インフラのいわほり(egmc)です。 eBPFを利用したプロダクトとしてはCiliumなどがcloud nativeな文脈として盛り上がっていますが、一方でBCC Toolsやbpftaceは、システム内部のかゆいところ […]
こんにちは、インフラの小林です。 GCP環境の監視基盤が一段落し実績も積めてきたので、アーキテクチャについて簡単に紹介します。この記事ではメトリックに焦点を当てています。Prometheusを用いたGCP監視基盤を検討し […]
インフラのいわほり(@egmc)です。 久々のエントリとなりますが、今回はインフラのMonitoring Unitとして長期的に取り組んでいた監視システムのリプレースについてのお話になります。 背景含めて長いエントリとな […]
開発本部インフラストラクチャ部の岩堀・反田です。 私達は部内のチームへの所属の他、Monitoring Unitというチームに属しており、サーバ監視システムの運用を担当しております。 今回Unitとして3/25-27にブ […]
こんにちわ。せじまです。 秋くらいから艦これ再開したので、ちょうどよいWindowsタブレットはないものかと物色しており、 Surface GO LTE Advanced(一般向け)の発売を待ちわびている今日この頃です。 […]
インフラの反田です。AWSやGCPのモニタリングまわりを担当しています。 GREEでは、大部分のサービスをAWSで運用していますが、一部の新しいサービスではGCPも利用しています。 AWSで運用しているサービスについては […]
インフラの反田 (@mtanda) です。 GREEでは、多くのサービスをAWS環境で運用しており、それらサービスのモニタリングシステムとしてPrometheusを利用しています。 Prometheusを導入してから約2 […]
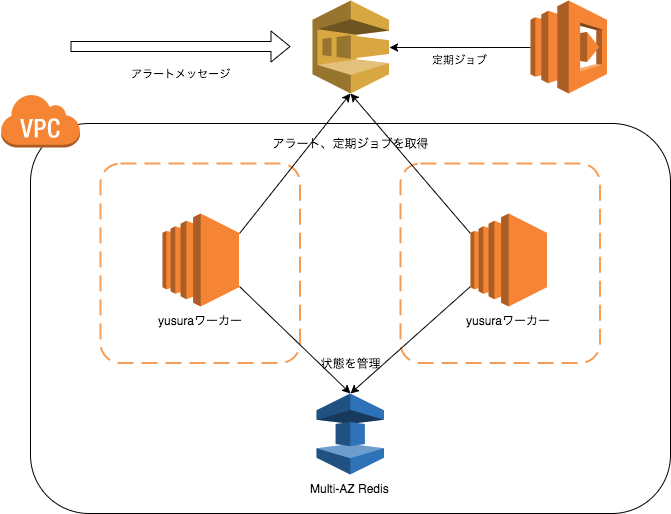
インフラのいわほり(@egmc)です。 サーバ監視を構成するシステムは色々ありますが、今回はAWS環境上での監視に使われているアラート通知の仕組みについて紹介させて頂きます。 監視システムの構築そのものは2015年頃、A […]
こんにちは。グリーのmdoi(@m_doi)です。 今回は、グリーの監視システムについて説明したいと思います。以前、こちらの記事にて、リソース監視システムの説明をさせて頂きましたが、死活監視やログ監視については語られ […]
こんにちは。インフラチームの ebisawa です。 今回はグリーのインフラにおける各種機器の監視がどのように行われているのかご紹介させていただきたいと思います。一般にサーバの監視というと、システムダウンを検出するための […]