
マイクラで学ぶ専用サーバ運用
はじめに
インフラエンジニアのほりぐちです。我々の部には様々な案件が持ち込まれますが、今回は https://reality-festival.wrightflyer.net/3/ にて行われる 建築王 で利用するマインクラフトのサーバ(以下マイクラサーバ)を運用するというものでした。採用までの経緯などは省略しますが、当エントリではこれをクローズするまでの話になります。
結論から出すと出来上がったマニフェストはこちらです。
専用サーバとは
誰かひとりがホスト(サーバ)になり、他のプレイヤー(クライアント)がサーバのアドレスを打ち込んでそこへ参加するスタイルは古くからあり、マイクラもこれに該当します。また、ホストプレイヤーとして参加せずに無人のゲームをサーバ専用モードで起動して開放しておくことを専用サーバ ( Dedicated Server ) などと呼んでおり、このスタイルも古くからあります。近頃はゲームにフォーカスして DGS ( Dedicated Game Server ) と略して馴染まれているようです。
多くの方は自宅で起動しておいてチャットや掲示板、またはゲーム専用のロビーサーバに登録してメンバーを集めることが主流かと思いますが、今回の案件では Google Cloud Platform ( GCP ) に構築しました。
よくありそうな DGS の特徴
- プロトコルは TCP か UDP でペイロードはバイナリが多い。 RFC に書いてありそうな仕様が各ゲームごとに独自に実装されています
- 状態のほとんどがオンメモリで、一部がファイルシステムにて永続化され、スタンドアロンで動作します
- プラグインや MOD という拡張をサポートしています
- 誰も居なくてもゲーム内の時間が進んでいき、常に一定の負荷がある。逆に過負荷になってもゲーム内の時間の進みが遅くなるだけで LoadAverage が飛びぬけてサービス不能にならず、耐えられることが多いです
- 殆どのゲームに関するロジックを動作させているので、 3D ゲームではレベルデータの取り扱いにサーバ運用でも関連知識が必要になることもあります
建築王での要件
- イベント中は最大で50人接続したい
- VTuber 出演者以外にも、出演者が招待したゲストや抽選されたお客さまも参加されるので、ある程度のアクセス制限がほしい
- 荒らしなどの対策はしたい
- イベント終了時間以降は参加者にワールドをいじられたくない
- イベント後は審査があるので審査員プレイヤー以外入れないようにしたい
- 全体での費用は〇〇万円ぐらいでここに収まるようにしたい
そして、色々検討した結果こちらで考えた方針
- とりあえず Reality を運営している GCP 環境があるので相乗りする。よって Kubernetes Engine ( GKE ) を前提する
- モニタリングやアラート、 Slack 通知なども Reality と共用する
- 荒らし対策プラグインを導入し、巻き戻せるよう定期的に世代バッグアップを取得する
- アクセス制御には Service の
type: LoadBalancerを増やしたり減らしたりする - ゲームデータは全部 ParsistentVolume ( PV ) を Mount しておしまい
- Dockerfile を書いてビルドするのはめんどくさい。ありもののイメージでやりたい
- とりあえず Helm Charts あったので入れてみる
イベント前の構築など
まずは Helm で入れてみました。マイクラの Charts はこちら
友達とちょっと遊ぶとか、とりあえずどんなもんかデプロイして確認したいという程度であれば Helm で入れておしまいで十分かとおもいました。コマンド一発打って5分ぐらいでゲームから接続できるようになる。すごい!
が、本番運用には耐えられそうにありませんでした。
- helm コマンドでパラメータ変えてもほとんど反映されない。一度設定ファイルが生成されると PV で永続されるため
- 設定変更にはリリースの削除がいるが、 PV も消えるのでワールド含めて全部消える
- パラメータがすごく多いけどほとんど Env 経由でパラメータの見通しが悪い
- ReadWriteOnce の PV を使うのに Deployments で書かれてる
とりあえず helm に上がっているものはすごく雑に見えて信頼性に欠けるものだったので自分でマニフェスト書きつつ調整することにしました
実装
まずイメージの確認。検索して上位に出てくる https://hub.docker.com/r/itzg/minecraft-server/ は Helm のものと同じですが、 Dockerfile の雰囲気や人気をみると十分な信頼性があると認識、これを採用。とくに FROM openjdk:8u212-jre-alpine も信頼性が高そうなのと Layer が厚くないのが好印象。 Pod 削除時のライフサイクルもちゃんと動作しました
StatefulSet への変更
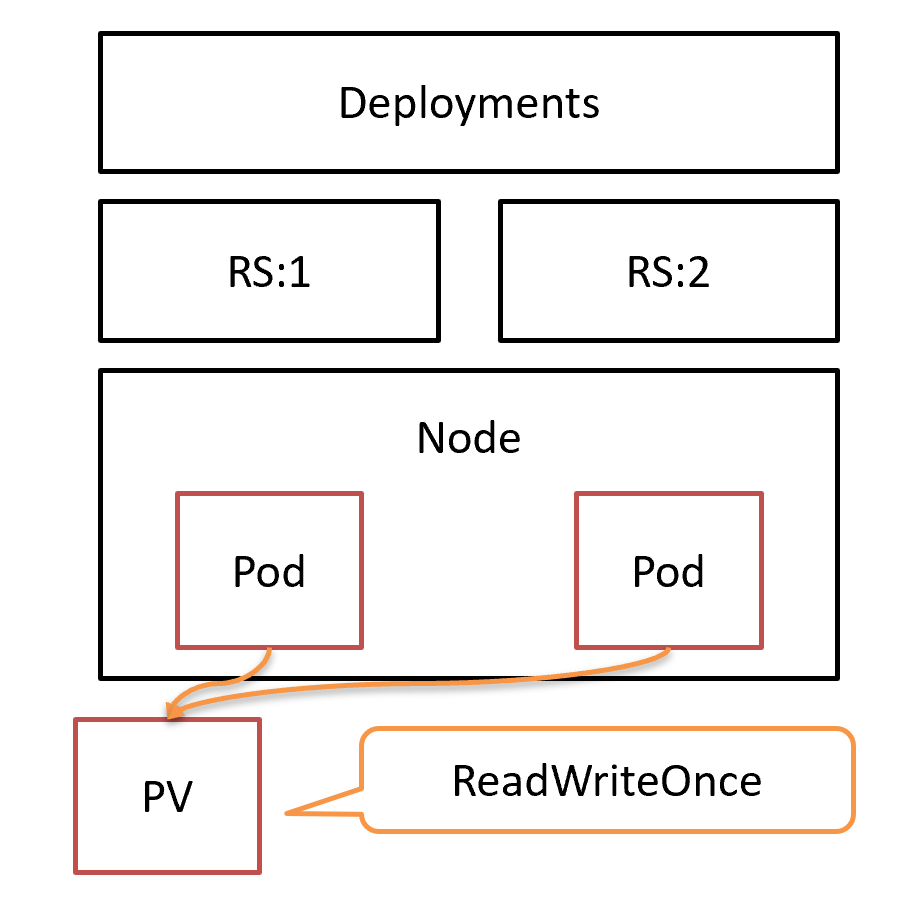
Helm テンプレートで記述されている Deployments のままでは、再配置のときに同じノードに Pod がスケジュールされると旧 Pod の終了前に新 Pod が起動してしまうことがあり、セーブデータが破損する恐れがあります。 Deployments のままでも定義によっては回避することはできますが、それ以外にも volumeClaimTemplates で PV を確保したり、 Pod 名を連番にしたり、そもそも DGS はステートフル(さらにオンメモリ、コネクションフル)なので StatefulSet のほうが比較的望ましいと思いました
|
1 2 3 4 5 6 |
apiVersion: apps/v1 kind: StatefulSet metadata: labels: app: minecraft name: minecraft |
volumeClaimTemplates にすることで ReadWriteOnce の状態で replicas が増えても安心。(増えても困るけど)
|
1 2 3 4 5 6 7 8 9 |
volumeClaimTemplates: - metadata: name: minecraft-datadir spec: storageClassName: ssd accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 50Gi |
GKE 標準の ParsistentDisk は HDD なので、セーブ時間を短くするために SSD を別途定義しておくとちょっと良くなると思います
定期バックアップ処理
CronJobs を利用する方法や ParsistentDisk のスナップショット機能を使う方法など検討しましたが、今回は sidecar で crond を動作させる方針に。一般的にコンテナ内では cron は動作していないのでこれを sidecar で動かしちゃおうという単純な仕組みで、ほかの要件でもマッチしやすいものです。 alpine にはいくつか定義が最初からあり、間隔にこだわりが無ければそこにファイルを置くだけで済みます。
|
1 2 3 4 5 6 7 8 |
$ docker run alpine cat /etc/crontabs/root # do daily/weekly/monthly maintenance # min hour day month weekday command */15 * * * * run-parts /etc/periodic/15min 0 * * * * run-parts /etc/periodic/hourly 0 2 * * * run-parts /etc/periodic/daily 0 3 * * 6 run-parts /etc/periodic/weekly 0 5 1 * * run-parts /etc/periodic/monthly |
今回は序盤は 15min に配置していたものの、途中でディスクが足りなくなり hourly に変更。こういうときもマニフェスト変更だけで済むので運用としては非常にラクチン
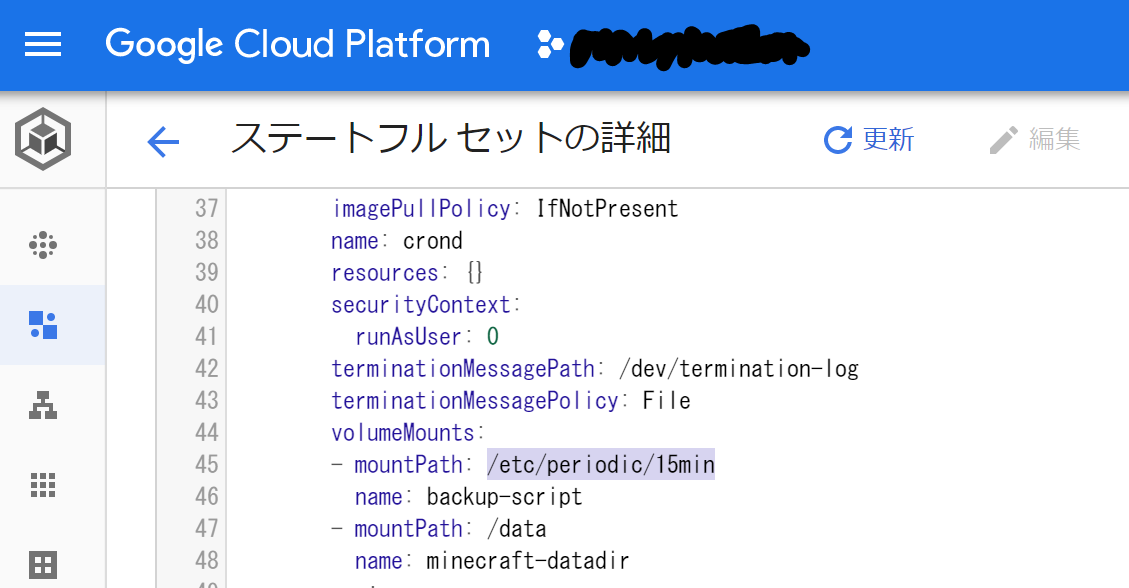
実際に実行する backup-script もマニフェスト定義だけで出来る。 volumeMounts には実行スクリプトとバックアップを取りたいマイクラの PV 名を指定するだけでオッケー
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: v1 kind: ConfigMap metadata: name: backup-script data: cron-backup-script: | #!/bin/sh DATE=`date +%Y%m%d_%H%M` cd /data tar -zcf backup/${DATE}.tar.gz reality echo "backup ${DATE}" cd backup find ./ -mtime +8 -delete |
GKE の場合、マニフェスト変更もブラウザコンソールで行えるので今回のお盆期間のように PC を持ち歩きたくないという気持ちにも答えられる。特にゲームやエンタメコンテンツは休日や連休などに大きなイベントを行うので、今回のような要件では git commit してからの一連のビルドを回して適応するなど効率が悪くなるだけと考えられます
アクセス制限
マイクラの文化的にサーバへは IP アドレスのみを入力して参加するケースが多いらしく、招待制の Discord サーバで共有することにしてもらいました。 SSH と違ってマイクラサーバを狙ってのポートスキャンも少ないだろうし、今回はホワイトリストによる運用は手間がかかると判断。シンプルに type: LoadBalancer を公開用、内部用に二つ作ってそれぞれ必要な方に IP アドレスを通知することにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: v1 kind: Service metadata: labels: app: minecraft name: minecraft 略 --- apiVersion: v1 kind: Service metadata: labels: app: minecraft name: minecraft-backdoor spec は一般的なもので、中身は同じ。 |
一つの Pod に対して LoadBalancer を二つ作るので費用効率は悪いけど、例えば IP が流出してしまったときには Service ごと削除し、また作れば新しい IP が付与されるし、イベント終了時間になったときにも Service をまるごと削除するだけで一般アクセスを遮断できるという運用がとても簡単なところがあります。特に終了時間は土曜日24:00ちょうどだったので、その時に対応出来る誰かが公開用 Service を削除するというとても簡単な運用でカバーしました。
通知など

通知は Reality でも使っている仕組みをそのまま利用。 Stackdriver のフィルタをマイクラ向けに作り、 PubSub 経由で CloudFunction で処理して Slack API を叩くだけ。 WARN 等の文字列にヒットしたら色だけ変えてます。
リソース設定
マイクラサーバは同時接続数によって負荷がだいぶ違うので、なかなか50人もの人が事前に集まらず見通しが難しかった。少し多めに Request しておいて、 Limit は掛けずに QoS Class を落とすことで Reality サービスに影響がでにくいようにしました。
|
1 2 3 |
$ kubectl describe pod | grep QoS | sort | uniq -c 22 QoS Class: Burstable 28 QoS Class: Guaranteed |
マイクラサーバは Burstable にして危ないときは落ちてもらう方針。
その他、対応したほうが良いが今回は見送ったもの
- JVM の詳細モニタリング。弊社ではあまり JVM 使われていなく、当案件程度でも対応するモチベーションが上がらなかった
- プレイヤー数やワールドの俯瞰などマイクラ特化モニタリング。別途定点カメラプレイヤーが 24h ライブ配信することで対応してしまった
- 設定ファイルの ConfigMap 化。プラグインごとにディレクトリが違って volumeMounts 書くのがめんどうだった。でもルートぐらいは ConfigMap にしたほうが間違いなく良さそう
- マイクラ固有のホワイトリストによるアクセス制限。運用がめんどうだった
- イベント終了に伴う kubectl は CronJobs に ClusterRole を与えて組み込むのが良さそうだけど、1回だけなので運用でカバー
まとめ
- DGS は工夫が必要で、ステートレスが前提な Kubernetes とは相性が良いとは言えない
- Dockerfile 作らなくてもマニフェストで結構カバーできる
- 既存サービスのクラスタを間借りできたのでモニタリングやリソース確保などの効率が良かった
- ゲームによっては世代バックアップやアクセス制御の実装があるけど、 Kubernetes の仕組みをうまく使えばゲームに詳しくなくても対応できる