelabelingはすべてのjobを対象としたfilter ruleとなるため、乱用するとメンテナンスが困難になります。可能な限りscrape configの段階でdropできると管理しやすいです。
Local Prometheusにだけ保持しておきたいというユースケースは主に2つあります。
- レコーディングルール用途
- カーディナリティの高いメトリックはレコーディングルールで生成したメトリックだけをremote writeします
- kubelet(cAdvisor)は削減効果が高めです
- kube-state-metricsのpod,containerなどはダッシュボードを作る上で有用なのでremote writeしています
- pod, containerに対して割り切りができるとより大幅に削減できます
- トラブルシュート用途
- 通常の運用時はほぼ気にならないが、入り組んだ障害時にはあると助かるメトリックが該当します
- namespaceなどラベルベースでfilterします
- 費用対効果を鑑みkube-systemのmetricsはremote writeをやめました
- 監視用agentは別のnamespaceで管理しており、この場合kube-systemにはGKEのシステム用コンテナのみが属します
stackdriver_exporterの利用を控える
Prometheusに慣れているとすべてをPromQLで書きたくなります。Cloud MonitoringのメトリックをPrometheusに取り込めるstackdriver_exporterを利用することで、PromQLでCloud Monitoringのメトリック操作を実現できます。すばらしいOSSですが、remote readではなくexporterなのでtime seriesは増えてしまいます。time series削減の観点からCloud MonitoringのメトリックはCloud MonitoringのDatasource、そしてCloud Monitoring Alert Policyをそのまま利用することにしています。ミドルウェア用Exporterとのラベル整合性を取りたい場合など、必要なものに関してはstackdrvier_exporterで回収しています。
time seriesの削減については、以下の記事でも触れられています。
10年もののメトリクス収集機構をリプレースした話
インフラのいわほり(@egmc)です。 久々のエントリとなりますが、今回はインフラのMonitoring Unitとして長期的に取り組んでいた監視システムのリプレースについてのお話…
Grafana Alertの利用
アラート評価について、Prometheus Alert Engine, Cloud Monitoring Alert Engineと2つあることに違和感を感じた方もいるかもしれません。初期の監視基盤ではGrafanaのアラートエンジンのみを利用していました。これでPrometheus, Cloud Monitoring両メトリックのアラートを評価していました。しかしアラートルールの継続条件の評価方法に癖があり、弊社でのユースケースにマッチしなかったため利用を中止しました。
Grafana AlertではFor 5mなど継続時間の指定がある場合、アラートルールとして真が5分継続すれば発砲という評価ロジックとなります。このときtime seriesが同一かどうかは 考慮されません 。これによりコンテナデプロイ時など、単一のコンテナ(time series)としては即時復旧するにもかかわらず、コンテナ数が多い場合などはアラートルールとしての真が継続してしまい誤発砲の原因となりました。この対処のために、それぞれのメトリックを扱うのが得意なアラートエンジンごとに式を評価するように分離しました。
しかしこれは機能としては古い話で、Grafana v8から新しいアラートエンジンが利用可能になりました。弊社ではアラートエンジンの構成は上述の通りですが、Unified Alertでは先の問題が解消されています。
Service Discovery for Managed Service
Prometheus Exporterはメトリックを回収したいコンテナのsidecarとして、またNodeのDaemonSetとして、といったように監視対象の側にAgentを1対1で配置する、というシンプルな設計思想を取っています。監視対象のアプリケーション、ミドルウェアが自身で管理できる範囲では非常によく機能しますが、Managed RDBやKVSなど自身の管理外のサービスに関しては少しややこしくなり、各社工夫していることかと思います。
弊社で行っている手法の1つとして、Multi Target方式があります。Multi Target方式では、1つのExporterが複数Targetからメトリックを回収します。これは redis_exporter で実装されているような、file_sd, http_sdでtargetを取得し、exporterが動的にメトリック回収対象を変更するというしくみです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
scrape_configs: - job_name: 'redis_exporter_targets' file_sd_configs: - files: - targets-redis-instances.json metrics_path: /scrape relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: REDIS-EXPORTER-HOSTNAME:9121 |
このredis_exporterの例ではhttpのリクエスト先としてexporter、メトリックの回収先指定をtargetパラメータで行っています。
この実装方法はデファクトがあるわけではなく、いくつかのexporterが独自のインタフェースで提供しているという状況です。mysqld_exporterは issue で議論されていますがMulti Targetは未対応です。社内ではforkしMulti Targetのパッチを当てて利用しています。
弊社のGCP環境ではCloud SQL, Memorystore Memcache/Redisがよく利用されています。今回はOSSでMulti Targetを実装しているRedisを例としてMulti Targetの実装概要を簡単に説明します。scrape configとしては先のredis_exporterとおおむね同じで、 http_sd を利用している点だけが異なります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
- job_name: redis metrics_path: /scrape http_sd_configs: - url: http://gcp-sd:9981/sd/redis refresh_interval: 60s relabel_configs: - source_labels: [ __address__ ] target_label: __param_target - source_labels: [ __param_target ] target_label: instance - target_label: __address__ replacement: redis-exporter:9121 |
file_sdではなくhttp_sdを利用しているのは、管理するマニフェストがシンプルになるためです。file_sdの場合Prometheusのsidecarや共有ボリュームで実現しますが、http_sdの場合Deploymentを1つ用意するだけです。
残りはRedisのtargetを返すService Discovery Agent(上記だとgcp-sd)を実装してあげれば良さそうです。フォーマットはfile_sdと同じです。
|
1 2 3 4 5 6 7 8 9 |
[ { "targets": [ "", ... ], "labels": { "": "", ... } }, ... ] |
file_sdを実装する上で便利なのが、下記ドキュメントとfile_sd adapterです。
https://github.com/prometheus/prometheus/tree/main/documentation/examples/custom-sd
adapter-usageに実装例がありますが、Discovery(今回ではMemorystore Redis)を実装し、 Adapter.Run() すれば簡単にfile_sdを実装できます。あとは出力されたファイルの中身をhttpのresponseとして返してあげればhttp_sdのできあがりです。素直に実装するとPrometheus側のrefresh_intervalを無視する形になりますが、そこに目を瞑ればhttp_sdとしての要件は満たせます。楽ですね。
kube-prometheus(-stack)の更新
Note that everything is experimental and may change significantly at any time.
と、あるように、kube-prometheus(-stack)は後方互換のない変更がそれなりの頻度で発生します。どのチャートにも言えることではありますが、更新する際はChangelogを眺めつつ慎重にversion upする必要があります。
また、kubernetes-mixin由来のレコーディングルールを利用している場合、 リネームが発生する こともあります。version upする際には、下記のような運用方針を決めておく必要があります。
- 割り切って古いメトリック名のレコーディングルールを自身で追加し、利用を続ける
- 新旧両方のメトリック名でダブルライトし、随時ダッシュボードやアラートを切り替えていく
まとめ
GCP GKE環境でPrometheusを用いた監視基盤について紹介しました。各IaaSでManaged Prometheusが続々と発表されたり、GrafanaがAlert Next GenerationことUnified AlertをGAしたりと、Prometheus/Grafana界隈は活発ですね。
Managed Prometheusはtime seriesをどれだけ削減できるかという勝負になります。各社どういった削減・割り切りを行っているのか非常に興味があります。知見が増えていくと良いですね。