Scalaコードでわかった気になるDDD
みなさん、こんにちは。グリーのかとじゅん(@j5ik2o)です。
このエントリは GREE Advent Calendar 2013 の 18日目の記事です。よろしくお願いします。
私がグリーに入社してやっていることは、プログラミング言語 Scalaとドメイン駆動設計(以下、DDD)の布教活動です。布教活動といっても宣伝するだけでは具体性に欠けるので、実際に開発チームに入ってScalaやDDDの技術支援を行っています。本エントリでは、Scalaを用いたDDDの設計と実装をどのように行っているかを、DDDを知らない人でもできるだけわかりやすく説明したいと思います(Scalaわかっていると読みやすいですが、あんまり複雑なコードは出てこないのでなんとなく読めるのではないかと思います)。なお、DDDの実践例は他にもあります。一例だと思って読んでいただければ幸いです(先日のSNSチームでのドメイン駆動設計の実践も読むと参考になるかもしれません)。

DDDとは
DDDとは、その名のとおりドメインを中心に考えた設計手法のことです。ちょっと難しい表現になりますが、そのドメインとは、そのソフトウェアが扱う、”何らかの活動や関心と関係がある知識”のことなのですが、それを中心に考えて設計していく手法です。うーん、なんだかわからない表現ですねw
もう少し具体的な例でいうと、ロールプレイングゲーム(以下 RPG)では、「プレイヤー」「モンスター」「アイテム」「武器/防具」「街」「ダンジョン」など様々な概念が含まれます(一般論として)。これらの概念を、RPGの世界観の”言葉”を使って”ドメインモデル”というオブジェクトを表現していきます。プレイヤーとは何か?どんな特徴があって、何ができて、何ができないかなど。その言葉はDDDではユビキタス言語と呼ばれ、ドメインモデルと対応します。それらのドメインモデルを”実装”に紐づけることによって、ソフトウェアの最終目的を達成します。RPGでは「ラスボスを倒して世界を平和にする」という目的などです(当然大目的をクリアするための中小の目的はありますが)。
それだけ重要な要素なのですが、実際の開発現場では様々な理由でそれらの知識が実装コードの中に埋没してしまいがちです。コードを読んでも設計の意図がなかなか伝わってこないというのは無理もないと思います。では、ドメインの知識を反映したソフトウェアを作るにはどうしたらよいでしょうか?ひとつの方法論がDDDです(こういうと万能そうに聞こえますが、DDDは複雑な問題をドメインモデルを使って解くため、簡単な問題には向きません。問題にあった解決手法を選びましょう)。
なぜDDDを採用したのか?
私のチームで採用した理由は次のとおりです。
- ある程度 複雑な問題を扱う、基盤的なシステムであったため、費用対効果は見込めると考えた。
プロトタイプであったり、それほど手を掛けるつもりもないシステムには向かないのは事実ですが、しっかり作り込んで育てていくようなシステムには採用できると判断しました。
- エンジニアだけではなくディレクターや企画などの非エンジニアも含むチームメンバーが共通言語を使って同じ目線でものづくりがしたい。
開発側と企画側という対立軸を作らないための共通言語を決めて、チームメンバー全員でドメイン上での問題解決という最終目的を共有したかった。
- 私がチームに加わったので半強制的にそういう流れになった、というのが大半の理由?w すみません...。
ここからは、仮想的なプロジェクトを例に実際のモデルの作り方を説明します。
シナリオからモデルを導き出す
DDDを始めるには何から始めればよいでしょうか?
DDDにはModel Exploration Whirlpoolというモデルを探索するためのプロセスが定義されています(これは本書には記載されていません)。それによると、シナリオからになっています。シナリオとはモデルの使い方を表したものです。
{kind=link}
たとえば、"ハンターがモンスターを狩る"ようなゲームのドメインを考えてみましょう。次のようなシナリオが考えられます。
- ハンターは、武器を使ってモンスターに攻撃することができる。
- ハンターは、アイテムを使うことができる。
- ハンターは、他のハンターにアイテムを渡すことができる。
ほんの一部だけですがドメインの世界が見えます。少なくとも、「ハンター」「モンスター」「アイテム」はモデルの候補になりそうです。
言葉の探し方
シナリオと言われてもピンとこないかもしれません。最初は私もそうでした。ゲームだと割と世界観が決まっていて、モデルのイメージが付きやすいのですが、業務システムでは専門知識を持った人(DDDではドメインエキスパートといいます)であったり、その分野の専門誌などからヒントを得る方がよいでしょう。また、新しい分野のドメインでは、ドメインエキスパート自体が存在していないこともあります。その場合は自分たちがソフトウェアエキスパートであり、ドメインエキスパートでもあるという心構えが必要になるでしょう。
あとは、ユーザーストーリーなどからモデル候補を探すというところからやるといいと思います。ユーザーストーリーの表現はユーザ目線で大きい粒度なので、それだけでドメインモデルを完全に洗い出すのは難しいかもしれませんが、ユーザーストーリーを実現するための”言葉”はどんなものがありえるのか?というように、そこからブレイクダウンしていけばヒントにはなると思います。
シナリオに使われる言葉は実際にはあいまいな表現だったりするので、これもチーム内で相談して言葉を統一していきます。「ハンターとは何か?」という問いに答えを作ります。つまり、ユビキタス言語の定義です。設計とは国語の問題だったんですね!DDDで一番難しいのはこの言葉の定義だったりします。 ユビキタス言語を決めつつ、ホワイトボードなどを使いながら、モデルのイメージを共有していきます。こんな感じです。これでイメージが共有できたら、すぐにコードに落とします。コード例はのちほど紹介します。
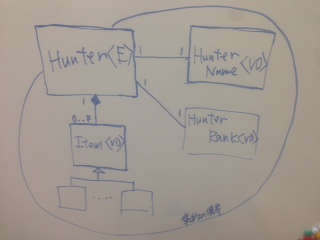
モデルを実装に反映する
前置きが長くなりましたが、みなさんが好きな実装の話です。 ここからは、ユビキタス言語で表現したモデルを実装に反映するための手法である、”モデル駆動設計”を簡単に説明します。実装の話になると、ウェブフレームワークだったり、データアクセスなどが気になりますが、ここではいったん忘れましょう(ちなみに、DDDに沿った実装を効率的に書くためにライブラリであるscala-dddbaseを利用しています。これ以降の例で登場する「Entity」、「Identity」などはscala-dddbaseのものを参照しています)。
モデルには3種類あります。エンティティと値オブジェクト、サービスです。ここからはそれぞれのモデルについて説明します。
見分けるためのエンティティ
まず、エンティティから説明します。エンティティは識別する(見分ける)ことを目的とするモデルです。例えば銀行口座へ振込では、日時・口座番号・金額という属性を見ただけでは、振込の同一性を検証できません。これを見分けられないというのは常識的にあり得ないので、振込という概念は見分ける対象ということになり、エンティティということになります。
エンティティの責務は、同一性を保証することです。付属する属性が変わったとしても同一性を保証します。例えば、人エンティティの属性である住所・身長・体重などは、時を経て変化します。名前も変わる可能性があります。子供の頃の属性は大人になると変化しているかもしれません。しかし、その人は同一人物であると見るモデルが、エンティティなのです。別の言い方をすれば、エンティティはアイデンティティを持っていると言えます。実装レベルの話で言えば、このアイデンティティは不変な識別子(ID)として表現するのが一般的です。
| コラム:アイデンティティの再利用について |
| アイデンティティの話は奥が深いです。例えば、人であれば生まれた時からアイデンティティが発生し、死んだ後も故人として残り続けます。ということは、私がジョブズに成り変わることはできないのです。当たり前ですが。つまり、エンティティのライフサイクルを終えても、そのアイデンティティは再利用できないということを意味します。たとえば、再利用され得る”電話番号”を信頼できる識別子として採用した場合、私が別人になれるかもしれません!採用するしないに関わらず、このようなリスクを考慮した上で設計のトレードオフをすべきだと思います。 |
このゲームの”ハンター”は、キャラクターの名前が同一であっても、別人かどうかを見分ける必要があるためエンティティです。おそらくモンスターもエンティティになると思われます(狩り中に同じ種類のモンスターが二頭でてきてもそれぞれを見分けて戦うため)。
Hunterエンティティの実装例は次のとおり。HunterエンティティはEntityを継承します。識別子には、Entityトレイトのidentityフィールドが利用されます。基本的には識別子をみれば見分けが付きます。しかし、コレクションフレームワークにエンティティが登録した際の利便性を考えて、equals, hashCodeはエンティティが持つ属性に基づく実装ではなく、識別子(identity)が同一かどうかだけで実装することが望ましいと考えています。
|
1 2 3 4 5 6 |
trait Hunter extends Entity[HunterId] { // val identity: HunterId val name: HunterName // モンスターに攻撃する def attack(methodType: MethodType.Value, monster: Monster): Try[(Hunter, Monster)] } |
エンティティの探し方
チームメンバーとシナリオを基に(なければ、ユーザーストーリーをヒントにして)エンティティから探していきます。ホワイトボードに向かって、チームメンバーと議論して、だいたいのイメージがついたら、すぐにトレイトに落とします。最初はホワイトボードにモデル図を書いて残していたのですが、次第にコードとの同期を取るのが面倒になったので、トレイトを図の代わりにしています。また、テストでモック化するときに実装が邪魔になることがあるので、トレイトを先に書く事を優先しています。
実装は次のようなイメージになります。
|
1 2 3 4 5 6 7 8 9 10 11 |
// コンパニオンオブジェクト object Hunter { def apply(identity: HunterId, name: HunterName): Hunter = new HunterImpl(identity, name) } private class HunterImpl(val identity: HunterId, val name: HunterName) extends Hunter { def attack(methodType: MethodType.Value, monster: Monster): Try[(Hunter, Monster)] = { // ... } } |
値を説明するための値オブジェクト
次は値オブジェクトです。これはエンティティとは違って、同一性を気にせずに値を説明することを目的にしたモデルです。
ハンターが使うアイテムで説明をした場合、回復薬などのアイテムはどういう種類のアイテムか、その効果、何個あるか?ぐらいしか関心が無いため見分ける意味がありません。このような特徴を持つモデルは値オブジェクトに属します。
アイテムを実装コードに落としてみると次のようなイメージです。同一性を示すような識別子はありません。その代わり、アイテムの特徴を表すような属性や振る舞いなどがあります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
// 値オブジェクト sealed trait Item { val name: String def beUsedBy(hunter: Hunter): Try[Hunter] } case class Analepticum() extends Item { val name = "analepticum" def beUsedBy(hunter: Hunter): Try[Hunter] = { // hunterを回復させる } } case class Antidote() extends Item { val name = "antidote" def beUsedBy(hunter: Hunter): Try[Hunter] = { // hunterを解毒させる } } class HunterImpl( val identity: HunterId, val name: HunterName, val items: Set[Item] ) extends Hunter { // ハンターがアイテムを使う def use(item: Item): Try[Hunter] = { require(items.exists(_ == item)) // 振る舞いをハンターに記述しない場合は // Visitorパターンを使えばよい item.beUsedBy(hunter) } } |
他の例も一つ。ハンターの名前を表すHunterエンティティのname属性はHunterName型でした。名前自体も同一性がなく値のみの表現です。例えば、あのハンターのKatoとこのハンターのKatoは、同じ名前なのか、違う名前なのか、いちいち気にしません。アイテムと同様に、値オブジェクトとして表現できます。
Scalaで実装するのは簡単で、case classとして宣言するだけです(case classで実装できるため、エンティティと違ってscala-dddbaseでは特別な型としては宣言していません)。case classのequals, hashCodeは、エンティティとは違って、コンストラクタ引数(firstName, lastName)が同値であるかによって実装されます。つまり、保持するすべての属性が同じかどうかで判断します。
|
1 2 3 4 5 6 7 8 9 |
trait HunterName { val firstName: String val lastName: String } object HunterName { def apply(firstName: String, lastName: String): UserName = new HunterNameImpl(firstName, lastName) } private case class HunterNameImpl(firstName: String, lastName: String) extends HunterName |
値オブジェクトを探す
エンティティが見つかったら、そこに属性を列挙していくのですが、初期のハンターは次のようなイメージかもしれません。ハンターの姓名やランクなどをそれぞれ保持している形式です。
|
1 2 3 4 5 6 7 8 |
trait Hunter extends Entity[HunterId] { val firstHunterName: String val lastHunterName: String val hunterRank: Int val hunterRankPoint: Int val nextHunterRankPoint: Int /// … } |
ここで、次のようなユビキタス言語を定義した場合のコード例を説明します。
- ハンターの名前は、姓と名が含まれる
- ハンターランクには、現在のランクと現在のランクポイント、次のランクにあがるためのランクポイントが含まれる
ユビキタス言語には、姓と名が含まれるので、次のように統一体としての値オブジェクト HunterName を作るとよいです(そういう概念がないなら、チームメンバーと議論して、ユビキタス言語に言葉を作りましょう)。
ハンターのランクについても同様です。そうすることでHunterエンティティもシンプルになり、より凝集度の高い値オブジェクトが実装できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// 名前に関する表現を行う値オブジェクト trait HunterName { val firstName: String val lastName: String } // ランクに関する表現を行う値オブジェクト trait HunterRank { val rank: Int val point: Int val nextRankPoint: Int } // 高凝集な値オブジェクトを持つエンティティ trait Hunter extends Entity[HunterId] { val name: HunterName val rank: HunterRank // } |
振る舞いを表現するためのサービス
最後はサービスです。サービスはどのようなモデルかというと、振る舞いを表すモデルです。振る舞いの中にはエンティティや値オブジェクトに属すると不自然な表現となるものがあります。そのような場合はサービスとして実装することがあります。
例えばハンターが、他のハンターにアイテムを渡す場合を考えてみます。ハンター自身が他のハンターにアイテムを手渡す場合は次のようなモデルになるのではないでしょうか?
|
1 2 3 4 5 6 7 8 9 10 |
class Hunter { // 成功した場合は、それぞれ新しい状態のハンターとして、 // Success(fromHunter, toHunter)が返される def transferItems(items: Seq[Item], to: Hunter): Try[(Hunter, Hunter)] = { // thisのitemsから引数itemsを減らす // to.itemsに引数itemsを増やす。 // これは手渡し側がすること? } // ... } |
そして、手渡し行為は実際には受け取る側の動作も伴います。しかし、渡す側が、受取手のアイテムポーチにアイテムを追加する動作は自然でしょうか?その振る舞いがHunterにはふさわしくないと判断した場合は、まだ見つけられていない他のモデルがないか探しましょう。それでも、落ち着き先が見つからない場合にどうするべきか。DDDでは、別途サービスに定義しそこに振る舞いを所属させます。サービスは振る舞いだけを表したモデルで、割と人工物的なイメージが強いです。
アイテム手渡しサービスのコード例は次のとおりです。
|
1 2 3 4 5 6 7 |
object ItemService { def transferItems(items: Seq[Item], from: Hunter, to: Hunter): Try[(Hunter, Hunter)] = Try { require(from.has(items)) (from.withoutItems(items), to.withItems(items)) } } |
これまでのモデルは"識別する(見分ける)"、"値を説明する"ためのモデルなので名詞的な表現でしたが、サービスは振る舞いを表すモデルなので動詞を表現するようなモデルです。また、振る舞いの名前はユビキタス言語と紐づく必要があり、入出力のための取るモデルはエンティティや値オブジェクトであるべきです。これらのオブジェクトが状態を持つため、原則的にはステートレスであるべきと言われています。
| コラム : サービスとするかしないか |
| 宙に浮いた振る舞いを、エンティティや値オブジェクトに属させるか、サービスに含めるかは、すごく難しいところです。 サービスを乱用すると、ドメインモデルから振る舞いを奪い去り ドメインモデル貧血症 に陥る可能性があります。しかし、強引に架空のモデルを作ったり、既存のモデルに押し付けたりするもの問題です。こうやれば解決という万能策はなかなかないので、私もいつも悩んでいます。どちらの設計判断をしたとしても、ユビキタス言語と関連がとれたモデリングをしてくことが現実的だと考えています。 とはいえ、人工的な手続きとしてのサービスではなく、エンティティや値オブジェクトなどのオブジェクトとして表現できないものか、とも考えます。蛇足ですが、DCIというプログラミングパラダイムは、手段の一つになるかもしれません。DCIには、ユースケースに応じた役割と振る舞いをドメインモデルに与えることで、ユーザのメンタルモデルに近づける考え方があるようです。たとえば、アイテムを渡すシーンで考えると、”アイテムを渡す”という場面(ユースケース)において、ハンター(ドメインモデル)それぞれに、”手渡す者(Sender)”や”受取る者(Receiver)”としての振る舞いを持つ役割(ロール)が与えられる、というな考え方です。ここでは詳しく説明しないので、興味がある方はDCIアーキテクチャ - Trygve Reenskaug and James O. Coplienを読んでみるとよいかもしれません。 |
ドメインモデルをグルーピングするモジュール
モジュールは、ドメインモデルをグルーピングするためのものです。これもモデルの一種です。オブジェクト指向言語でモジュールを実装するには、パッケージがよく使われます(パッケージがない言語でも、クラス名の一部にモジュールの名前を入れることによって実現可能です)。
モデルをどういう単位でグルーピングするかについてはいろいろなパターンがありますが、一番有名なのは以下のようにentity, valueobject, serviceなどのオブジェクトの種類によってモジュールを分けるパターンです(他にも、XXXLogic, XXXBeanによって分ける場合も同様のパターンに分類されます。このような分類方法を技術駆動のパッケージングといいます)。
- net.gree.xxx.domain.entity
- Hunter, Monster
- net.gree.xxx.domain.valueobject
- HunterName, HunterRank, Item, …
- net.gree.xxx.domain.service
- ItemService, …
DDDのモジュールでは次のように分けます。ドメインオブジェクトはユビキタス言語に紐づく世界です。モジュールの名前も例外ではありません。上の例では、モジュール名がentity, valueobject, serviceでした。そのような言葉は、ユビキタス言語にないので命名できないのです。ここではハンター関連のモデルにはhunterモジュール、モンスター関連にはmonsterモジュールとしています(ドメインモデル群の上位概念が見つかるのであれば、その言葉を使う方がよいかもしれません)。
- net.gree.xxx.domain.hunter
- Hunter, HunterName, HunterRank
- net.gree.xxx.domain.monster
- Monster
- net.gree.xxx.domain.item
- Item, ItemService
| コラム : ドメインモデルはユビキタス言語でグルーピングする |
| 私も慣れないうちは、オブジェクトの種類によってグルーピングしていました。何が不都合かわからなかったというのが正直なところでした。でもよく考えてみると、概念的に同じグループに属するドメインモデルを考えるときに、複数のパッケージを行ったり来たりして、モデルのイメージをつなぎ合わせていることに気づきました。さらに悪いことに、パッケージ間の依存関係は密結合になってしまいました。ということで、テストコードも書きにくい状況を作ってしまいました。そもそも実装技術の文脈で表現されない、ドメインモデルを技術駆動でグルーピングすると、このような弊害が起きる可能性があります。ドメインモデルはユビキタス言語でグルーピングしましょう。 |
モデルの実装に対する注意点
モデルの説明の最後に、注意点が一つあります。ドメインモデルのクラス名・属性名・振る舞いの名前は、すべてユビキタス言語と対応するということを忘れないでください。逆に言えば、実装都合の言葉が登場したらなんとしても抵抗しましょう。ドメインモデルとはそういうモデルなのです。これを忘れるとせっかくチーム内で定義したユビキタス言語を台無しにしかねないので、注意してください。
ライフサイクルを管理する
ここまでユビキタス言語をベースとしたモデルの説明をしてきましたが、ここからは、オブジェクトのライフサイクルをDDDではどのように解決するか簡単に説明します。ここからは割と技術的な側面が強くなります。個人的には、特にリポジトリが複雑になりやすく実装ノウハウも必要だと思っています。
さて、どんなオブジェクトにもライフサイクルはあり、オブジェクトがメモリ上やDB上に存在したり、他のオブジェクトの関連があり、状態の変化なども起こります。このようなライフサイクルに関する問題はそもそも複雑で、それをドメインモデルに押し付けると本来の表現を台無しにする可能性があります。そのような事態を避けるためのパターンとしてライフサイクルの管理を行います。
一塊として扱う集約
オブジェクトが関連を持つことは少なくありません。その関連を最小限に抑えることは、シンプルな設計を実現するために必要なことです。
その為に使えるのが集約(アグリゲート)というパターンです。集約は、エンティティや値オブジェクトなどの複数のオブジェクトを、ひとつの塊のオブジェクトと見なします。これまで例にあげたエンティティは集約としての役割を担っています。Hunterは、少なくともHunterIdやHunterNameを集約し一塊のオブジェクトとして定義しています。
そもそも、一塊をそんなに重要視するかというと、もちろん関連を抑えるというのもありますが、オブジェクトとしての状態の一貫性を維持するという意味もあります。
これを難しい言葉で、”不変条件を維持する”と言います。
購入申請から見る不変条件
その不変条件が重要な理由をたとえ話で説明してみましょう。会社で何かものを買うときに”購入申請”を出すことがあると思います。仮に、開発チーム内でMacが必要になったので次のような購入申請を出す事にしたとしましょう。次の購入申請は、一度の申請で承認限度額が100万なので、”合計金額が承認限度額を超えてはならない”という、不変条件を満たしています。ワークフローシステムの申請ボタンは押せそうですが、一旦チームメンバーに見せるために下書きに保存しました。その後に承認限度額以下なら上位の機種に変更してもよいと上司から指示がありました。
| 購入件名 | とにかくMacがほしい件 | ||||||||||||
| 承認限度額 | 1,000,000円 | ||||||||||||
| 合計金額 | 650,000円 | ||||||||||||
| 購入品目 |
|
さて、ここでチームメンバーのAさん・Bさんそれぞれが、自身のPCのScalaコンパイラを高速化させるために1台55万するMac Proに変更する更新を同時に行うとどうなるか。集約を意識せずに更新するとどうなるかみていきます。
Aさんは次のように合計が100万以内なので申請します。
| No. | 商品名 | 個数 | 金額(円) |
| 1 | MacBook Pro 15/Retina カスタマイズ (Aさん用) | 1 | 550,000 |
| 2 | MacBook Pro 13/Retina カスタマイズ (Bさん用) | 1 | 280,000 |
同様にBさんも100万以内なので申請します。
| No. | 商品名 | 個数 | 金額(円) |
| 1 | MacBook Pro 15/Retina カスタマイズ (Aさん用) | 1 | 370,000 |
| 2 | Mac Pro 6コア カスタマイズ (Bさん用) | 1 | 550,000 |
保存された申請は次のとおりです。合計金額が110万です。不変条件を破ってしまいました。
| No. | 商品名 | 個数 | 金額(円) |
| 1 | Mac Pro 6コア カスタマイズ (Aさん用) | 1 | 550,000 |
| 2 | Mac Pro 6コア カスタマイズ (Bさん用) | 1 | 550,000 |
もうわかりますね。自分が変更していない、他の箇所への変更を無視しているため、このような不整合が起きます。購入品目単体をロックするだけでは防ぎようがありません。どうするかというと、それぞれの購入品目を購入申請の単位で一塊のオブジェクトとして扱います。データの更新は、集約単位でロック(ロックは悲観でも楽観でもよい)を獲得して行う必要があります(モデルを後述するリポジトリを通じてRDBMSに保存する際も、集約の境界がトランザクション境界と一致する必要があります)。集約は、オブジェクトを不正な状態に陥らないようにするための、重要な設計要素です。
集約を生成するためのファクトリ
オブジェクトのライフサイクル初期といえば、まずインスタンスの生成を行うフェーズです。その生成処理をモデル自身が担うと、モデルとしての表現にそぐわない場合があります。例えば、車が車自身を生成するのか?工場が車を作るのがふさわしいのではという話です(じゃぁ工場は誰が作るの?は一旦置いておいてーw)。特に複雑な生成処理の場合は、ドメインの知識を表現するドメインモデルの責務に合致しません。かといって、クライアント側に複雑な生成処理を押し付けるわけにもいきません。その場合に使うのがファクトリです。
エンティティのコード例にすでに紹介したのですが、ファクトリはコンパニオンオブジェクトを用いれば簡単に実装できます。単純なものであればこれで十分です。複雑な場合は別途ファクトリクラスとして分けることもあります。そのあたりの設計戦略を変更する基準の詳細については、「エリック・エヴァンスのドメイン駆動設計」の「第6章 ドメインオブジェクトのライフサイクル」P134を参照してください。
|
1 2 3 4 5 6 7 8 |
trait Hunter extends Entity[HunterId] { // ドメインの表現だけに集中する } // コンパニオンオブジェクト object Hunter { def apply(identity: HunterId, name: HunterName): Hunter = new HunterImpl(identity, name) } |
集約を永続化するためのリポジトリ
オブジェクトのライフサイクル中期ではすでにオブジェクトは存在していて、そのオブジェクトへの参照を辿る方法が必要となります。もっとわかりやすく言えば、データベースなどに永続化されているオブジェクトをどのように取り出すかという話題です。リポジトリはその用途に利用できます。
リポジトリには、次のような集約ルートであるエンティティ(以下 ルートエンティティ)を永続化(保存したり読み込んだり)するI/Fを定義します(Mには、同期型I/Oならscala.util.Try、非同期型I/Oならscala.concurrent.Futureを指定することができます)。それらは、ルートエンティティを”保存する(save/store)”もしくは”識別子で解決する/読み込む”などの永続化の言葉に対応します。SQLのinsert,updateより抽象度が高い言葉です。
|
1 2 3 4 5 6 7 8 9 |
trait Repository[M[+ _], ID <: Identity[_], E <: Entity[ID]] { type This <: Repository[M, ID, E] // 識別子を指定してエンティティへの参照を取得する def resolve(identity: ID)(implicit ctx: EntityIOContext): M[E] // エンティティを保存する def store(entity: E)(implicit ctx: EntityIOContext): M[(This, E)] // 識別子を指定してエンティティを削除する def delete(identity: ID)(implicit ctx: EntityIOContext): M[(This, E)] } |
リポジトリは、ルートエンティティ単体を永続化するだけではなく、何らかの条件に一致するルートエンティティの集合を要求するためのメソッドを提供します。次の例は、Hunterのランクでフィルターするためのメソッドです(検索結果の集合が大きい場合は、Chunkのような集合の一部分だけを返す工夫が必要かもしれません)。実装的には、ハードコードされたクエリを内部で持ち、そのためのパラメータを受け取るようなものになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// 問い合わせ結果の集合の部分を表すオブジェクト trait Chunk[ID <: Identity[_], E <: Entity[ID]] { val index: Int val entities: Seq[E] } // ハンター用リポジトリ trait HunterRepository extends Repository[Future, HunterId, Hunter] { // … // 属性(ランク)でフィルターする def filterByRank(rank: HunterRank, index: Int, size: Int) (implicit ctx: EntityIOContext): Future[Chunk[Hunter]] // … } |
もう少し、フィルターメソッドを一般化したい場合は、仕様パターンを使います。ここでは詳しく説明しませんので、「エリック・エヴァンスのドメイン駆動設計」の「第9章 仕様(SPECIFICATION)」P226 を参照してください。
|
1 2 3 4 5 6 7 8 |
trait Repository[M[+ _], ID <: Identity[_], E <: Entity[ID]] { // 属性でフィルターする(criteriaがwhere句相当) def filterByCriteria(criteria: Criteria, index: Int, size: Int) (implicit ctx: EntityIOContext): M[Chunk[E]] // 属性でフィルターする(predicateがtrueを返すエンティティだけを集める) def filterByPredicate(predicate: E => Boolean, index: Int, size: Int) (implicit ctx: EntityIOContext): M[Chunk[E]] } |
| コラム : リポジトリはDAOなのか? |
| 勉強会などで、”リポジトリはDAO(RDBMSの文脈としてのデータアクセスオブジェクト)と同じものですか?”と質問されることがあるのですが、その答えは私の考えでは”いいえ”です。リポジトリの実装にはRDBMSに対応した実装もありますし、他にもオンメモリであったり、NoSQL(Memcached, Redis)など様々な実装があり得ますが、そのI/Fは”保存する”、”IDで読み出す”など抽象度の高い文脈を持っています。それに対して、DAOというのは リポジトリより抽象度の低い、RDBMSに最適化されたI/F(insert, update, delete, selectなどSQLに近いI/F)を持っているはずです。その前提で考えると、DAOはリポジトリより下位のレイヤーに位置するはずです。強いて言えば、RDBMSに対応したリポジトリの実装で利用される可能性があるのがDAOではないでしょうか。 リポジトリのI/Fが固有の永続化手段に依存しないということは、永続化対象となるオブジェクトもまた依存しません。つまり永続化手段ごとにモデルを分けないということを意味します。DDDとしてはユビキタス言語で決めたドメインモデルは永続化手段ごと(MySQL用、Memcached用など)に別々ではなく、常に一つなのです(後に説明するインフラストラクチャ層では、実装都合上、永続化手段ごとにインフラストラクチャ用のオブジェクトを定義することがあります)。 |
一例として、ScalikeJDBCに対応したリポジトリを実装してみました(ScalikeJDBCがDAOの部分に相当します)。次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
trait HunterRepository extends Repository[Try, HunterId, Hunter] object HunterRepository { def ofJDBC: HunterRepository = new HunterRepositoryOnJDBC def ofMemcached: HunterRepository = /* ... */ } private class HunterRepositoryOnJDBC extends HunterRepository { type This = HunterRepository def resolve(identity: ID)(implicit ctx: EntityIOContext) = Try { implicit val dbSession = getDbSession(ctx) sql”select * from hunter where id = ?”. bind(identity.value.toString).map(toEntity). single.apply().getOrElse(throw new EntityNotFoundException()) } // レコード表現をルートエンティティに変換する private def toEntity(resultSet: WrappedResultSet): Hunter = /* ... */ // ... } |
クライアントコードのイメージ。ちなみに、コネクションやトランザクションを表すDBSessionはEntityIOContextにラップして渡しています。
|
1 2 3 4 5 6 |
val repository = HunterRepository.ofJDBC implicit val ctx: EnityIOContext = EntityIOContext.ofJDBC(AutoSession) repository.resolve(MessageId("2ab1ec1b-adfe-4bed-b8f3-8dc19e00e030")).foreach{ hunter => println(hunter) } |
集約は外部にある集約を内包しない
ちょっと集約の話に戻ります。集約のハマりポイントがあります。ChatWorkのようなチャットシステムを例にとって説明します(ハンターゲームの話から逸れてすみません...)。モデルとしては、利用者(User)、チャットルーム(ChatRoom)、メッセージ(Message)という概念があり、それぞれがエンティティだとします。ChatRoom内でUserが発言したMessageは集約であり、実装は次のようになるものとします。
|
1 2 3 4 5 6 7 8 9 10 11 |
trait Message extends Entity[MessageId] { val toChatRoom: ChatRoot val fromUser: User val text: String } class MessageRepository extends ... { def store(entity: Message): Future[(This, Message)] = { // entity.toChatRoomやentity.fromUserの永続化は // それぞれの集約に対応したリポジトリが行うべき。 } } |
この例ではChatRoomとUserを集約しているように見えますが、前述したようにリポジトリは集約をI/Oの単位として扱うため、ChatRoomやUserの属性も一緒にI/Oするのかという疑問が浮上します。よく考えるとわかるのですが、これらのエンティティは明らかに外部の集約であり、対応するリポジトリも別に存在するため、MessageRepositoryで一緒にI/Oすべきではありません。つまり、ChatRoomとUserは概念上集約の中には含まれません。別個の塊なのです。
このような実装形態を取った場合、その属性が集約の内部に属するのか否か、区別をつけるのは容易ではありません。間違ってMessageRepositoryでChatRoomやUserを一緒に永続化しないように気をつける必要があります。私のおすすめは次のような直接的な参照を保持するのではなく、エンティティの識別子、つまり間接的な参照を保持することです。参照が欲しい場合は、専用のメソッドを用意すればいいでしょう。
|
1 2 3 4 5 6 7 8 9 |
trait Message extends Entity[MessageId] { // 集約内部の属性として識別子を保持する val toChatRoomId: ChatRootId val fromUserId: UserId val text: String // 外部の集約ルートへの参照はリポジトリを使って解決する def toChatRoom(implicit repos: ChatRoomRepository): Try[ChatRoom] def fromUser(implicit repos: UserRepository): Try[User] } |
ドメインモデルをアプリケーションに組み込む
ここまではドメインモデルとライフサイクル管理について説明をしてきましたが、ここからは表現力豊かなドメインモデルをどのようにアプリケーションに組み込むか簡単に説明します。
レイヤーを使ってドメインを隔離する
DDDでは、基本的なレイヤーとしては以下の4階層があります。DDDとして本質的に重要なのは、ドメイン層と非ドメイン層を混ぜないということです。ドメイン層は、他の層から隔離しましょう。
理由は簡単で、ドメインの表現に他のレイヤーの知識が混ざると、それを読んで理解することが難しくなるからです(コードを読んで頭の中でパッチワークとかやめましょう)。
人間が一度に考えられることには限界があるので、レイヤーで分割しましょう。
| レイヤー名 | 意味 |
| UI層 | ユーザに対しUIを使って情報を表示したりユーザの命令を解釈する層。Webアプリケーションでは、コントローラやビューなどはこの層に分類される。 |
| アプリケーション層 | 豊かな表現力を持つドメインモデルを用いて問題を解決するためのレイヤ。ドメインオブジェクトを使って実行される処理の進捗管理やタスクのディスパッチなどを行う |
| ドメイン層 | 問題領域の知識を表現する層。ドメインオブジェクト同士で相互に連携し、問題を解決するための機能を実現したり、制御したりする。ただし、永続化のようにドメインと直接関係しない汎用的な技術は下位のインフラストラクチャ層に委譲する |
| インフラストラクチャ層 | ほかのすべてのレイヤをサポートする汎用的な技術基盤を提供する層。データベースへのSQLを使った永続化処理など |
レイヤーをわきまえてドメインモデルを脱線させないようにする
一般的なウェブフレームワーク(MVC)などでは、モデルにUIや永続化に関する知識が同居しがちです。DDDではそれはレイヤーが違うので、ドメインモデルからは分離する必要があります。例えば次のようにHunter#saveメソッドで、ドメインモデルであるハンターを永続化することは、DDDでは好ましくありません。saveという言葉はドメインの言葉ではなく永続化の言葉であるためです。リポジトリか、インフラストラクチャ層の責務ではないでしょうか。
|
1 2 |
val hunter: Hunter = /* … */ hunter.save // ハンターを永続化する |
また、次のように、ドメインモデルにUI層の知識が混入しないようにしましょう。UI層のビューモデルなどで行うべきです。
|
1 |
hunter.toString // <span>ほげ ふが</span> |
ドメインをアプリケーションに組み込む
本当に前置きが長くなりましたが(;´Д`)、ドメインモデルをアプリケーションに組み込んでみましょう。ハンターゲームのサーバをRESTっぽいAPIで考えてみます。コードは次のとおりですが、説明のために作ったものなので、あくまでも一例だと思ってください(RDBMSのコネクション管理やトランザクション管理、さらにはドメインロジックをユースケース単位で表現するアプリケーションサービスなどは便宜上省略しています)。ここでの例は、FinagleをベースにしたTrinityというフレームワークを前提にしています。
対応するシナリオは、”ハンターの生成”と、”モンスターへの攻撃”、”アイテムの手渡し”です。ドメインモデルを利用したコードは一部ですが、一部だからと言って重要ではないということはありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
// RESTっぽいアプリケーション object HunterGameServer extends ConsoleApplication { // ハンター関連のコントローラ object HunterController extends ControllerSupport { // ハンター生成アクション def createHunter = SimpleAction { request => val json = toJson(request) // バリデーションはScalaz Validationを使ってます val formValidation = CreateForm.validate(json) formValidation.fold(errorHandler, { form => // ここが重要! hunterRepository.store(toEntity(form)).map { (_, entity) => Ok(entity) } }) } // 戦闘関連のコントローラ object BattleController extends ControllerSupport { def attackMonster = SimpleAction { request => val json = toJson(request) val formValidation = AttackForm.validate(json) formValidation.fold(errorHandler, { case (attackerId, methodType, monsterId) => for{ attacker <- hunterRepository.resolve(attackerId) monster <- monsterRepository.resolve(monsterId) // ここが重要! (newAttacker, newMonster) <- attacker.attack(methodType, monster) _ <- hunterRepository.store(newAttack) _ <- monsterRepository.store(newMonster) } yield { Ok(newAttacker, newMonster) } } } } // アイテム関連のコントローラ object ItemController extends ControllerSupport { // アイテムの手渡しアクション def transferItems = SimpleAction { val json = toJson(request) val formValidation = TransferItemForm.validate(json) formValidation.fold(errorHandler, { case (toId, fromId, items) => for { Seq(curTo, curFrom) <- hunterRepository.resolves(Seq(toId, fromId)) // ここが重要! (newTo, newFrom) <- ItemService.transferItems(curFrom, curTo, items) _ <- hunterRepository.store(Seq(newTo, newFrom)) } yield { Ok(newTo, newFrom) } } } // ... } // ルーティング定義 override protected val routingFilter = Some(RoutingFilter.createForActions { implicit pathPatternParser => Seq( // ... Post % "/hunter/create" -> HunterController.createHunter, // ... Post % "/battle/attack" -> BattleController.attack, // ... Post % "/item/transfer" -> ItemController.transferItems, // ... ) }) // サーバ起動 startWithAwait() } |
既存のフレームワークとどう折り合いをつけるのか
ウェブフレームワークなどで、多く採用されているモデルの形式にはCoCが適用されているため、ドメインモデルとしての素直な表現がしにくい場合があります。つまるところ、これはCoCを強制するフレームワークとは相性が悪いということを意味します。おすすめの解決策としては、上記コードで紹介したScalikeJDBCやTrinityのようにモデルに対する制約が緩いフレームワークを採用する。これは選択肢が少ないので現実的ではないかもしれません...。あとは、フレームワークが前提とするモデルはドメインモデルとして定義しない戦略です。つまり、インフラストラクチャ層やUI層のモデルとして定義し、別個にドメインモデルを定義してレイヤー間を相互に変換するという方法です。変換コストがそれほど気にならないなら現実的な選択肢になるでしょう。
まとめ
長々と最後までお付き合いいただきありがとうございました。
DDDの”ユビキタス言語”と”モデル駆動設計”の二つの手法を使うと、問題領域の”言葉”と”モデル”と”実装”と紐づけることができるようになります。この結びつきは、設計の意図を伝える手段として効果を発揮します。設計に悩んでるエンジニアにはぜひ取り入れてほしい考え方です。まぁ、DDDをやったからといって、設計のすべての問題が解決する、と言うつもりはありません。しかし、設計に対して真摯に向き合っているエンジニアに対して、”思考停止しない”ための指針を与えてくれると思っています。
ちなみに、この記事の内容は、DDDの第一部と第二部に関連しますが、これでもほんの一部しか説明できていません。この記事が、少しでもDDDを理解する助けになれば幸いです。これをきっかけに興味が湧いた方は、書籍もぜひ読んでみてください!
最後に、チームメンバーの、DDDを実践した感想を紹介します。
- 共通の設計知識を基にしているため、途中から参加してもコードの把握がしやすかった(JavaScript大好きエンジニア)
- ユビキタス言語に気をつけて発言するようになったので、誤解されることが少なくなった(ディレクター)
- 「経験による設計」ではなく「DDDに従った設計」をしているため、何を参照すればよいかが明確になり設計についての勉強がやりやすい(新卒エンジニア)
- 「ハンター」を見る目が変わった!(二年目エンジニア)
明日は、JANOGでおなじみ@OsamuKurokochi さんです。