オーケストレーション入門 - 多種多様化するサービスをConsulで連携させる
こんにちは、インフラストラクチャ本部のあだち(@foostan)です。
このエントリは GREE Advent Calendar 2014 19日目の記事です。昨日はにしだ(@hosi_mo)さんによるネイティブゲームクライアントの幸せな設計図でした。
今年のグリーアドベントカレンダーのテーマは「GREEを支える技術」ですが、私からは「GREEを支えるかもしれない技術」としてConsulについてご紹介します。
本エントリの対象者
本エントリでは、簡単なWebシステムを例にとって、Consulやその周辺ツールの基本的な使い方やオーケストレーションする仕組みについて説明していきます。
なので
- Consulって何?
- Consulって便利そうだけどどうやって使うの?
- Consul触ってみたけど、使いどころ分からないんだけど?
- オーケストレーションって?
と思われた方にとって良い情報源になることを期待しています。
Consulとは
![]()
Webを利用したシステムやアプリケーションなどはその規模が大きくなると、当然それを提供するためのサービス(Web, DBMS, NoSQL, Storage, Load Balancer, Applicationなど)やそれらを支えるためのサーバ数が増加していきます。
サーバやその上で動くサービスが増えてくると、冗長化を気にしたり、負荷対策を行ったり、障害対応に追われたりなど、運用コストが増加していきます。
たとえば、下記のような構成のWebシステムを運用しているとします。

Webシステムの構成例
このとき次のような状況になったらどのように対処するべきでしょうか。
- Webに障害が発生しアクセスが出来ない状態となった
- DB Masterに障害が発生し、Webからの書き込みができなくなった
- DB Slaveに障害が発生し、Webからの読み込みができなくなった
- 負荷を分散させるために新たにWebを追加したくなった
- 負荷を分散させるために新たにDB Slaveを追加したくなった
規模が小さいうちは手作業で十分な場合もあるかもしれませんが、運用対象が数十台->数百台->数千台となった場合はどうでしょうか、気が遠くなりますよね。
なので出来る限りのことは自動化して最小限の労力で運用したいものです。
そこで今回紹介するのがConsulです。
ConsulはVagrantやPackerなどを開発しているHashicorpによるプロダクトのひとつで、各種サーバをオーケストレーションさせるための様々な機能を持っています。
なお"オーケストレーション"という言葉は抽象度が高いので本エントリでは
複雑なコンピュータシステム/ミドルウェア/サービスの配備/設定/管理の自動化を指す用語(Wikipediaより引用)
と定義します。
Consulの守備範囲
Webシステムを開発(Develop)/公開(Deploy)/運用(Maintenance)のフェーズに分けるとすると、Consulの守備範囲は運用のフェーズにあたります。
先日公開されたHashicorpの新サービスATLASでのConsulの位置づけをみると、
Terraformによるサービス公開後に利用されることを想定していることがわかります。
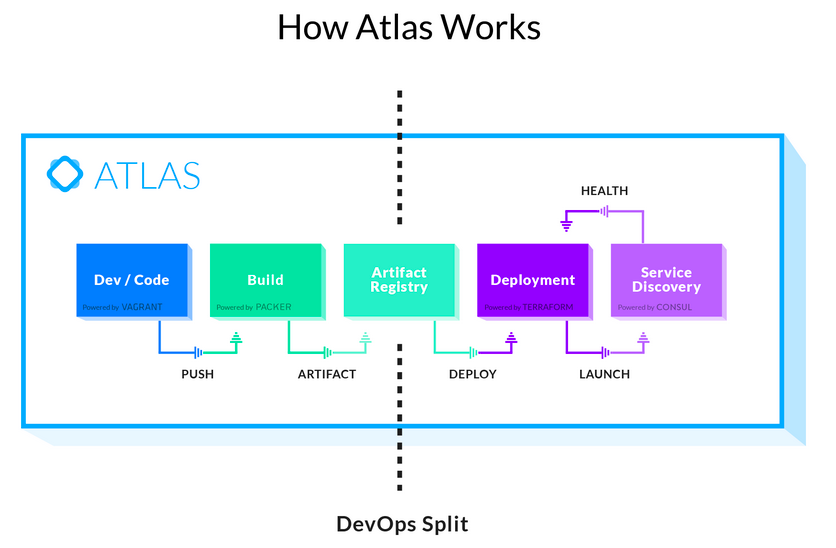
ただしこのあたりの境界は曖昧なので、たとえばChefなどのプロビジョニングツールを利用しているのであれば、Chefで各種ミドルウェアの設定とConsulの設置を行い、そのあとの公開作業や運用作業をConsulで行うとか、Capistranoを使ってソースコード配置および公開を行っているのであれば、その後の運用作業だけをConsulに任せるとか、用途に応じて各ツールを使い分けたり組み合わせるのがいいと思います。
オーケストレーション入門
先ほど挙げたWebシステムを例に取りオーケストレーションを実践していきます。
下準備1 - Consul Agentのインストールと起動
Consulを利用する場合は、運用対象となる各サーバにAgentを設置します。
AgentはGo言語で実装されており、バイナリファイルをひとつ設置するだけでインストールは完了です。
|
1 2 3 |
$ wget -P /tmp https://dl.bintray.com/mitchellh/consul/0.4.1_linux_amd64.zip $ unzip /tmp/0.4.1_linux_amd64.zip -d /tmp $ mv /tmp/consul /usr/bin |
AgentにはServerとClientがあり、ServerがRaft consensus algorithm(pdf)を用いて、クラスタを形成します。また、Clientもクラスタの一員ですが、受け取ったリクエストを自身では解決せずにServerに転送して処理を委託します。
このあたりの詳しい動作についてはCONSENSUS PROTOCOLにまとめられていますのでご参照ください。
Agentの起動はServerの場合
|
1 |
$ consul agent -data-dir /tmp -server -bootstrap-expect 3 |
のよう -server オプションを付けて起動し、さらに1台目のServerに限り -bootstrap-expect オプションを指定します。
また、2台目以降は
|
1 |
$ consul agent -data-dir /tmp -server -join {1台目のServerのIP} |
のように、-join オプションで既に起動済みのAgentに対してJoinします。
また、-bootstrap-expect に与えた数のServer数がJoinした地点でRaft consensus algorithmによってクラスタが形成されてConsulの各種機能が利用可能な状態となります。
なお -ui-dir オプションでUIのファイルが格納されたディレクトリを指定すると、http://demo.consul.io/ui/#/ams2/servicesのようなWebUIを利用することができます。
Clientは
|
1 |
$ consul agent -data-dir /tmp -join {起動済みのAgentのIP} |
-server オプションを外して起動します。
クラスタ内のメンバーの確認を行うためには members コマンドを利用します。
|
1 2 3 4 5 6 7 8 9 |
$ consul members Node Address Status Type Build Protocol lb-1 192.168.33.11:8301 alive server 0.4.1 2 lb-2 192.168.33.12:8301 alive server 0.4.1 2 web-1 192.168.33.21:8301 alive server 0.4.1 2 web-2 192.168.33.22:8301 alive client 0.4.1 2 web-3 192.168.33.23:8301 alive client 0.4.1 2 db-1 192.168.33.31:8301 alive client 0.4.1 2 db-2 192.168.33.32:8301 alive client 0.4.1 2 |
下準備2 - サービスの登録とDNSの設定
各種サービスをクラスタ内で認識できるように登録作業を行います。
なお各サービスは
- LB: HA Proxy
- Web: Apache + PHP
- DB: MySQL
で動作しているものとして話を進めていきます。
サービスの登録
Consulにはサービスを登録する方法として、設定ファイルで行う方法とAPIで行う方法があります。
設定ファイルで登録する場合は以下ようなフォーマットのJsonをAgent起動時に指定します。
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "service": { "name": "db", "tags": ["master"], "port": 3306, "check": { "script": "/usr/local/bin/check_mysql_master", "interval": "10s" } } } |
チェックスクリプトを指定することで、サービスの死活監視を行うことが出来ます。
なお、チェックスクリプトはAgentが動いているサーバで実行可能なものであれば言語を問いません。
死活監視はこのスクリプトのExit Codeを見て
- Exit code 0 - Check is passing
- Exit code 1 - Check is warning
- Any other code - Check is failing
のように判定します。
Sensuなどのプラグインと互換性があるためhttps://github.com/sensu/sensu-community-pluginsなどから流用することも可能です。
DNSの設定
サービスを登録すると、APIおよびDNSから参照することが出来るようになります。
APIおよびDNSは全てのConsul Agentがデフォルトで8500ポート(API)および8600ポート(DNS)から提供しています。
また、これらのポートは自由に変更することができ、DNSを53ポートで提供する際は以下のように設定ファイルを記述して、Agent起動時に指定します。
|
1 2 3 4 5 6 |
{ "ports": { "dns": 53 }, "recursor": "8.8.8.8" } |
このDNSはクラスタ内のサービスについて名前解決してくれるもので、たとえば、'lb' というサービス名の場合、lb.service.consul で名前解決してくれます(死活チェックでfailingになるものは除かれます)。
dig コマンドで問い合わせるとAレコードが返ってくることが確認できます。
|
1 2 3 4 5 6 7 8 |
$ dig @127.0.0.1 -p 53 proxy.service.consul. ANY -- 省略 -- ;; ANSWER SECTION: lb.service.consul. 0 IN A 192.168.33.11 lb.service.consul. 0 IN A 192.168.33.12 -- 省略 -- |
なおAgentが提供するDNSはクラスタ内のサービスに対する名前解決しか行いませんが、recursor に外部のDNSサーバを指定することで、名前解決が出来なかった場合は、外部に問い合わせるようになります。
また、/etc/resolve.confなどに127.0.0.1を指定することでdigコマンド以外でも名前解決が出来るようになります。
つまりクラスタ内の全サービスに対して名前ベースでアクセスすることが可能になります。
以上で下準備は完了です。
以降からオーケストレーションのための設定をしていきます。
LBの設定を自動化する
HA Proxyでは振り分け先となるWebサービスのIPを記載した設定ファイルを用意する必要があり、追加や削除を行う場合は設定ファイルを書き換えてリロードする必要があります。
たとえば、あるWebサービスに障害が発生したとします。
障害が発生したサーバへのアクセスは止めなければならないので、
- 設定ファイルから障害が発生したサーバを除く
- LBを再起動する
- 上記対応を全LBで実施する
といった作業が発生します。
また、負荷対策などでWebサービスをHA Proxy配下に追加するときも時も同じような作業が発生します。
これらの作業を自動化するために、Consul-templateというツールを利用してみます。
Consul-template
Consul-templateを利用すると以下の様なことが出来るようになります。
- クラスタ内の変化(サービスの状態変化やKVS※の変化)を検知する
- テンプレートからクラスタ内の情報を利用して設定ファイルを生成する
- 任意のコマンドを実行する
※Consulにはクラスタ内で共有して利用可能なKey/Value Storeがあります。
たとえば、HA Proxyの場合以下の様なテンプレートを用意します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy user haproxy group haproxy daemon frontend main *:80 default_backend web backend web balance roundrobin{{range service "web"}} server {{.ID}} {{.Address}}:{{.Port}} check{{end}} |
これはHA Proxy用の設定ファイルにテンプレート用の設定を加えたものです。
backend ディレクティブのところをConsul-templateで動的に生成するようになっており、この場合WebサービスのIPアドレスとポートを列挙するようになります。
なお対象となるサービスは死活チェックを通ったものに限定されます。
このテンプレートファイルを haproxy.ctmpl という名前で保存しておき、下記のようにConsul-templateを起動します。
|
1 2 3 |
$ sudo consul-template\ -consul=localhost:8500\ -template=/vagrant/haproxy.ctmpl:/etc/haproxy/haproxy.cfg:"/etc/init.d/haproxy reload" |
これで、Consul内の変化を検知すると haproxy.ctmpl から haproxy.cfg を生成し、HA Proxyをリロードするところまでやってくれます。
つまり、Webサービスで障害が発生し、死活チェックでfailingになると、それを検知して自動的にLBから抜かれます。
新規追加する際も、新しいWebサービスが検知されると自動的にLBに挿入されます。
ちょっと変わり種ですが、以下の様なテンプレートにしても面白いかもしれません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy user haproxy group haproxy daemon frontend main *:80 default_backend web backend web {{$state := (key "service/web/state")}} bind *:{{if eq $state "green"}}8080{{else}}80{{end}}{{range service "blue.web"}} server {{.ID}} {{.Address}}:{{.Port}}{{end}} bind *:{{if eq $state "green"}}80{{else}}8080{{end}}{{range service "green.web"}} server {{.ID}} {{.Address}}:{{.Port}}{{end}} |
これは、KVSに現在のWebサービスの状態(blueまたはgreen)を保持しておいて、それぞれblueまたはgreenでタグ付けされたWebサービスを有効にするためのテンプレートです。
状態がblueの場合はblue.webは80ポートからアクセスでき、greenは8080からアクセス出来る状態となり、KVSの内容を変更することでポートが切り替わるため、blue-green deploymentが出来たりします(現実的かは置いておいて柔軟な使い方が可能というわけです)。
余談をはさみましたが、LBの設定の自動化は以上で完了です。
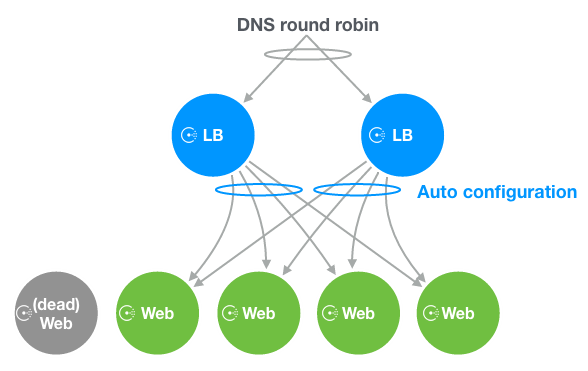
ここまでの構成
DBの運用を自動化する
DBについてはSlaveとMasterに分けて自動化の話を進めていきます。
DB Slaveへの参照を名前ベースで行う
MySQLにかぎらずDBのSlaveはRead Onlyであることがほとんどであり、あまり気にせず並列度を上げることが出来ます。
ただし、WebからIPアドレスベースで接続するような設定になっていると、並列度を上げたところでWebサービス側でも対応しなければならず、数が多いほど大変な作業になります。
HA Proxyを前段に挟むというアプローチでもいいかもしれませんが、先ほどのLBの例とかぶるので、今回はDNSによるアプローチを試してみます。
各種サービスがクラスタ内に登録されていれば、各Webサービスから slave.db.service.consul でDB Slaveへのアクセスが可能になります。
|
1 2 3 4 5 6 7 8 |
$ dig @127.0.0.1 -p 53 slave.db.service.consul. ANY -- 省略 -- ;; ANSWER SECTION: slave.db.service.consul. 0 IN A 192.168.33.32 slave.db.service.consul. 0 IN A 192.168.33.33 -- 省略 -- |
なのでWebサービスでの対応はIPアドレスベースで参照していた箇所を slave.db.service.consul に変えるだけで済み、SlaveへのアクセスがDNS round robbinで分散される事になります。
これで、Slaveに障害が起きた場合はDNSによる名前解決の対象から自動で外れ、新規に追加する場合は名前解決の対象に自動で追加されるようになります。
DB Master障害発生時の手順を自動化する
DB Masterに障害が発生した場合、DB SlaveをMasterに昇格(フェールオーバー)させる必要があります。
MySQLの場合は
- Masterからbinary log eventsを取得(可能であれば)
- Slave群から最新のものを選択
- 最新のデータをSlave間で同期
- Masterから取得したログを適応してMasterに昇格させる
といった作業が必要になります。
ただしこれらの作業は言葉でいう以上に複雑な処理となりますので、もし既にフェールオーバー用のツールやスクリプトが存在するのであれば、Consulによって障害を検知して、
それらをフックしてあげるのが妥当なアプローチかと思います。
Consulには監視対象を指定して、変化があった場合にスクリプトをフックするためのwatchというコマンドがあります。
|
1 |
$ consul watch -type service -service master.db /user/local/bin/mysql-failover.sh |
なおMHA for MySQLを利用すると、Consulによるスクリプトのフックも不要になります。
また、MHAはフェールオーバーが完了した際に、任意のスクリプトをフックする仕組みが備わっているので、Consulに対して新DB Masterのサービス登録を行うようなスクリプトをフックするようにすればMHAとConsulがシームレスに連携できるはずです。
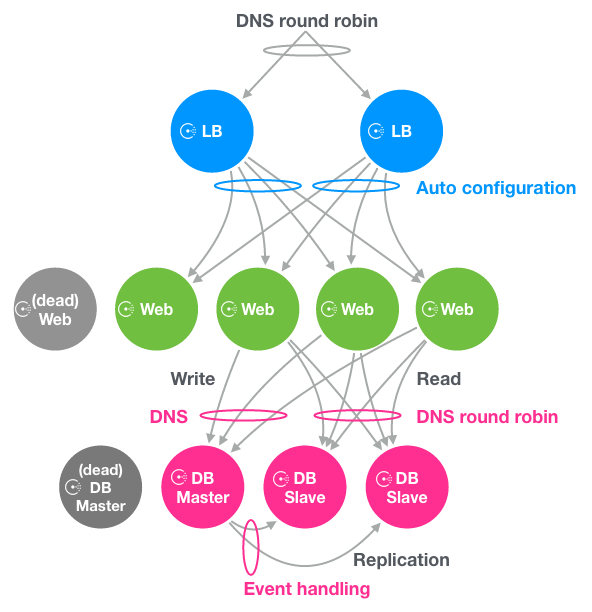
最終的な構成
自動追加に対する不安の解消
運用を自動化するにあたって、"期待通りに動くかどうか" 不安になることがあると思います。
特にWebサービスやDB Slaveの追加に関しては、それらが正常に動いているか担保した上で自動追加されなければなりません。
そんな不安を解消するためにConsulの死活監視スクリプトの内容を工夫してみます。
例えばWebサービスの死活チェックが
- Apacheが正常に動いている
だけだったらどうなるでしょうか。
内部のPHPのアプリケーションがどうであれ、Apacheさせ正常に動いていれば、Webサービス全体が正常とみなされてHA Proxy配下に置かれてしまいます。
なので自動化の不安は
- Apacheが正常に動いている
- PHPのアプリケーションが正常に動いている
- 接続しているMySQLが正常に動いている
- 各種ハードウェア(CPU, Memory, Diskなど)が正常に動いている
のように、より厳密にチェックすることで解消できると思います。
※ 上記以外にもチェック項目はあると思います。
まとめ
本エントリでは、簡単なWebシステムを例にとって、Consulやその周辺ツールの基本的な使い方やオーケストレーションする仕組みについて説明しました。
今回は話を単純にするために簡単な例で説明しましたが、Consulは汎用的なツールであり、様々な利用方法が考えられます。
身の回りで手作業による運用を行っている部分があれば、Consulやその周辺ツール(もしくはConsul以外のツール)によって解決できないか考えてみると案外簡単に出来るかもしれません。
本エントリで世の中の手作業による運用がひとつでも自動化できる事を期待しています!
明日の記事はインフラストラクチャ本部の堀口さんです。お楽しみに!
関連リンク
- Consul
- Consul: Service Oriented at Scale
- progrium/registrator
- Serf / Consul 入門 ~仕事を楽しくしよう
- Introducing Consul Template
- ConsulによるMySQLフェールオーバー
- #10 Consulと連携するpull型デプロイツール stretcher
- Service Discovery & Orchestration With Mesos and Consul
- Comparing ZooKeeper and Consul
- DockerコンテナをConsulで管理する方法