美容サイトARINEで稼働中の機械学習を用いた髪型ネイル識別システム
応用人工知能チームの尾崎です。今年新卒エンジニアとして入社し、機械学習モデルの実装評価からAPIサーバの実装、コンテナを利用したプロダクトへの導入まで開発全般を担当しています。
今回はARINEで稼働中の畳み込みニューラルネットワーク (CNN) を用いた髪型・ネイル識別システムについてご紹介します。
背景
ARINEでは、おすすめのヘアスタイルやトレンドのコーディネートなど沢山の記事が公開されています。記事には数多くの写真素材が用いられていますが、これらの素材の多くは提携サイトから検索APIを提供してもらったり、提携サイト内の検索機能を用いて写真素材を探し選んでいました。しかし、一部の写真素材は自社で撮影していたり、最近ではヘアサロンやネイルサロンからも提供してもらっているため、それらの画像を検索する手段がありませんでした。
そこで今回、ライターさんが執筆に必要な写真素材を手軽に検索できるよう、ファイルサーバにアップロードされた写真に自動的にタグ付けを行うシステムを開発しました。
全体のシステム構成と実装タスク
おおまかなシステム構成は以下のようになっており、実装を行ったのは赤線で囲まれた識別器サーバです。
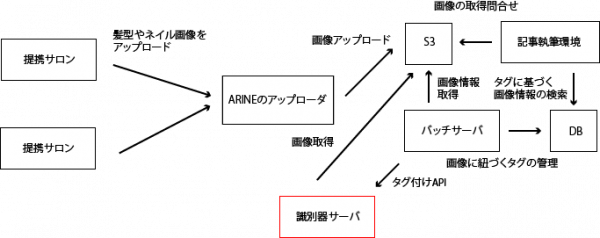
全体のシステム構成 (ヘアサロンやネイルサロンから写真がアップロードされる想定)
実装タスクは以下の3つです。
- 画像を入力としてタグ付けに必要な情報を返す識別器
- リクエストを受け付け、画像ファイルを取得し、適切な識別を実行し、結果を返すAPIサーバ
- Amazon EC2 Container Serviceにデプロイする為に必要なdockerコンテナ化
識別器
記事に用いられる写真の種類と属性は数多くありますが、必要性に応じて優先度付けを行い、まず以下の項目に関してタグ付けを行うことにしました。
- 髪型 (ショート、ボブ、セミロング、…)
- 髪色 (黒髪、茶髪、オレンジ、…)
- ネイル種別 (手、足)
- ネイル色 (黒、赤、青、…)
今回は、識別タスクごとに識別器を実装することにしました。
髪型識別器の実装
モック実装
典型的な画像識別タスクかつ、タグ付けはバッチ処理で行われるため識別にリアルタイム性も必要ないため、迷わずCNNを用いることにしました。
学習データは識別タグを検索キーワードとして用いてWebスクレイピングを行い画像を5000枚程度収集し、明らかに不適切なものを手作業で後から除外することで準備しました。
手始めに、モデルとしてVGG-likeなCNN (層数削減、バッチ正則化を導入) をKerasを用いて実装し、典型的な前処理 (正規化) ・データのかさ増し (rotate, crop, shift) を行った上で学習・評価を行いました。しかし、validationデータの識別性能は序盤からほとんど良くならず8クラス分類で30%程度でした。
実装改良
識別性能が出なかった理由としては、モデルの貧弱さ、学習データの質と量の不足等様々な要因が考えられますが、序盤からほとんどvalidationデータの識別性能が向上しなかった様子から、意図した特徴 (= 髪型) が獲得できておらず、背景などからtrainingデータだけを上手く識別できる特徴を獲得してしまったのではないかということを疑いました。
そこで、髪領域だけを予め抽出する前処理を行うことで識別性能の改善を試みました。ヘアモデルの写真は利用目的の性質上、多くの場合好ましい照明条件のもと髪が鮮明に写る背景で撮影されているので、HSV表色系に変換した後k-means法 (正確には改良されたk-means++法) を適用することで髪領域をうまく分離することができました。
(大抵の場合、k = 3~5程度で、背景、髪、肌、服などに分離できました。)
| input | output1 | output2 | output3 |
|---|---|---|---|
 |
 |
 |
 |
この結果から、髪領域だけの学習データを選別し、改めてCNNを学習することで、髪型識別精度を70%以上に改善することができました。
k-meansの場合、分離したクラスタのうちどれが髪領域であるかが判らないので、さらに髪領域か否かを判別する2値分類器をCNNで実装し、最終的には入力画像にk-meansを適用、CNNを用いて最大髪領域尤度の画像を抽出、CNNを用いて髪型識別という風に、識別器を積み重ねることで70%程度の識別精度を達成しました。誤りも、ミディアムヘアとセミロングの誤識別など人間にとっても難しいものが多く、露骨な間違いは少ない印象です。

髪型識別システムのアーキテクチャ
ネイル色識別器の実装
ネイル色識別器の実装も、髪型識別器と同じく領域抽出とカラー識別を積み重ねています。ネイル色識別器の場合は領域識別にはk-meansの代わりにselective search、色識別には基準色からのCIEDE2000色差に基づくカラーヒストグラムを用います。こちらは90%以上の精度で代表的なネイル色を識別できています。
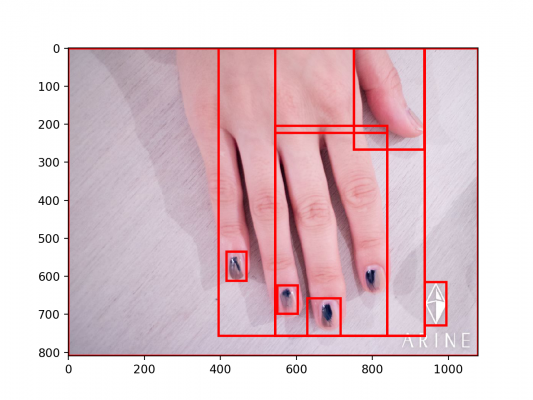
selective searchによって爪候補領域が得られる

ネイル色識別システムのアーキテクチャ
その他の識別器も、同様にして細かい調整を行いつつ実装しています。
APIサーバ
サーバの実装として特筆すべきことはありませんが、APIは識別タグを返すのではなく各識別クラスに対する尤度を返すようになっています。これは、識別器は絶対に間違えることがあるのでクライアント側で結果の扱いを以下のように柔軟にできるようにするためです。
- しきい値未満の尤度であれば棄却する
- 尤度の高い上位N識別クラスまでのタグを表示する
コンテナ化
識別器を利用するプロダクトのエンジニアが、一切内部実装や依存に関して気にかける必要がないよう全てdockerコンテナ化しています。APIサーバはECS+ECR環境上でデプロイされ、必要に応じてモデルのアップデートや複数台立ち上げるといったことが簡単にできるようにしています。
また、Dockerfileのベースイメージの切替などを行うことで、簡単にGPUを用いる/用いないを変更してイメージをビルドできるようにしています。
まとめと所感
ARINEにおける画像認識事例について紹介しました。CNNをはじめ教師あり学習を用いる場合、十分な学習データの質と量を担保できることが理想ですが、必ずしもそうもいきません。そういった場合、タスクを相対的に簡単なタスクに分類し、それらを解決する小さな識別器を積み重ねることで、問題をうまく解決できることがあります。Deepでend-to-endなアプローチは格好良いですが、時間的・金銭的コストを踏まえそれが現実的に無謀でありそうな場合は諦める判断も必要です。
今回は画像の前処理や教師データの作成に教師なし学習をうまく用いることで実装の労力を削減することができました。こうした作業の効率化は様々なケースで汎用的に使うことができると思います。
また、課題として
- コードレビュー・性能テスト
- 識別器や前処理の実装などレビューできる人がチーム内に限られていた
- 性能評価、パラメータ調整が属人化しがち、もっとアルゴリズミックにしたかった
- データセットの作成
- ラベル付けを沢山行うのは骨が折れた
- 開発リソースの制約
- 学習時間やGPUメモリが多く必要なモデルを試すこと、大規模なハイパパラメータ最適化実験等は現実的でなかった
といった点があると感じたので次回以降可能な範囲で改善していきたいと感じました。