FlatBuffersをPHPで使ってみる
はてさて、最近Unityまわりの記事ばかりを書いていましたがあんまりウケがよくなく、やー、やっぱ自分の専門領域外のネタは(掴みがわからず)きっつぃなぁと、いうことで今日はFlatBuffersのPHP portを書いたので紹介でもしておこうかと思います。
先に断っておくとまだそこまで使い倒していないので解釈の違いなどがあるかと思いますので識者の方はツッコミいただけると助かります。
FlatBuffers
FlatBuffersは特にゲームに特化してつくられたSerializationライブラリでC++を始めとした主要な言語のライブラリサポートがされています。
https://github.com/google/flatbuffers
詳細は↑読んでね、という感じなのですが、Facebookの記事でFlatBuffersを知られたかも多いかと思います。
https://code.facebook.com/posts/872547912839369/improving-facebook-s-performance-on-android-with-flatbuffers/
で、細かい話は置いといて内部の話になるんですが。FlatBuffersの設計デザインは2系統の流派がありまして、C++派閥(Go, Python)、Java派閥(C#, PHP)という具合
に分かれております。(といってもByteBufferを使うか、自前でOffset計算していくかぐらいなんですが)
PHP版はJavaやC#の設計をもとに作成しており、今回はPHP版の実装を元にFlatBuffersの内部について書こうと思います。
ざっくり 説明
一般的なJsonやProtocolBuffers等のSerializationではシリアライズしたいオブジェクト構造をもとに再帰的にIterateしたり、事前定義されたスキーマ情報から最終結果のbyte列を組み立てていきます。
基本的にFlatBuffersではスキーマから生成されたメタクラスをもとにしつつ。データ格納の手続き自体は開発者自身でやっていくことになります。基本的なデザインとして、一発たたけばいい感じなデータができる、という作りではないということですね。
例えばPHPの場合、jsonにシリアライズしたデータを作りたい時はjson_encodeの関数にobjectを渡して呼ぶだけでjsonが作れます。
FlatBuffersの場合は、FlatBufferBuilderを初期化してバッファ領域を確保したのちに
シリアライズしたいオブジェクトのデータを一つ一つ入れていきます。
具体的なコードに行ってみましょう。例えばHPが10、nameがchobieというモンスターを表現したデータを作りたい、という場合は
|
1 2 3 4 5 6 7 8 9 |
#monster.fbs namespace MyGame; table Monster { hp:int; name:string; } |
※まだmerge前なのでPHP対応版のflatcをビルドしてください。(特にビルド用意してないんで https://github.com/chobie/flatbuffers から自分でビルドしてください)
|
1 2 |
flatc.exe -l monster.fbs |
準備ができたのシリアライズ/デシリアライズの解説へ。
それPHPで書くと
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<?php $monster = new StdClass(); $monster->hp = 10; $monster->name = "chobie"; // jsonとして外とやりとりする場合 // echo json_encode($monster); // echo PHP_EOL; // FlatBuffersとして外とやりとりする場合 $fbb = new \Google\FlatBuffers\FlatBufferBuilder(1); $nameOffset = $fbb->createString($monster->name); MyGame\Monster::startMonster($fbb); MyGame\Monster::addName($fbb, $nameOffset); MyGame\Monster::addHp($fbb, $monster->hp); $fbb->finish(MyGame\Monster::EndMonster($fbb)); file_put_contents("monster_data.bfbs", $fbb->sizedByteArray()); |
こうなります。
FlatBuffersではMyGame\Monsterというのがメタクラス(なんて呼べばいいかわからんすけど、どのオフセットにどのデータがあるか知っている、という意味でメタクラス)になります。このクラスはflatcというスキーマコンパイラからデータがbuffer上のどの位置に置くべきなのか、というのが書かれただけの単なるWrapperクラスとなります。
シリアライザ側はこんな感じで若干面倒くさいですが、便利メソッドとかを定義して使うのがいいでしょう。
反対にデシリアライザ側では値をとるときは$monster->GetHp()などすればいいだけなのでふつーな使い心地だったりします。(余談ですが他の言語はアクセサにプレフィクスはつけていませんが、PHPの場合予約語とかぶりやすいのでプレフィクスを付けています。)
FlatBuffersたるや - Serialize編
それでは前述したMonsterを作成する部分をbuffer部分を解説してみましょう(主にPHPでの実装の話です)
(文字で書くと位置とか面倒なのでちょっとずれてる所あるかも)
まずはMonsterの名前をcreateStringして文字列を確保します。初期状態では1のサイズのバッファしかないので内部で適切に増やしていきます。FlatBuffersでは基本的にBufferのうしろからデータを書いていきます。
|
1 2 |
[_______________[文字列のメタ情報][chobie\0]] |
次にStartMonsterを実行します。ここではFlatBuffersBuilderの内部のstateを変更するだけで特にBufferに対しては変更をかけません(実装によって変わることもあるでしょう)
|
1 2 3 |
[_______________[文字列のメタ情報][chobie\0]] ^StartMonster時の位置 |
AddNameを実行して名前の文字列がどこにあるか、というのを書き込みます。AddNameに渡すのは文字列ではなく、作成した文字列のBuffer内での位置となります。
|
1 2 3 |
[_________________[Nameはnの位置にある][文字列のメタ情報][chobie\0]] ^StartMonster時の位置 |
vector(文字列含む)は当然ながら要素数によりサイズが可変となります。そのままバッファ作成中に追加しようとするとoffset計算が大変になるので一番最初に可変データを書き込んでoffsetの位置を固定し、スキーマ上でつくられた固定の位置にはoffsetだけを書き込むようにしています。
AddHpを実行してHPの情報をバッファ上に保持します。
|
1 2 3 |
[_________[HPは10][Nameはnの位置にある][文字列のメタ情報][chobie\0]] ^StartMonster時の位置 |
データの格納が終わったのでEndMonsterを実行してvtable(データの存在やofffset位置が書かれています)やメタデータを書き込み、そのofssetを返します。
|
1 2 3 4 |
[___[vtableサイズ][vtable][メタデータ][HPは10][Nameはnの位置にある][文字列のメタ情報][chobie\0]] ^StartMonster時の位置 ^Monsterの位置 |
FlatBuffersBuilderのFinishを実行して、MonsterのOffsetを書き込みします。
|
1 2 |
[_[Monsterのデータはnから][vtableサイズ][vtable][メタデータ][HPは10][Nameはnの位置にある][文字列のメタ情報][chobie\0]] |
これでお終いです。
このままBuffer領域を書き出してしまうと不要なデータ(今回の場合前方の未使用領域)が混じっているので、SizedByteArrayを実行して必要なデータだけを出力します。
|
1 2 |
[Monsterの実データはnから][vtableサイズ][vtable][メタデータ][HPは10][Nameはnの位置にある][文字列のメタ情報][chobie\0]] |
このように事前定義したスキーマとBufferを駆使しながらデータを書きこんでいくのがFlatBuffersのキモとなっています。
FlatBuffersたるや - Deserialize編
sizedByteArrayをした結果のbyte列がすでに読み込み可能な状態になっています。
FlatBuffersはparseしない、というと少し語弊がありますが数ステップで必要なデータに辿り着くことができるので速いのです。
それではHPの値を取り出してみようと思います。
初期状態のFlatBuffersで決まっているのは先頭4byteがメタデータのオフセットがある位置ということだけです。
値が省略可能なのでbufferを渡された時点ではFlatBuffersはどこに何があるかよくわかっていません。
ということは利用者側がこのデータ列はMyGameのMonsterだ、というのがわかっていないと期待した値は帰ってこない、ということですね。
なので、読み込み側としてはこのような状態になっています。
|
1 2 |
[Monsterのデータはnから][~~~~][~~~~][~~~~][~~~~]~~~~][~~~~][]]~~~~~~~~ |
まず、GetRootAsMonsterを実行した時に、先頭4byteを読みメタデータの位置までとびます。
この位置が基本となります。
|
1 2 3 |
[Monsterのデータはnから][~~~~][~~~~][メタデータだった][~~~~]~~~~][~~~~][]]~~~~~~~~ ^ |
メタデータの中身はvtableのoffsetが書いてあるので、Monsterのデータの位置からvtableのoffset分戻ってvtableの初期位置を算出します。
|
1 2 3 |
[Monsterのデータはnから][テーブルサイズ][vtable][メタデータだった][~~~~]~~~~][~~~~][]]~~~~~~~~ ^ HPある |
そこからHPのvtableのoffset位置の値を読み込み、HPがこのBufferに存在するかを確認します。
なければデフォルト値を返し、あればMonsterのデータの位置からHPのoffset(vtableに書かれた値です)分飛ばしたデータを読み込んで返します。
今回の場合HPは存在するので、初期位置からvtableに書かれたoffset分とばした値をHPとして読み込みます。
|
1 2 |
[Monsterのデータはnから][テーブルサイズ][vtable][メタデータだった][HPは10だった]~~~~][~~~~][]]~~~~~~~~ |
引き続きNameも読んでみましょう。
vtableのnameの値を見て、存在しているのでnameのoffsetの位置を見ます。
|
1 2 3 |
[Monsterのデータはnから][テーブルサイズ][vtable][メタデータだった][HPは10だった][Nameはnの位置にある][~~~~][]]~~~~~~~~ Nameある |
nの位置にデータ列があるということがわかりました。値の位置はわかったので該当部分を読み込みます。vectorの場合は実データへのoffsetが書かれています。
|
1 2 |
[Monsterのデータはnから][テーブルサイズ][vtable][メタデータだった][HPは10だった][Nameはnの位置にある][文字列のメタ情報][]]~~~~~~~~ |
offsetを飛ばして読み込むとvectorのサイズが書いてあるので、文字列のデータとして読みます。
|
1 2 |
[Monsterのデータはnから][テーブルサイズ][vtable][メタデータだった][HPは10だった][Nameはnの位置にある][文字列のメタ情報][chobie\0]]~~~~~~~~ |
ということでnameもとれましたね。おしまい。
絵にするとこういう事になります。文字で説明するよりわかりやすいですね。
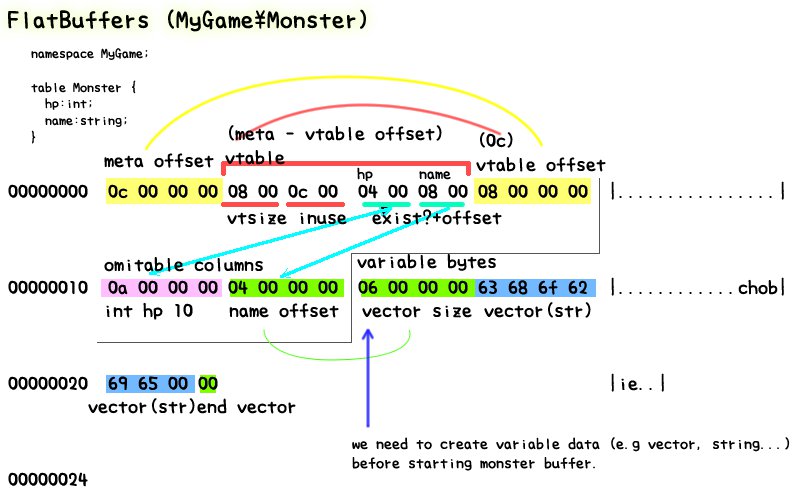
※↑の図で書いてある用語は独自の解釈だったりするんで、公式ドキュメント参照してください
※ケースによってはpadding入ったりします
FlatBufferのつよみ、よわみ
現在の状況も踏まえ、まとめてみてみようと思います。
つよみ
- encode/decodeの実装がほどよい感じ(説明があればな!)、かつ高速
- IDLによるコード自動生成
- unionによる型表現もできるわりに静的な強い型付けができるので柔軟にあつかえる
よわみ
- バッファの中身を想像しながら構築できないとencode時にエラーにはまりまくる。
(特に、はまりがちなパターンとしてはなんで文字列つくれないの!?vectorつくれないの?!とか。エラーやドキュメントが少ないのもこういうはまり原因なんですが) - ドキュメントが少ない
- 言語別実装がまだ少ない。
といったところだったりします。
どういうときにFlatBuffersを使うべきか
GoogleではProtocolBuffersが内外問わずよくつかわれていた(RTBのフォーマットもprotobufでしたね)、と聞くのですがProtocolBuffersの設計上(というか大半のdeserializerが抱えている設計上の問題ですが)は一度すべてparseしないと値が読み込めない、ということでした。
たとえば、256Mbytesのデータがあった場合、よくあるフォーマットでは一度全体をparseしてからでないとデータがどこにあるかわかりません。この中の数か所の値だけが欲しいのに、といった場合だとこれだとCPU時間が無駄ですよね。(そんなにでかくなる前に考えようって話ですが)
FlatBuffersでは多少のAPIの制限(開発者がちゃんと積んでね!)と構造的な特徴を持たせるだけで、どのデータが存在しているか分かるので高速にランダムアクセスすることができます。
正直な所、serializationの領域は代替品沢山ありますし、がっつりとした要件がなければ趣味成分(+実益を兼ねて)が多めな分野なので。自分たちの運用にあった好きなのを使うのがよいと思います。
サービス(お客様にとっても自分たちにとっても)にとってサイズが重要であればがっちり設計して専用のフォーマットを作ればいいだけですし、そうでなければ開発、運用が楽な法を使うのがよいですし。難しいのは継続できないですし。まとめるとおすし食べたいです。
という身もふたもない事を書きつつ。要約するとFlatBuffersはこういうところに2~3箇所当てはまると使ってみるといいと思います。
- 非力なデバイスでもCPU時間をそんなに消費せずに値よませたい
- jsonの言語間による型の不一致やobjectへのbindがつらいのはもういや
- Reflectionがない/遅いなどの理由でIDLから生成された静的なser/deが欲しい
- 既にあるデータセットの中で一部の列等しか参照しないけど高速に読ませたい
あ、でもPHP版はまだプロダクション運用にいれてないんで、いろいろ使い倒してみてもらえると嬉しいです。
因みにPHP版はまだそんな速くないんでそのうちCで書きなおそうかと。
とはいえ
まだまだドキュメントにしろAPIにしろFlatBuffersは成熟途中なのでがんばって向き合う気力がないとなんかあったときが大変です。
とまー、こんなかんじで。FlatBuffersの内部らへんの話ってnet上にも少ないんで、これを機に使ってみたり、port作ってもらったりするとより利用者が増えてハッピーというかんじなので皆様よろしくお願いいたします。
使い方よくわかんなかったらtests見てください。
補足
こういうコードが生成されます(WIP)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
<?php // automatically generated, do not modify namespace MyGame; use \Google\FlatBuffers\Struct; use \Google\FlatBuffers\Table; use \Google\FlatBuffers\ByteBuffer; use \Google\FlatBuffers\FlatBufferBuilder; class Monster extends Table { public static function getRootAsMonster(ByteBuffer $bb) { $obj = new Monster(); return ($obj->init($bb->getInt($bb->getPosition()) + $bb->getPosition(), $bb)); } public function init($_i, ByteBuffer $_bb) { $this->bb_pos = $_i; $this->bb = $_bb; return $this; } public function getHp() { $o = $this->__offset(4); return $o != 0 ? $this->bb->getInt($o + $this->bb_pos) : 0; } public function getName() { $o = $this->__offset(6); return $o != 0 ? $this->__string($o + $this->bb_pos) : null; } public static function startMonster(FlatBufferBuilder $builder) { $builder->StartObject(2); } public static function createMonster(FlatBufferBuilder $builder, $hp, $name) { $builder->startObject(2); self::addHp($builder, $hp); self::addName($builder, $name); $o = $builder->endObject(); return $o; } public static function addHp(FlatBufferBuilder $builder, $hp) { $builder->addIntX(0, $hp, 0); } public static function addName(FlatBufferBuilder $builder, $name) { $builder->addOffsetX(1, $name, 0); } public static function endMonster(FlatBufferBuilder $builder) { $o = $builder->endObject(); return $o; } } |