SWFバイナリ編集のススメ番外編 (zlib 伸張) 中編
よやと申します。こんにちわ。
今回は zlib 解説の中編です。前編はこちら ↓
- http://labs.gree.jp/blog/2012/01/4082/ SWFバイナリ編集のススメ番外編 (zlib 伸張) 前編
前回、zlib ヘッダのバイナリを解説しました。今回はその後ろに続く Deflateストリームのバイナリ構造についてです。
尚、固定ハフマンまでの説明で長くなり過ぎたので、動的ハフマン(カスタムハフマン)は次回の後編で改めて解説いたします。
前回の復習
- zlib は「zlib ヘッダ + Deflate ストリーム + ADLER32」のデータ形式です。尚、通常、zlib ヘッダ無しでも Deflate ストリームだけで圧縮元のデータを復元出来ます。(DICTID が存在すると話が少し厄介ですが、通常見かける事はないでしょう)
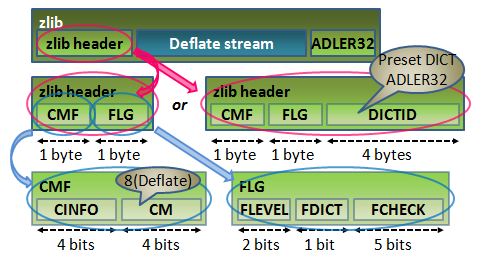
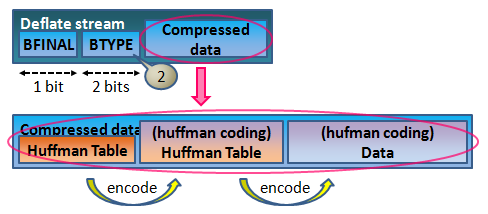
Deflate はデータを任意の長さのブロックで分けて収納出来ます。続きのブロックがあるかは BFINAL で表し、各ブロック毎に任意の圧縮タイプ(BTYPE)を付けられます。
- ブロックの連結イメージ
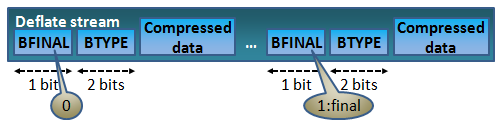
- 圧縮タイプには三種類存在します。データのサイズや性質に応じて使い分けます。(前回、大まかに解説しました)
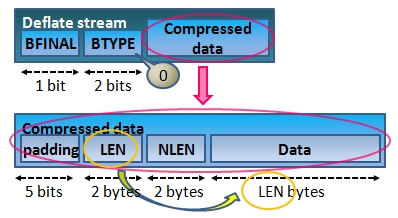
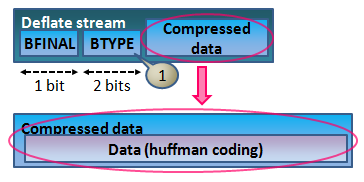
テストデータの作り方
PHP には gzcompress という関数がありまして、gz と頭に付いていますが (gzip でなく) zlib のデータを生成します。
- 参考) http://www.php.net/manual/ja/function.gzcompress.php ← zlibヘッダ + deflateストリーム + adler32 (*1)
- 無圧縮(BTYPE:0)
|
1 2 3 4 |
$ php -r 'echo gzcompress("This is TEST", 0);' > btype0.zlib $ hexdump -C btype0.zlib 00000000 78 01 01 0c 00 f3 ff 54 68 69 73 20 69 73 20 54 |x......This is T| 00000010 45 53 54 1a e3 03 f5 |EST....| |
- 固定ハフマン(BTYPE:1)
|
1 2 3 4 |
$ php -r 'echo gzcompress("This is TEST");' > btype1.zlib $ hexdump -C btype1.zlib 00000000 78 9c 0b c9 c8 2c 56 00 a2 10 d7 e0 10 00 1a e3 |x....,V.........| 00000010 03 f5 |..| |
- 動的ハフマン(BTYPE:2)
小さなデータに対して動的ハフマンを適用する方法は http://d.hatena.ne.jp/n7shi/20110719 を参考に .NET の DeflateStream を使おうとしたのですが、環境を作るのが面倒なのでデータの方だけ拝借させて頂きます。(zlib ヘッダとして頭に 9c 78 の 2byte を追加)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ php -r 'foreach (array_splice($argv, 1) as $n) { echo chr(hexdec($n)); }' \ 78 9c \ ED BD 07 60 1C 49 96 25 26 2F 6D CA 7B 7F 4A F5 \ 4A D7 E0 74 A1 08 80 60 13 24 D8 90 40 10 EC C1 \ 88 CD E6 92 EC 1D 69 47 23 29 AB 2A 81 CA 65 56 \ 65 5D 66 16 40 CC ED 9D BC F7 DE 7B EF BD F7 DE \ 7B EF BD F7 BA 3B 9D 4E 27 F7 DF FF 3F 5C 66 64 \ 01 6C F6 CE 4A DA C9 9E 21 80 AA C8 1F 3F 7E 7C \ 1F 3F 22 32 3C FF 0F > btype2.zlib $ hexdump -C btype2.zlib 00000000 78 9c ed bd 07 60 1c 49 96 25 26 2f 6d ca 7b 7f |.x...`.I.%&/m.{.| 00000010 4a f5 4a d7 e0 74 a1 08 80 60 13 24 d8 90 40 10 |J.J..t...`.$..@.| 00000020 ec c1 88 cd e6 92 ec 1d 69 47 23 29 ab 2a 81 ca |........iG#).*..| 00000030 65 56 65 5d 66 16 40 cc ed 9d bc f7 de 7b ef bd |eVe]f.@......{..| 00000040 f7 de 7b ef bd f7 ba 3b 9d 4e 27 f7 df ff 3f 5c |..{....;.N'...?\| 00000050 66 64 01 6c f6 ce 4a da c9 9e 21 80 aa c8 1f 3f |fd.l..J...!....?| 00000060 7e 7c 1f 3f 22 32 3c ff 0f |~|.?"2<..| |
BTYPE 別詳細解説
BTYPE:0 無圧縮
この方式は実際には圧縮しません。初めにデータ長があり、その後ろに何も変換しない生のデータが続きます。
但し、データ長フィールドは 2 bytes の為、65535 を超えられない事に注意が必要です。
先程、生成したテストデータ(btype0.zlib)で確認しましょう。
|
1 2 3 |
$ hexdump -C btype0.zlib 00000000 78 01 01 0c 00 f3 ff 54 68 69 73 20 69 73 20 54 |x......This is T| 00000010 45 53 54 1a e3 03 f5 |EST....| |
先頭 2 bytes は zlib ヘッダなので無視するとして、その後ろに BTYPE とデータ長が続きます。
|
1 2 3 4 |
$ hexdump -C btype0.zlib 00000000 78 01 01 0c 00 f3 ff 54 68 69 73 20 69 73 20 54 |x......This is T| <> <---> <---> 00000010 45 53 54 1a e3 03 f5 |EST....| |
- zlib のビットの読み出しは分かりにくいですが、下位ビットから読みだします。
- 0x01 は2進数で 00000001、最後1ビットの 1(最後のブロック)とその手前2ビットの 00 (BTYPE)だけ意味があります。頭の 00000 は読み捨てます。
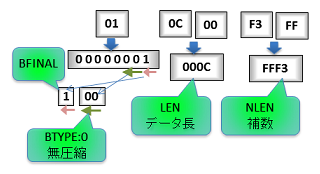
- LittleEndian なので 0c 00 => 0x000c => データ長が 12 byte である事を示します。
- データ長の次には足すと 0xffff になるような値(*2)が入ります。(verify チェックでしょうか)
|
1 2 3 4 5 |
$ hexdump -C btype0.zlib 00000000 78 01 01 0c 00 f3 ff 54 68 69 73 20 69 73 20 54 |x......This is T| <-------------------------- 00000010 45 53 54 1a e3 03 f5 |EST....| -------> <---------> |
12 bytes データが続く事が分かっているので、"This is TEST" を取り出して、復元成功です。
最後の 4 bytes は ADLER32 のチェックサムです。データが化けてないか確認するのに使います。
BTYPE:1 固定ハフマン
とある決まったハフマン表を使って伸長します。
BTYPE=1(固定ハフマン)のハフマン表は RFC1951 の Page12 に載っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Lit Value Bits Codes <ul> <li> ---- -----</li> </ul> 0 - 143 8 00110000 through 10111111 144 - 255 9 110010000 through 111111111 256 - 279 7 0000000 through 0010111 280 - 287 8 11000000 through 11000111 |
これをビット数の少ない順に並べて図にするとこうです。
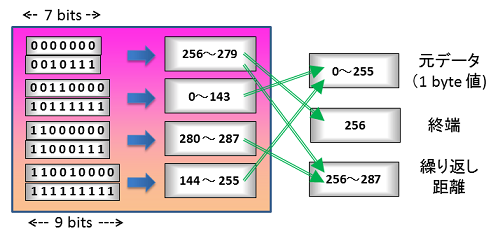
- 終端や繰り返しを表すメタデータに短いビット(7bits)を割り当て、
- その次に短いビット(8bits)を ASCII の前方のコードや距離の長い繰り返しのメタデータに割り当て、
- 最後にASCIIの後ろの方の文字を割り当てる。
US-ASCII のテキスト文字で短い間隔での繰り返しが多く出る、普通の英語の文章にそこそこ合った(でも、文字頻度での最適化まではしていない)ハフマン表と言えます。
さて、この表を元に先程作成した、テストデータ(btype1.zlib)を解釈してみます。
|
1 2 3 4 |
$ hexdump -C btype1.zlib 00000000 0b c9 c8 2c 56 00 a2 10 d7 e0 10 00 1a e3 |x....,V.........| <> 00000010 03 f5 |..| |
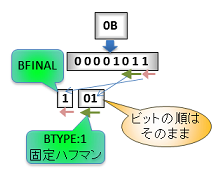
- 0x0b は2進数で 00001011、最後1ビットの 1(最後のブロック)とその手前2ビットの 01 (BTYPE)で始まります。
- btype:0 と違って、残りの 00001 にも意味があります。そこからデータの始まりです。
まずは BFINAL と BTYPE の 3bit を見て固定ハフマンのブロックが始まるのを確認します。
元データの復元 (リテラル)
まず 7 bits 読みだします。
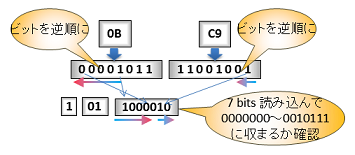
7bits のエントリで定義された符号の範囲に収まらないので、更にもう 1 bit 読みだします。
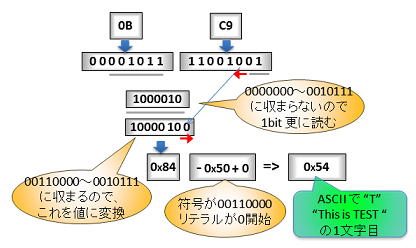
これで、1文字目の "T" が取り出せた事になります
元データの復元 (繰り返し)
"This is TEST" の "is "の3文字が繰り返しなので、長さ3、距離3の繰り返しを表すメタデータをハミング符号で指定する事で、圧縮率を上げられます。
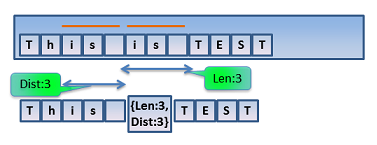
繰り返しメタデータに関する符号は RFC1951 の Page12 に定義されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
Extra Extra Extra Code Bits Length(s) Code Bits Lengths Code Bits Length(s) <ul> <li> ---- ------ ---- ---- ------- ---- ---- -------</li> </ul> 257 0 3 267 1 15,16 277 4 67-82 258 0 4 268 1 17,18 278 4 83-98 259 0 5 269 2 19-22 279 4 99-114 260 0 6 270 2 23-26 280 4 115-130 261 0 7 271 2 27-30 281 5 131-162 262 0 8 272 2 31-34 282 5 163-194 263 0 9 273 3 35-42 283 5 195-226 264 0 10 274 3 43-50 284 5 227-257 265 1 11,12 275 3 51-58 285 0 258 266 1 13,14 276 3 59-66 Extra Extra Extra Code Bits Dist Code Bits Dist Code Bits Distance ---- ---- ---- ---- ---- ------ ---- ---- -------- 0 0 1 10 4 33-48 20 9 1025-1536 1 0 2 11 4 49-64 21 9 1537-2048 2 0 3 12 5 65-96 22 10 2049-3072 3 0 4 13 5 97-128 23 10 3073-4096 4 1 5,6 14 6 129-192 24 11 4097-6144 5 1 7,8 15 6 193-256 25 11 6145-8192 6 2 9-12 16 7 257-384 26 12 8193-12288 7 2 13-16 17 7 385-512 27 12 12289-16384 8 3 17-24 18 8 513-768 28 13 16385-24576 9 3 25-32 19 8 769-1024 29 13 24577-32768 |
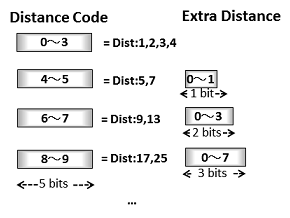
- ハフマン符号に応じて、繰り返しの長さが定義されます。
- 繰り返しの長さが長い(11以上の)場合は、その長さに応じて追加の長さを入れるフィールド(Extra Bits)を用意します。
- 続く5bits に繰り返し開始までの距離が入ります。
- 繰り返しの距離が遠い(11以上の)場合は、その距離に応じて追加の距離を入れるフィールド(Extra Bits)を用意します。
バイナリ構成としては以下のようになります。
- Huffman Code (Length)

- Distance Code
では、実際のデータ("is " の繰り返し)を見てみましょう。
|
1 2 3 4 |
$ hexdump -C btype1.zlib 00000000 0b c9 c8 2c 56 00 a2 10 d7 e0 10 00 1a e3 |x....,V.........| <> 00000010 03 f5 |..| |
繰り返しのある場所まで調べるのが面倒なので、ツールに頼ります。
これは pure PHP で Zlib を解釈するツールですが、これの dump スクリプトを使うと、各ハフマン符号が Zlib バイナリ中の何処のオフセットに存在するのか分かります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
IO_Zlib$ php sample/zlibdump.php btype1.zlib CMF:78(CINFO=7 CM=8) FLG:0x9C(FLEVEL=2 FDICT=0 FCHECK=28) (BFINAL)=1 BTYPE:1 [000000] 54(T) (offset:0x02.03 bitlen:8) [000001] 68(h) (offset:0x03.03 bitlen:8) [000002] 69(i) (offset:0x04.03 bitlen:8) [000003] 73(s) (offset:0x05.03 bitlen:8) [000004] 20( ) (offset:0x06.03 bitlen:8) [000005] Length:3 LengthExtend:0 Distance:3 DistanceExtend:0 (offset:0x07.03 bitlen:12) [000008] 54(T) (offset:0x08.07 bitlen:8) [000009] 45(E) (offset:0x09.07 bitlen:8) [00000a] 53(S) (offset:0x0a.07 bitlen:8) [00000b] 54(T) (offset:0x0b.07 bitlen:8) (Terminate) (offset:0x0c.07 bitlen:7) ADLER32:451085301 |
これを信じて (0オリジンの) 7 bytes 目の 3bits 目から分解します。
- ハフマン符号が 0x257 なので繰り返しの長さが 3 だと分かります。
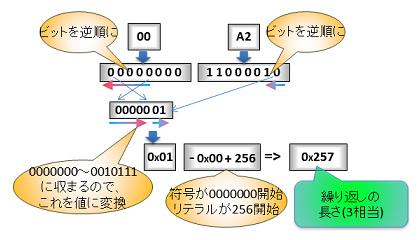
- 続く 5 bits を見ると、距離が 3 だと分かります。

この例では、Extra Bits を使いませんでしたが、より長い長さ、遠い距離だと必要になり、上の方で説明したように Extra Bits に入っている値を足して補正します。
BTYPE1 のまとめ
-
ハフマン符号を解釈して以下の3つに分別します。
- リテラル(0~255) => 元データそのもの
- 終端記号(256) => Deflate ブロックの終端
- 長さ(257~285) => 繰り返しパターンの長さ
-
ハフマン符号が長さを表す場合
- 長さが 3~10(ハフマン符号は 257~264)の場合は、その値をそのまま長さとして使う
- 長さが 11以上(ハフマン符号は 265~285)の場合は、更に後ろを数bits読みだして、それを足した値を長さにします
-
距離フィールド(5bits)
- 距離が 0~3 の場合は、その値をそのまま距離として使う
- 距離が 4以上の場合は、更に後ろを数bits読みだして、それを足した値を距離にします
-
ビットをそのままの並びで値として解釈する時と、逆さにして解釈する時があります。規則は正直分かりません。ハフマン符号が逆順なのは妥当ですが、5 bits 固定の長さフィールドも逆順で、その拡張ビットは正順。整理すると以下のようになります。
- ビット正順 => BTYPE の 2 bits、長さ拡張フィールド、距離拡張フィールド。
- ビット逆順 => ハフマン符号、距離フィールド(5 bits)
次回予告
BTYPE:2 動的ハフマン
より高いデータの圧縮率を求めるならば、そのデータに応じた適切なハフマン表が必要です。
この動的ハフマン方式では、元データを解析して適切なハフマン表で圧縮を行い、そのハフマン表を先頭につけるデータ構造となります。
こちらは最終回に当たる Zlib 伸長解説の後編で解説いたします。
以上です。
*1: gzip ヘッダも込みで欲しい場合は gzencode 、zlib のヘッダ無しで deflate ストリームだけ欲しい場合は gzdeflate が対応しています
*2: いわゆる 1の補数です。一般に負の表現でよく使われる 2の補数ではないです。