プロダクトにおけるAI活用(1)
みなさんこんにちは、鈴木です。
Web向けゲームを開発する仕事をしています。
会社ではtkcと呼ばれています、どうぞよろしくお願いします。
さて今回は、プロダクトにおけるAI活用ということで、Deep Learningを用いたプロダクトバナーのレコメンデーションシステムについてご紹介します。
といっても、僕は機械学習の専門家でもなく、趣味で触りながら業務に活かせる部分を使っていくスタンスなので、間違った認識のところはご指摘いただけると幸いです。
世の情勢的に、技術的な話題か、ビジネス活用の概要的な話題が多い印象なので、本記事では現場目線の技術/ビジネス両面のお話ができればと思っています。
では早速、このシステムを開発するに至った経緯からご説明していきます。
ざっくりと背景
僕が開発担当しているプロダクトでは、ガチャが並行で最大9つリリースされています。一般的なプロダクトと比較して多い印象ですね。
9つのガチャのうち、お客さまによって購入したい商品はもちろん別々ですが、訴求バナー枠は3つしかありません。
これまでは以下のような問題を抱えていました。
- 原則、バナーは均等にランダム表示されるため、訴求力が十分ではなかった
- バナー枠の表示順位もランダム要素があるため、本当に訴求したい商品がファーストビューに入りにくかった
- 個別に訴求したい商品がある場合、手動で配信比率を調整する作業が発生していた
- 配信比率はサービス全体で固定なので、「A商品」の比率を上げた場合、「A商品」を購入したい方には有効だが「B商品」を購入したい方には効果が薄かった
そこで、バナー最適化によるクリック数値と消費の向上と、入稿作業の工数削減を目的として、バナーのレコメンデーションシステムをDeep Learningを用いて作成することにしました。
直近の消費履歴・プレイ履歴より、お客さま一人一人の好みを学習して、消費期待値の高い商品を推薦する機能です。
なぜ別のアルゴリズムでなくDeep Learningを利用したかは、後述しています。
使った技術
今回はTheanoとTensorFlowのラッパーライブラリのKerasを利用しました。
今月Kerasが2.0にupdateされて、TensorFlow連携もしやすくなり注目度も高まってきていますね。最近は関連の記事も増えてきているので、学習コストも低いのもありがたいところです。
実は、以前はTensorFlowでシステムを書いていたのですが、以下のような個人的な見解でKerasを選択しました。
- コード記述が直感的で読みやすかったこと
- バックエンドをTheanoとTensorFlowで自由に切り替えができること(学習精度や時間がTensorFlowとTheanoで多少変わるので、場面によって使い分けています)
Kerasはプロトタイプ作成やデータ学習などを、一番スピード感もって進められると感じています。
データが多ければ、GPUインスタンスを使っても24時間学習に時間がかかることも珍しくないので、開発段階は精度よりもスピードを大事にしています。
導入段階ではもちろん精度も重要になるので、最終的なアルゴリズムやパラメータで繰り返し学習させています。
では、実装的な話をしていこうと思いますが、Kerasの導入部分はQiitaに記事がたくさんあるので割愛して、学習データからご説明します。
学習データの取得
学習データは、社内のHadoopクラスタ上に保存しているデータを、アルゴリズムが取扱えるフォーマットに整形しています。
直接Hadoop上からデータを読み取ると出力が1千万レコード級になってしまい、社内システムに高負荷をかけてしまうので、HDFSエクスプローラ経由でファイルをダウンロードするようにしています。
Deep Learningにおけるデータの量と質は非常に重要で、正解率に大きな影響があります。
今回のシステムにおいて、全く同じモデルで1/10のデータ量を用意して比較したところ、10%程度の差が出ました。元のデータがいかに重要か感じますね。
とはいえ、学習データに過度に情報を持たせても学習時の待ち時間が増えてしまうので、ある程度の取捨選択は必要でここの線引きはなかなか難しいところです。
もうひとつ注意した点としては、学習データのラベル数の均等性です。
一部のラベルが極端に多かったり少なかったりすると、精度高く予測する事ができないです。今回は学習データが十分にあったため、過剰なラベルデータは削除して対応しました。
データ量が少ない場合は、貴重なデータを削除するのはもったいないので、データの水増ししたりもできますが、今回のモデルでは実施していないので、これはまた別の機会でお話ししようと思います。
今回は過去数ヶ月分のユーザーのプレイ履歴・消費履歴と、その時に開催していたガチャのマスター情報をマージして学習データとしています。
ラベルには分類したいデータを使用するので、「その日の一番消費額が高かったガチャ種類」をラベルにしています。
ということで、今回の場合は教師あり学習の多クラス分類問題になります。
モデルの選定
Deep Learningにおいて、モデル設計が一番難しいところです。
精度を上げようと思ったら、様々なアルゴリズムやハイパーパラメータ調整やモデル選定などやることが多く、手探り感がありました。
ただ、画像系や回帰・分類などでパターンがある程度決まっているので、そこそこ(70%前後)の予測精度を出すという意味では、気軽に触ってみて予測できるのが素晴らしいですね。
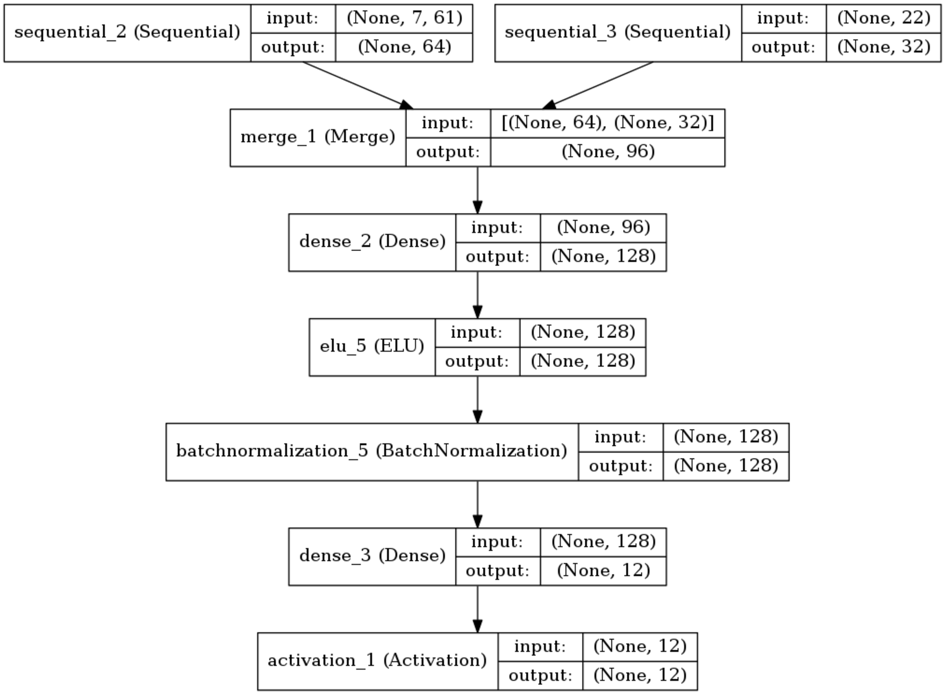
今回使ったモデルは、複数日数の時系列データを画像として処理しようと思い簡易版VGGとLSTMを用いて学習させました。
時系列データなのに簡易VGGを利用したのは、Deep Learningでは画像認識が強いこともあり、時系列で行列データを重ねてN次元の画像とみなしてみようという試みです。
単にLSTMだけとかCNNだけとか複数のアルゴリズムで実装してみましたが、今回は上記のモデルが一番精度が高かったです。
結果
上記のデータとモデル調整で、過去の未学習データの一部を予測させたところ正解率は86.8%ほどでした。
精度は高ければ高いにこしたことはないですが、100%正しいバナーを表示する必要はないので、この精度でも十分だと判断しました。
|
1 2 3 4 |
-- result -- total: 3030 correct: 2631 , correct_rate: 86.83168316831683 in_correct: 399 , in_correct_rate: 13.16831683168317 |
さて気になる導入結果ですが、どれだけ効果があったかクリック系の数値を共有します。
比較しやすいようにABテストを実施しました。
旧ロジックのままユーザーと、新ロジックを適用したユーザーのクリック率(クリックしたUU/表示したUU)が下記グラフで、旧ロジックのクリック率を100%として、それと比較して新ロジックがどれだけ数値が違うかを表しています。16日目より切り替え実施しています。
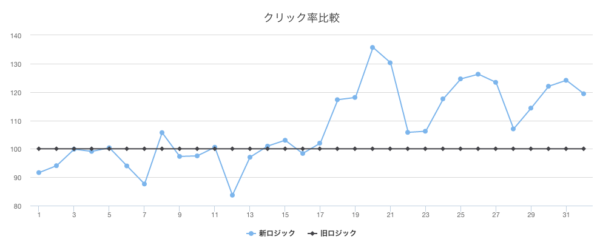
比較すると、もともとは新ロジックの方がややクリック率低かったものの、切り替え後からは旧ロジックと比較して約20%程度数値が高くなっていることが確認できます。
特定の商品を期待値の高いユーザーに対して適切にレコメンド表示され、数値が上がったと考えられます。
数値としても成果が出たことと、今まで人力でバナー入稿作業されていた部分が全自動化できたことで、AI導入は有効な事例でした。
AI利用するメリット・デメリット
どれも議論があるところだと思いますが、個人的には下記のメリット・デメリットがあると考えています。
AIというかDeep Learning限定な話も入っていますが。
メリット
- 高いメンテナンス性
- 途中でゲームバランスが変わった場合でも、同じモデルのまま再度学習させれば、予測値を新しいステージに適応できる
- 単なるルールベースでも工夫次第でメンテナンス性は良くできるのはありつつ、AIであればそこに時間を割かなくてもよい
- 人が考えなくて良いこと
- AIだとデータに対しての特殊量抽出を自動でやってくれる
- 人間であれば、このパラメータの影響度大きいから個別に重み付けを調整したりするが、AIだとそれがない(もちろん調整もできる)
- モデルのパターンが決まっているので、一度導入したモデルを他でも汎用利用できる
- 高い精度
- 十分な量・質のデータと適切なモデル設計さえあれば、誰でもある程度の精度を出すことができる
- AlphaGo(人間の世界トップ囲碁棋士をハンデなしでAIが破った話)など、その分野の専門知識がなくても、非常に高い精度を叩き出すことも可能
デメリット
- 費用面
- GPUインスタンスはやっぱり高い
- 学習中だけ自動的にインスタンス起動・停止をするscale runという仕組みもあるので、工夫の余地はある
- リソース不足になりがち
- GPUメモリ不足問題で、少ないインスタンスでは並列に複数学習をさせるのが難しい
- リソースを増やすと費用も増える
まとめというか所感
最近、機械学習や人工知能への世間の注目が集まり、業界全体でAI導入への温度感が高まってきています。
ただ僕個人としては、きちんとした理解なしにこのトレンドに踊らされるのは危険だなと感じています。
なぜなら、自動化はAI以外でも進められますし、AI導入は学習工数やリソースも考えるとそれなりのコストがかかるからです。AIとAI以外でやることをきちんと選定しておくことが大事だなと思います。(エンジニアとしてはチャレンジできる範囲が広がって楽しめるのはありますが)
つまり、AIは目的を実現させるための一手段であって、AI導入自体を目的として考えると危ないな、と。
そんなこと言いつつですが、人がやらなくてもいいルーティンワークの自動化を加速させるのにBigDataやAI(特にDeep Learning)が活用されていくのは間違っていないなとも思っています。
というのも、僕の実体験でいうと、Deep Learningは機械学習的な深い知識をあまり必要とせず(大きな学習工数をかけず)に、既存のモデルで70-80%の精度でデータ予測することができます。(もちろん専門的な知識があればより精度があがります)
運用プロダクトにとっては、こういったAI活用による業務効率や事業利用の導入事例を量産できるのは、ビジネスへの利用価値が十分にあるなと感じました。
世に新しい論文や理論がどんどん出ているので、ライブラリに反映される前にいろいろ試せると幅が広がりそうですね。(僕はまだできていないですが)
幸いAI導入に対しての敷居が低くなっているので、ぜひぜひ触ってみるといいのではないでしょうか。
今後も機会があれば、別の導入事例の紹介をしたいなと思っています。
それでは、Happy Hacking :)