こんにちは、佐島です。 昨年に引き続き、テックブログ執筆者を称える社内イベント「Engineers' Blog Awards 2026」を開催しましたので、ご紹介します。 (開催背景などは2024年のブログをご覧ください […]
こんにちは、佐島です。 GREE Engineers' Bash 2026 という社内限定イベントが昨年に引き続き開催されましたので紹介させていただきます。 (GREE Engineers' Bash については2018 […]
こんにちわ。せじまです。 こないだ知人と集まって話をしたとき、私がむかしから意識してやってきた(つもり)の話をしたところ、「こういった話こそblogに書いたら良いのでは」といわれたので、ふわっと書いてみました。 (きっと […]
こんにちわ。せじまです。 むかしむかし、社内勉強会で話した内容を公開させていただくということが何度かありました。 TIME_WAITに関する話 EthernetやCPUなどの話 CPUに関する話 先日、社内で「データベー […]
こんにちわ。せじまです。 2025-10-21 にリリースされた MySQL 9.5.0、個人的には久しぶりに Innovation Release だなと思わされる変更が入ってました。 MySQL :: MySQL 9 […]
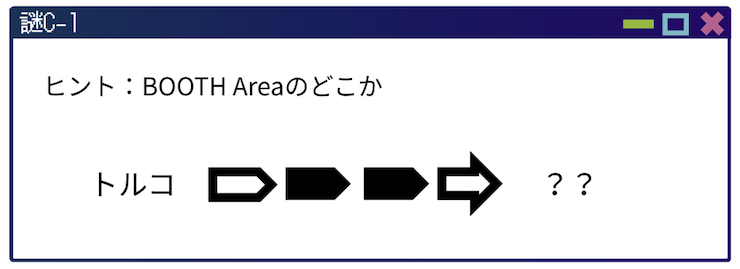
こんにちは!GREE Tech Conference 2025 謎解き運営チームです。 はじめに GREE Tech Conference 2025にご参加いただいた皆さま、誠にありがとうございました! 今年も大好評だっ […]
こんにちは。開発本部 インフラストラクチャ部の山下です。 8/25 - 8/27 にタイ・バンコクで開催された DEXA という国際会議に参加 / 発表してきましたので、その報告をさせていただきます。 はじ […]
こんにちは。DevPRチームの佐島です。 10月17日(金)、グリーグループの技術チャレンジを紹介する GREE Tech Conference 2025 を、東京ミッドタウンとYouTube Liveのハイブリッド形式 […]
こんにちは! GREE Tech Conference 2025 謎解き運営チームの日高です。 昨年、初めて開催したGREE Tech Conference 2024での謎解きイベントは、予想を上回る大好評をいただきまし […]
こんにちは、佐島です。 昨年に引き続き、テックブログ執筆者を称える社内イベント「Engineers' Blog Awards 2025」を開催しましたので、ご紹介します。 (開催背景などは昨年のブログをご覧ください。) […]