スマホゲームの API サーバにおける EKS の運用事例
はじめに
こんにちは、インフラストラクチャ部の加藤です。
この度、新規スマホゲームの API サーバの部分で Amazon Elastic Kubernetes Service (EKS) を使ったものが正式リリースしました。
チームとしては Kubernetes の案件は今回が5件目で、EKS 利用は初の試みとなりました。
ゲーム名は非公開のため記事タイトルの主語が大きく恐縮ですが、リリース後の対応も落ち着いてきましたので本プロダクトにおける現時点での知見を共有したいと思います。
長くなるため、用語や Kubernetes の使い方の説明は省略しますが、EKS (Kubernetes) クラスタを運用する側として、どういった検討や対応が必要だったかなどについてご紹介したいと思います。
問題に対する手法は対象のシステムや組織によって最適な方法が異なる可能性が高いのであくまで参考程度として頂ければと思いますが、これから EKS を使ったシステムの運用を検討されている方の一助になりましたら幸いです。
2020/02/14追記: 図をいくつか追加しました。
TL; DR
- Kubernetes のバージョンアップは3ヶ月ごとにやってきます。従来の OS やミドルウェアと違って周期が短いため、バージョンアップの運用を回せるか導入前に検討しましょう
- AWS ALB Ingress Controller を使う場合、API のリトライ回数など適切な設定を行いましょう
目次
システム構成
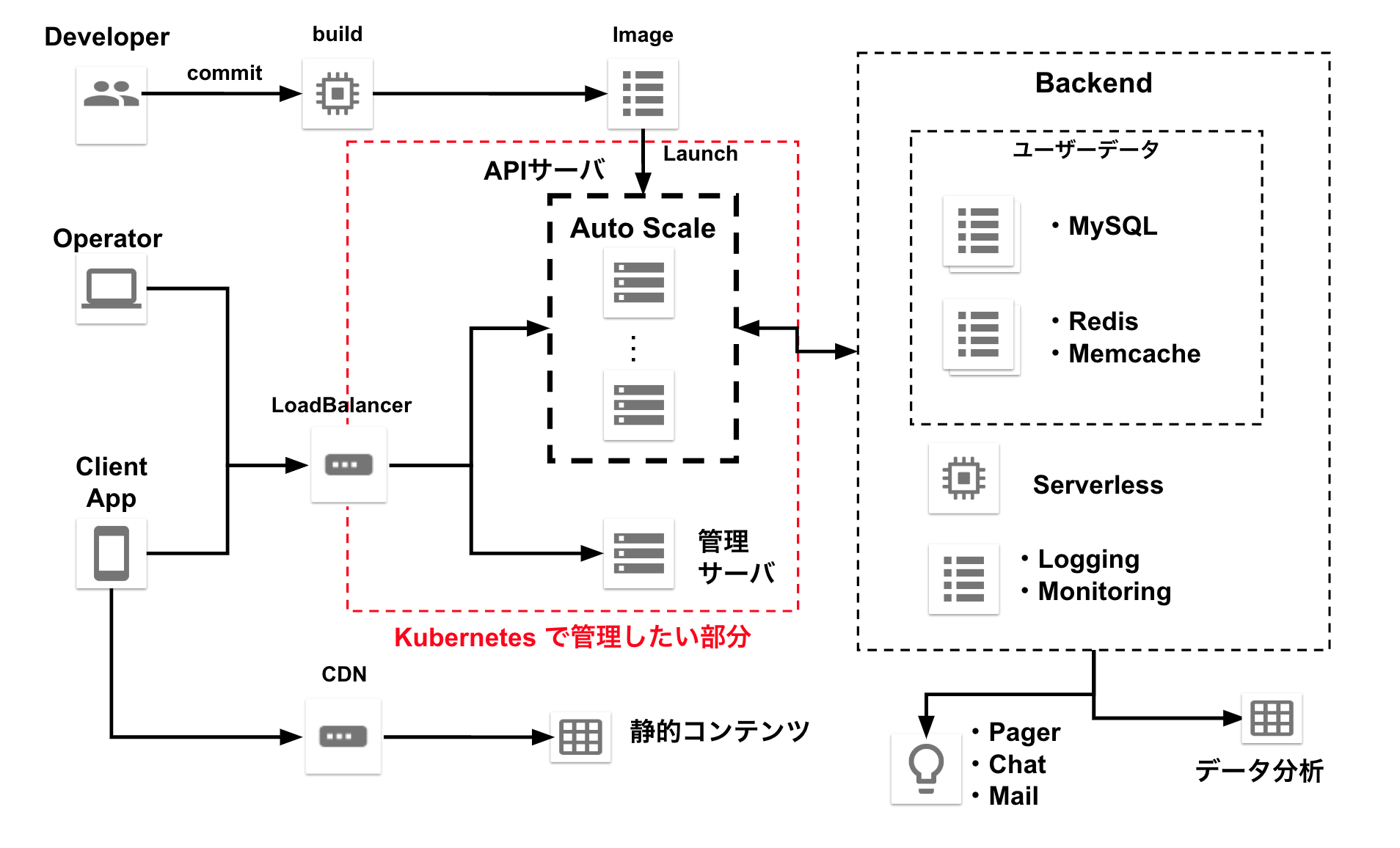
本プロダクトの API サーバ(以下、単に API サーバと記載します)の構成は、よくある ロードバランサー + Web/API サーバ + バックエンドのデータストア という3層のモノリシックな構成です。
利用しているミドルウェアは LAMP スタックを維持し、クライアントアプリからの API リクエストを処理するサーバとして PHP + Apache を、データストアとして Aurora(MySQL), Redis, Memcached を使用しています。
以下の図はクラウドに寄らず必要となる構成要素を描いたもので、細かいところは省略していますが、ざっくり赤色で囲った部分が今回 Kubernetes で管理を行いたい部分です。
実際に EKS(Kubernetes) を組み込んだ後の最終的なインフラ構成図がこちらです。
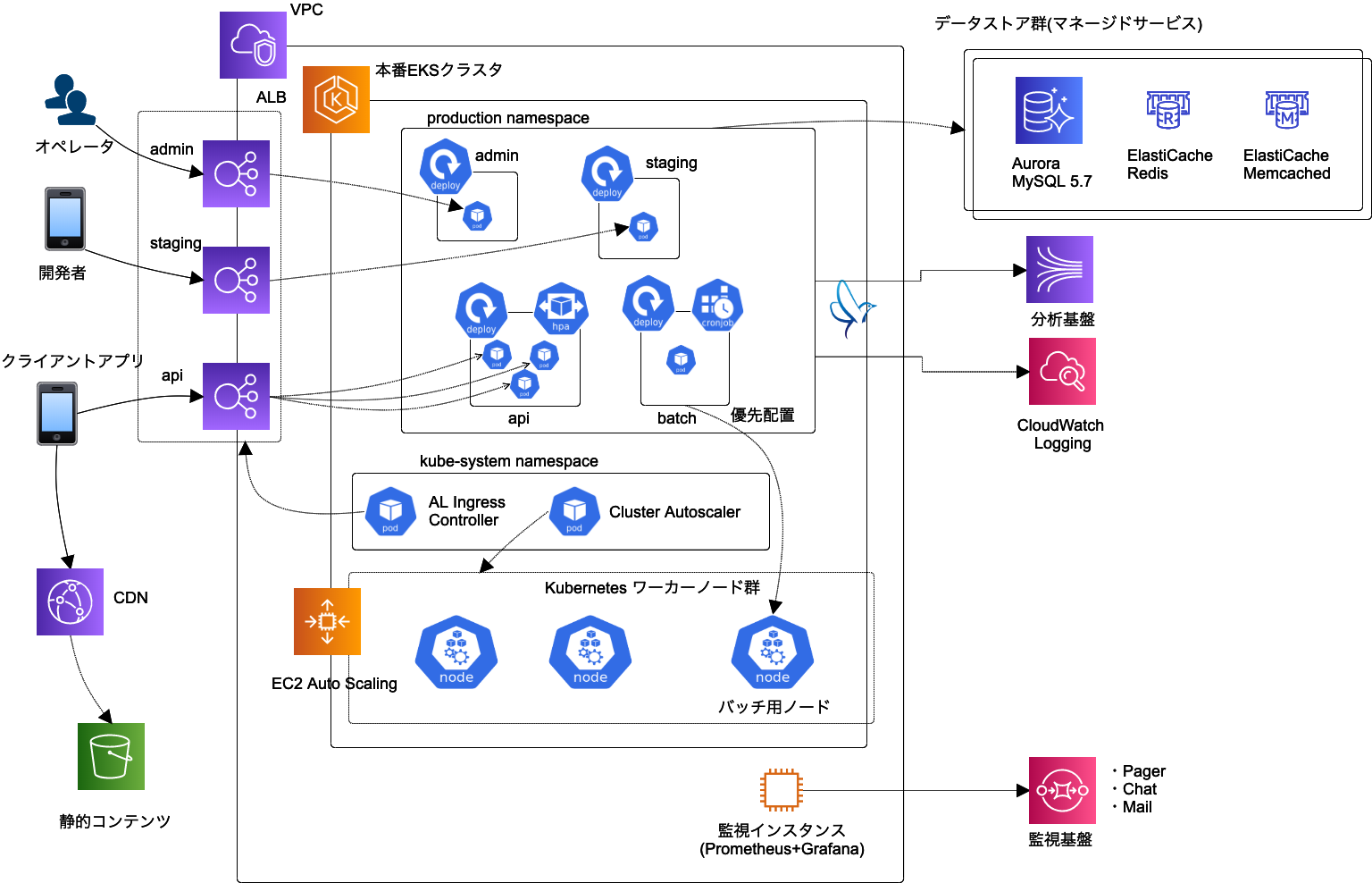
このようなシンプルなワークロードならば ECS の方が適しているという事実はありつつも、今回はどのパブリッククラウドを使うのか決めるのに時間をかけていた部分もあったのでどちらに転んでも良いように Kubernetes で準備を進めており、最終的には EKS を使った構成となりました。
入れているKubernetes アドオン
Helm
後述する Metrics Server や AWS ALB Ingress Controller などを入れるために利用しています。
Metrics Server
Kubernetes の 水平オートスケール(HPA)リソースを利用して、API サーバの Deployments の Pod 数をオートスケールするために利用しています。
HPA がオートスケールを判断するのに必要な指標(各 Pod の 割り当てCPU に対する使用率など)を収集します。
Cluster Autoscaler
EKS ワーカーノードのオートスケールのため利用しています
AWS ALB Ingress Controller
マニフェストによる ALB の管理や、Kubernetes Deployments リソースの Rolling Update 機能を利用する際に ALB Target Group への Pod の登録・削除を行ってもらうため利用しています。
導入時に検討したこと
プライベート IP アドレスはどのくらいあれば良いのか?
本プロダクトではリリース時ピークで 300 Pod, 100 ノード(c5.4xlarge)ぐらいの規模でしたが、使用しているサブネットの CIDR ブロック合計で /20 (IPアドレス4000個程度)だと足りないこともありました。
これは EKS のデフォルト CNI である Amazon VPC CNI プラグインの仕様によるものが大きいです。
Amazon VPC CNI プラグインは、ワーカーノードのごとに複数の Elastic Network Interface (ENI) を割り当てて、各 ENI ごとにまとまった数のセカンダリ IP アドレスを割り当て、そのセカンダリ IP アドレスはそのノードで動作する Pod への割り当て用として確保します。
Pod の起動時は、確保されたセカンダリ IP アドレスが割り当てられて、Pod 間や VPC 内の他のサービスとネイティブで通信できるようになります。

そして Amazon VPC CNI プラグインは、Pod の起動時にすぐにセカンダリ IP アドレスを割り当てできるように、あらかじめ未割り当てのセカンダリ IP アドレスをある程度の数確保しておく仕様があります。
この仕様のため、ワーカーノード起動時にまとまった数の IP アドレスが確保されます。
起動時に確保する数(デフォルト)は、以下の表のようにインスタンスタイプごとに異なります(*1) (2019年12月現在)
| インスタンスタイプ | 起動時に確保される IP アドレス数 |
| c5.large | 20 |
| c5.xlarge | 30 |
| c5.2xlarge | 30 |
| c5.4xlarge | 60 |
| c5.9xlarge | 60 |
| m5.large | 20 |
| m5.xlarge | 30 |
| m5.2xlarge | 30 |
| m5.4xlarge | 60 |
| m5.8xlarge | 60 |
*1 デフォルトでは Pod に割り当て可能なセカンダリ IP アドレスを ENI 1個分(その ENI に割り当てできる最大数)確保する設定ですが、実際には DaemonSet などがありすぐに ENI 1個分の空きという条件は満たさなくなるので、ワーカーノード起動時に ENI 2個分(「そのインスタンスタイプが ENI ごとに割り当てできる IP アドレス数」の2倍)が確保されるということになります。ドキュメントとしては次のリンクをご参照ください。
参考: https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/cni-env-vars.html
参考: https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md
例えば、ピーク時に c5.4xlarge のインスタンスが 50 個必要となる場合、デフォルトでは最低でも 60*50=3000 個の IP アドレスが必要になりますので、3000 個の IP アドレスを確保するには少なくとも /20 の CIDR ブロックを確保する必要があります。
/16 の CIDR ブロックが割り当てられているデフォルト VPC を利用するならたいていは十分だと思いますが、何らかの理由でより少ない CIDR ブロックで VPC 設計しているケースでは実際に IP アドレスが足りるのかどうか再確認した方が良さそうです。
時季や時間帯、アベイラビリティゾーンによっては多くの数の EC2 インスタンスを確保しづらいこともあるので、サブネット間でワーカーノードが偏ることがある点も注意が必要です。
運用を開始した後はどうすれば良いか?
Amazon VPC CNI プラグインには WARM_ENI_TARGET や WARM_IP_TARGET という設定オプションがあり、これによって起動時に確保する IP アドレスを調整可能のようです。
本プロダクトでは c5.4xlarge で IP アドレスが足りなくなったときは WARM_IP_TARGET を調整せずに、Pod の Requests/Limits Resource を大きくしつつ、c5.9xlarge を使うことで IP アドレスを節約したりしました。
また、VPC にセカンダリの CIDR ブロックを割り当てて、後から新しいサブネットを追加することもできます。
EKS クラスタを追加する際、ワーカーノードを配置するサブネットは選択すると思いますが、あれは RDS や ElastiCache のサブネットグループのようなイメージで、各ワーカーノードの kubelet が EKS コントロールプレーン(Kubernetes の API サーバ)と通信するためのエンドポイントとなる ENI が配置されるサブネットを指しています。
そのため、後から同じ VPC 内にサブネットを追加しても、セキュリティグループが適切に設定されていれば、後から追加されたサブネットに置いたワーカーノードから EKS コントロールプレーンには問題なく疎通できます。
ワーカーノードを安全に削除するにはどうするか?
最近(2019年の re:Invent 付近で)発表された EKS のノード関連のアップデートである Managed Node Groups や EKS on Fargate は本プロダクトのリリース時点では間に合わなかったので、今回は非マネージドなワーカーノードの管理について触れたいと思います。
ワーカーノードは EC2 インスタンスなので Reboot や Retirement の Scheduled Event が発生することがありますし、インスタンスタイプを変更したいといったケースも出てくると思います。
ワーカーノードは Auto Scaling グループ(ASG) 管理なわけですから、そういったときは気軽に ASG のヘルスチェックを Unhealthy にして、新しいインスタンスに置き換えられるようになっていると便利です。
ワーカーノードを安全に削除するには、Kubernetes の Drain やログの回収を確実に行ってからインスタンスを終了してもらう必要がありました。
ASG はライフサイクルフックの実行完了を待ってからインスタンスの終了に移ることができるので、そのライフサイクルフックの中でそれらの処理を行なっています。
Kubernetes の Drain
Kubernetes の Drain は、ノードを停止させる前段階として、そのノードへの新規 Pod のスケジューリングをできないようにした上で、そのノード上で既に動いている Pod を追い出す機能です。
追い出された Pod は Kubernetes の Auto healing 機能によって、代わりとなる Pod が別ノードで新しく立ち上がります。
また Drain によって Pod が追い出されるとき、Pod Disruption Budgets (PDB) の範囲内で行われるので、安全に追い出しできるまで待ってくれることも期待できます。
本プロダクトでは、この Drain 処理のために次の Lambda を利用しています。
(後述のログ回収確認のライフサイクルフックと並行利用するため、タイムアウトを長くして使っています)
Managed Node Groups にはこの Drain 機能が一緒に付いてくるようですので、今であれば PDB だけ適切に設定しておき、Drain は Managed Node Groups の機能に任せるのが良さそうです。
ログ回収の確認
Web サーバのアクセスログ、アプリケーションのエラーログ、アプリケーションの分析用ログなど多くのログがありますが、今回はこれらのログを何らかのログ収集基盤に転送・集約することを考えます。
EKS では CloudWatch Container Insights を入れると、CloudWatch Logs に各コンテナの標準出力と標準エラー出力が転送されるようになります。
本プロダクトでは独自設定の Fluentd DaemonSet を配置し、各コンテナの標準出力と標準エラー出力をその内容によって、CloudWatch Logs や Amazon Kinesis などに振り分けて転送しています。
Fluentd には buffer があり未転送のログが残っている可能性があるので、ワーカーノードの終了時は ASG のライフサイクルフックで Fluentd buffer が捌けるのを待つ処理を挟むことで、未転送のログが欠損することをなるべく避けるような工夫をしています。
オートスケールはどうするか?
本プロダクトでは、基本的な戦略としては Pod のオートスケールは Kubernetes の Horizontal Pod Autoscaler (HPA) リソースで、ワーカーノードのオートスケールは Cluster Autoscaler でやっています。
Cluster Autoscaler は、新しく作成された Pod がどのノードにもスケジュールできない Pending 状態になっていることを検知すると、必要な数のワーカーノードが増えるように Auto Scaling グループ(ASG)の Desired Capacity (希望インスタンス数) を増やします。
そうすることで EC2 インスタンスが立ち上がり、Kubernetes のワーカーノード として登録されて、Pending 状態だった Pod がスケジューリングできるようになります。
このスケールアウトプロセスでは Pod が Pending 状態になってから初めて EC2 インスタンスが立ち上がるため、スケールアウトに数分程度の時間を要します。
スマホゲームのようにスケジュールに沿って運営されているサービスでは、急激に負荷が上がることが予測されるタイミングでは事前に EC2 インスタンスを立ち上げておきたいというケースもあります。
そのようなケースにおいては、ASG には Scheduled Action という機能があるので、あらかじめ決まった時間帯だけ最低インスタンス数(Min)、 希望インスタンス数(Descired Capacity) を変更することができます。
Scheduled Action によって変更された Min や Descired Capacity の値をどのように Cluster Autoscaler に伝えるかという問題もありますが、Cluster Autoscaler には ASG の Auto Discovery という便利な機能があります。
Discovery 用のタグを ASG に設定しておけば自動で ASG の Min、Descired Capacity が変わったことを Cluster AutoScaler が検知してくれます。
また、Cluster Autoscaler はノードの CPU やメモリの予約(Request)率が低い状態がデフォルトで10分間続くと、そのノードを削除するスケールイン機能があります。
Scheduled Action で増やしたインスタンスが 10分後に削除されて困るという場合は、--scale-down-unneeded-time を延ばしておくと良いでしょう。
本プロダクトでは、--scale-down-unneeded-time=30m に設定しています。
各 Pod の Resource Request/Limit をどう設定するか、どの EC2 インスタンスタイプを使うかといった部分は現状手探りです。
基本的には Pod 数 や EC2 インスタンス数は突然のインスタンス障害などを考慮して、ある程度の数を並べつつ、一方で Pod 数や EC2 インスタンスが増えすぎると AWS API コール数が増えすぎるので、スペックアップして数を抑えるといった対応を行っています。
バッチ処理をどう隔離するか?
スマホゲームに限らず、定常的な運用を回すために自動化された処理(ジョブ)を定期実行したいというケースがあると思います。
例えば、システム運用の文脈では不要データの削除やパッチの適用、Webアプリケーションの運営という文脈ではユーザーアクティビティの集計処理、スマホゲームの運営という文脈ではランキング結果に応じた報酬の付与処理などです。
こういったバッチ処理を行う Pod (以下バッチ)は、ワーカーノードの停止による中断を極力避けたいという要件もありました。
一方で Auto Scaling グループ (ASG) 管理下のインスタンスは気軽に入れ替えできるようにしてワーカーノードのメンテナンスのしやすさを維持したいという要件もあるため、バッチは専用のワーカーノードに隔離し、通常のワーカーノード用の ASG とは別にバッチ用ワーカーノードの ASG を用意することにしました。
専用のワーカーノードを確保するとして、そのワーカーノードにバッチ以外の Pod をスケジューリングさせないようにする(Taints)対応とバッチ Pod のスケジューリング時に、専用のワーカーノードの Taints を許容する(Tolerations)と共に、専用のワーカーノードに優先配置する(Affinity)といった対応が必要です。
まず、バッチ用ワーカーノードのユーザーデータ(起動時の実行スクリプト)には、以下のように Kubernetes ノードに付ける Labels と Taints を設定しています。
|
1 2 |
/etc/eks/bootstrap.sh ${ClusterName} ${BootstrapArguments} \ --kubelet-extra-args '--node-labels=node.kubernetes.io/extra-node=batch --register-with-taints=app=batch:NoSchedule' |
このユーザーデータで起動してきたノードには、以下のように Labels と Taints が設定されています。
|
1 2 3 4 |
$ kubectl describe node ip-10-110-192-151.ap-northeast-1.compute.internal | grep -e Taints -e node.ku -e Label Labels: beta.kubernetes.io/arch=amd64 node.kubernetes.io/extra-node=batch Taints: app=batch:NoSchedule |
Effect(右端)=NoSchedule なので、この Taints を許容できる Pod 以外はスケジューリングされなくなりました。
デフォルトだと DaemonSet もスケジューリングされなくなるので、Taints を設定したノードにも DaemonSet の Pod をスケジューリングさせるには DaemonSet に以下のような Tolerations が必要になります。
|
1 2 |
tolerations: - operator: "Exists" |
そして、バッチ処理を行う Pod には以下のような Tolerations を設定することで明示した Taints を許容して、専用のワーカーノードがスケジューリング候補に含まれるようになります。
|
1 2 3 4 |
tolerations: - key: "app" value: "batch" effect: "NoSchedule" |
しかしこれだけだと、数あるワーカーノードの1つとして、専用のワーカーノードを選択できるようになっただけで、実際に割り当てられるノードは別のノードになることがあります。
そのため、バッチ処理を行う Pod に Affinity を合わせて設定することで、専用のワーカーノードに優先してスケジューリングさせることができます。
先に専用のワーカーノードのユーザデータで識別用の Labels を付けておいたので、それを使って Affinity を設定します。
以下の例では、できるだけ専用のワーカーノードにスケジュールし、専用のワーカーノードにリソースの空きがない場合は他のワーカーノードで実行する設定になっています。
|
1 2 3 4 5 6 7 8 9 10 |
affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: node.kubernetes.io/extra-node operator: In values: - batch |
Kubernetes (EKS) バージョンのアップグレードはどうしていくか?
AWS公式からアナウンスされている通り、約90日おきに新バージョンがリリースされる Kubernetes に追従するため、EKS では少なくとも3つのバージョンをサポートします。
その当時の最新バージョンで EKS クラスタを作成したとしても約180日から約270日程度経てばそのバージョンは廃止となるので、定期的に新しい Kubernetes バージョンにアップグレードする運用が必要になります。
EKS クラスタをインプレースでアップグレードする手順は、公式マニュアルに記載されています。
手順を見てみると、Kubernetes バージョンごとに EKS により管理されているコンポーネント(Amazon VPC CNI プラグイン、CoreDNS, kube-proxyなど)については、サポートされているバージョンが決まっているようです。
しかし、自分たちで入れた EKS 管理外のアドオン(ClusterAutoscaler や AWS ALB Ingress Controller など)もそれ自体新しいバージョンが出続けるものであり、新しい Kubernetes バージョンとそれらのアドオンのバージョン互換性も気になるところです。
例えば、Cluster Autoscaler は Kubernetes のバージョンに合わせて、ClusterAutoscaler のバージョンもアップグレードするのが推奨になっています。
どのみち公式手順でも本番環境のクラスタをアップグレードする前に新しい Kubernetes バージョンで自分たちのアプリケーションが動くかは事前の検証が必要ということになっていますし、運用中のクラスタをインプレースでアップグレードするのは今はまだ避けた方が良いと個人的に思っています。
インプレースでアップグレードしない場合、新しいバージョンの EKS クラスタを新しく作って、クラスタレベルでの Blue/Green デプロイのようにして移行する方法になります。
今回のプロダクトでは新しいクラスタとノードグループなどを CloudFormation 一発で立てられるようにしていますが、自分たちで入れる各アドオンはそれぞれバージョンの選定をしてインストールする形にしています。
クラスタごと移行する方法のメリットとして、サービスのトラフィックを移行する前に、自分たちで入れたアドオンのバージョンアップグレード検証やアプリケーションの動作確認などをゆっくり行えるという点があります。
なおクラスタを複数立てる場合は、複数の EKS クラスタから同じ AWS リソース(Auto Scaling グループや ALB など)を操作しないように注意が必要です。
今回の構成では AWS リソースの管理を行うアドオンは AWS ALB Ingress Controller と ClusterAutoscaler のみだったので、これらについてどのようなことに注意すれば良いか、それぞれ見ていきます。
AWS ALB Ingress Controller
AWS ALB Ingress Controller が作る ALB 名はどのように決定されているのでしょうか。
ソースコードを見ると、ALBNamePrefix, namespace, ingressName によって一意に定まるようです。
ALBNamePrefix がクラスタごとにユニークな値であれば、クラスタごとに異なる ALB が出来上がるので競合を避けられそうです。
ALBNamePrefix は --alb-name-prefix オプションのことで、その名の通り ALB 名の Prefix となるのでなるべく短い値を付けるのをおすすめします。
クラスタごとに ALB が作成されるので、新しいクラスタへ移行する際はドメインの CNAME 先を新しく作られた ALB に変更する必要があります。
この手法だとクラスタ移行のタイミングで DNSレベルの変更が必要になるので、それを避けたい場合は AWS ALB Ingress Controller を使わないという選択肢も検討するのが良いかもしれません。
ちなみに、複数のクラスタ(の AWS ALB Ingress Controller)から単一の ALB を管理することはできません。
なぜならクラスタごとに ALB のターゲット(として登録する NodePort や Pod の IPアドレス)が異なるので、各クラスタの AWS ALB Ingress Controller が永遠とターゲットの追加と削除を繰り返すからです。
ClusterAutoscaler
新しいクラスタを立てる際にワーカーノードの Auto Scaling グループも新しいものが作られるので、ClusterAutoscaler をデプロイする際に新しい ASG を指定する必要があります。
ASG を静的に指定している場合は ASG の ARN を、ASG の Auto Discovery 機能を使っている場合は ASG のタグ(クラスタ識別用)を変更します。
ExternalDns
今回の構成には入っていませんが、AWS ALB Ingress Controller と組み合わせて使うと ALB の設定から Route 53 へのレコード登録までやってくれる非常に便利なアドオンです。
クラスタ移行の際は AWS ALB Ingress Controller により新しい ALB が作られるのでドメインの向き先を変更する必要がありますが、ExternalDns を入れた状態でそれを管理するのは複雑になるため、本番環境では ExternalDns は使わないことにしました。
(開発環境用のクラスタには入れてあり重宝しています)
負荷試験中や運用開始後に発生した問題
DNS の名前解決に失敗する
PHP + Apache 特有の事情
PHP + Apache(mod_php) は、
- 各 HTTP(S) リクエストごとに必要なミドルウェアサーバ(MySQL, Redis, Memcached など)と通信を行う際に、コネクションプーリングや持続的接続(pconnect) を使わなければ、都度接続&切断を行う
- 接続を行う際、接続先のエンドポイントが名前ならば、それを名前解決するがデフォルトでは結果をキャッシュしない
のため、名前解決リクエストが増えやすいという事情があります。
Kubernetes 特有の事情
Pod の DNS リゾルバー設定(/etc/resolv.conf) はデフォルトだと、例として以下のようになっています。
|
1 2 3 |
nameserver 172.20.0.10 search default.svc.cluster.local svc.cluster.local cluster.local ap-northeast-1.compute.internal options ndots:5 |
この ndots というのは、名前解決したいドメイン名にドットが X 個含まれているとすると、
- X < ndots のときは、先に search に列挙したドメインで補完して、ヒットするまで順次名前解決していく
- hoge.example.com の場合: hoge.example.com.default.svc.cluster.local -> hoge.example.com.svc.cluster.local -> … -> hoge.example.com
- X >= ndots のときは、まずは search で補完せずに、FQDN として名前解決を試みる
というオプションです。
ndots (Linux デフォルトは1)が多く設定されているのは、Kubernetes 内でのサービスディスカバリの利便性を追求するためのようです。
一方で、Kubernetes 外にあるサービスのエンドポイントがドメイン名で、ドット数が5未満であれば、先に search で補完して名前解決が試されてしまうので、ヒットしない名前解決リクエストが意図せず増えてしまうという問題がありました。
またそれとは別に、Kubernetes クラスタには kube-dns という DNS サービスがあり、デフォルトで各 Pod からの名前解決リクエストは kube-dns に飛びますが、kube-dns はデフォルトだと 2 Pod 固定のため、負荷が集中しやすい構成になっています。
AWS が提供する VPC 内の DNS サーバの制限
RDS や ElastiCache はエンドポイントがドメイン名で提供されるので、これら Kubernetes 外で管理されるドメイン名は VPC 内の DNS サーバにフォワードされます。
この DNS サーバは 1 ENI あたり 1024 パケット/秒 の制限があるので、ここも引っかかりやすいポイントです。
回避方法
これらの問題に対して本プロダクトでは、以下のようにして DNS の問題を回避しています。
- 接続先エンドポイント(FQDN) の最後にドットを付けて、search による補完を回避する
- ndots を 1 にする
- アプリケーション Pod にサイドカーとして DNS キャッシュサーバを付ける
- クラスタ内の kube-dns にオートスケールを導入する
kube-dns のオートスケールというのは、cluster-proportional-autoscaler を使うことでノード数やコア数などに応じて kube-dns サービス (CoreDNS の Pod 数)をスケールさせるものです。詳しくは Kubernetes 公式のマニュアル(英語) をご参照ください。
DNS のキャッシュというタスクをアプリケーションのタスクと考えるか、インフラレイヤのタスクと考えるかで、サイドカーとして入れるべきかどうかは変わってくるかもしれません。
インフラレイヤでの対応手法としてはもう1つ、 NodeLocal DNSCache というのが Kubernetes のアドオンとして提供されています。
NodeLocal DNSCache は DaemonSet として各ノードに DNS キャッシュサーバが立つもので、1.15 から HA 機能が付いて beta に昇格しました。
ローリングアップデート時に ELB 502 エラーが多発する
Pod がすぐ終了してしまって、エンドポイントから削除する処理が間に合わない
まず前提として、今回の構成では AWS ALB Ingress Controller を使って ALB のターゲットグループ管理を行っています。
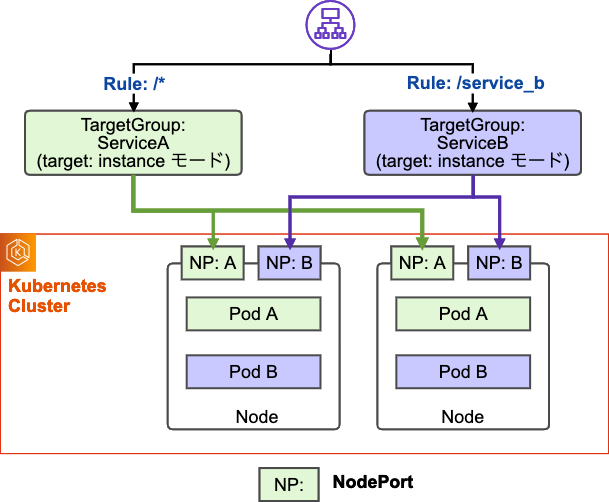
AWS ALB Ingress Controller には、2つのターゲットタイプ(Ingress トラフィックモード) があります。
- instance モード: ALB のターゲットグループには、全てのワーカーノードの IP アドレスと NodePort Service 用に割り当てられた nodePort の組み合わせで登録されます。ALB で受けたリクエストは NodePort Service を介して、エンドポイントに登録されたいずれかの Pod にルーティングされます。
- ip モード: ALB のターゲットグループには Service のエンドポイントとなる 各 Pod の IP アドレスが登録されます。ALB で受けたリクエストはターゲットグループに登録されたいずれかの Pod に直接到達します。
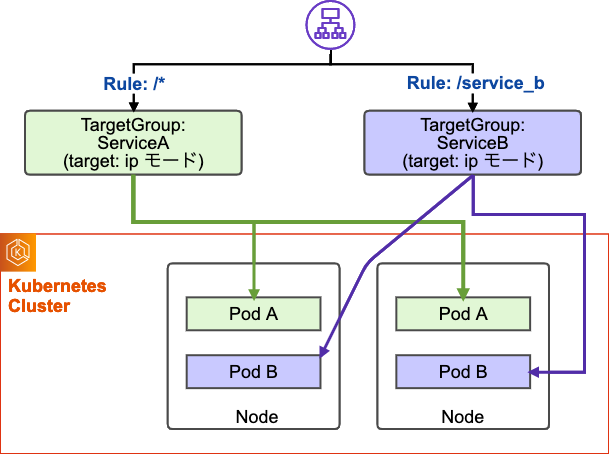
今回のプロダクトではターゲットタイプを ipモードで利用しています。
見出しの問題に戻ると、Pod の終了時に ELB 502 エラー(CloudWatch メトリクスの HTTPCode_ELB_502_Count)が出るとすれば、それは ALB の ターゲットグループから Pod の IP アドレスが削除されていない状態で、Pod 内の HTTP リクエストを受けるコンテナが終了した(ALB からのリクエストがノードに到達しても TCP RST が返される状態になった)ケースが多いと思います。
Pod の終了処理(preStop フックを呼び出した後にコンテナに SIGTERM を送って終了させる) と Service のエンドポイントから削除する処理は非同期で行われるため、上記のようなことが起こり得るようです。

Pod の終了処理について、以下の記事が大変参考になります。
この問題の回避方法としてよく見る方法が Pod の終了処理(preStop フック)の中で 一定時間 sleep するという方法です。
本プロダクトでは、Pod の終了猶予時間(terminationGracePeriodSeconds, デフォルト30秒) を 50秒に変更した上で、preStop の中で 40秒間 sleep することで、エンドポイントから削除され ALB のターゲットグループから削除されるのに十分な時間を確保することにしました。
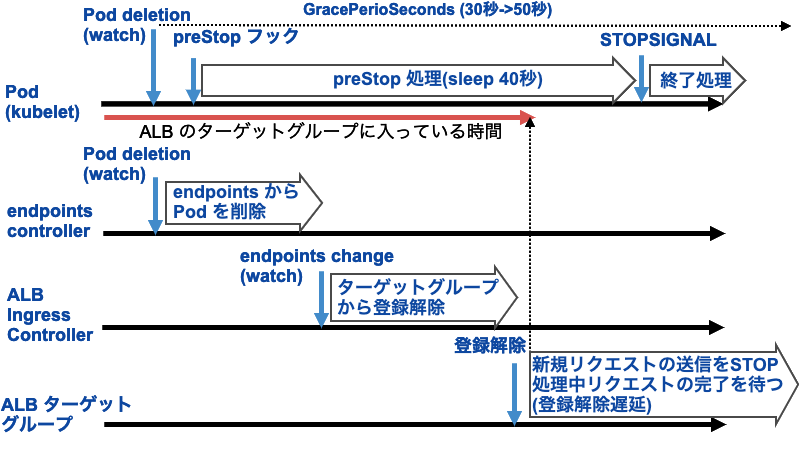
AWS API コールがスロットリングして、ターゲットグループから削除する処理が遅延する
上記のように、Service のエンドポイントから削除されてターゲットグループから削除されるのに十分な時間を置いているにもかかわらず、Pod 数が多くなるとローリングアップデート時の ELB 502 エラーが再発しました。
EKS の Audit ログ(endpoint controller のリクエストログ)や Pod の終了時ログ、AWS ALB Ingress Controller のログなどを突き合わせてみると、Pod の終了処理に移ったタイミングで Endpoints から削除されているにも関わらず、ALB Ingress Controller がターゲットグループから削除する処理が遅れていることが分かりました。
例としてターゲットグループからの削除が遅れた Pod に関するログを整形・抜粋すると、
- 03:52:27: (Controller / kubelet) Pod 削除開始
- 03:52:27: (Endpoint Controller) Endpoints から削除
- 03:53:07: Apache 終了 (このタイミングで ALB からのリクエストには TCP RST が返され、ELB 502 エラーが発生)
- 03:53:25: (ALB Ingress Controller) ターゲットグループから削除
となっていて、正常時でならば 03:52:27 頃にターゲットグループから削除される処理が行われるはずですが、何故か1分程度遅れて 03:53:25 に削除されています。
ALB Ingress Controller はその間何をしていたかログを見てみると、03:51:30 ~ 03:53:22 の間止まっているように見えました。
|
1 2 3 4 5 |
I1120 03:51:30.245557 1 listener.go:283] production-ap/api-ingress: Domain name '*.(省略)', matches TLS host '(省略)', adding to Listener I1120 03:51:30.245576 1 listener.go:236] production-ap/api-ingress: Auto-detected and added 1 certificates to listener I1120 03:53:22.525821 1 listener.go:283] production-ap/stg-ingress: Domain name '*.(省略)', matches TLS host '(省略)', adding to Listener --- 省略 --- I1120 03:53:25.009571 1 targets.go:95] production-ap/api-ingress: Removing targets from arn:aws:elasticloadbalancing:ap-northeast-1:(省略):targetgroup/(省略): 10.111.34.200:80, 10.111.45.83:80, 10.111.37.96:80, 10.111.40.60:80, 10.111.37.73:80, 10.111.34.80:80, (省略) |

さらに、問題が再発した別の日の CloudTrail の API コールのログ抜粋ですが、ALB Ingress Controller が止まっているように見えるとき、どうも API コールが連続してスロットリングしているようでした。これが怪しそうです。
|
1 2 3 4 5 6 7 |
2019-11-21 13:16:12.000 +0900 DescribeTargetGroups Throttling 2019-11-21 13:16:13.000 +0900 DescribeTargetGroups Throttling 2019-11-21 13:16:14.000 +0900 DescribeTargetGroups Throttling 2019-11-21 13:16:18.000 +0900 DescribeTargetGroups Throttling 2019-11-21 13:16:22.000 +0900 DescribeTargetGroups Throttling 2019-11-21 13:16:36.000 +0900 DescribeTargetGroups Throttling 2019-11-21 13:16:59.000 +0900 DescribeTargetGroups 成功 |
ALB Ingress Controller は aws-sdk-go を利用していて、この SDK には自動リトライと指数バックオフが実装されています。
これはリトライ回数が増えると、次のリトライまでの時間が徐々に長くなることになります。
ALB Ingress Controller はデフォルトで最大10回のリトライを行う設定なので、運悪くスロットリングが連続してしまうと、最悪ケースでは分単位のリトライ待ちが発生してしまい、そのリトライ待ちにより後続の処理が遅延してしまうというのが今回の原因のようでした。
今回は暫定対応としてこのリトライ回数を10回から4回(--aws-max-retries=4)に減らすことで、ELB 502 エラーは解消しました。
ALB Ingress Controller には AWS API コールのリクエストログを出力するオプション(--aws-api-debug=true)があるので有効化した上で、実際に4回で、最初のリクエストから14秒で諦めていることも確認できました。
|
1 2 3 4 5 6 7 8 9 |
I1125 05:28:49.824429 1 rules.go:82] production/support-ingress: modifying rule 1 on arn:aws:elasticloadbalancing:ap-northeast-1:(省略):listener/app/(省略) I1125 05:28:49.824579 1 api.go:2573] Request: elasticloadbalancing/ModifyRule, Payload: (省略) I1125 05:28:50.818095 1 api.go:2573] Request: elasticloadbalancing/ModifyRule, Payload: (省略) I1125 05:28:52.612823 1 api.go:2573] Request: elasticloadbalancing/ModifyRule, Payload: (省略) I1125 05:28:55.850761 1 api.go:2573] Request: elasticloadbalancing/ModifyRule, Payload: (省略) I1125 05:29:03.261882 1 api.go:2573] Request: elasticloadbalancing/ModifyRule, Payload: (省略) E1125 05:29:03.301916 1 api.go:2573] Failed request: elasticloadbalancing/ModifyRule, (省略) status code: 400, request id: (省略) E1125 05:29:03.301939 1 rules.go:91] production/support-ingress: failed modifying rule 1 on arn:aws:elasticloadbalancing:ap-northeast-1:(省略):listener/app/(省略) due to Throttling: Rate exceeded |
根本的には、
- ip モードだと Pod の入れ替えの度に、ターゲットグループへの追加と削除が発生してしまい、その度に ALB 周りの Reconcile のループが走るのは効率が悪い (API コールもどうしても増えてしまう)
という問題が残っています。
次の図は、ローリングアップデート時に ALB Ingress Controller がどのような API コールを送っているかを示したものです。
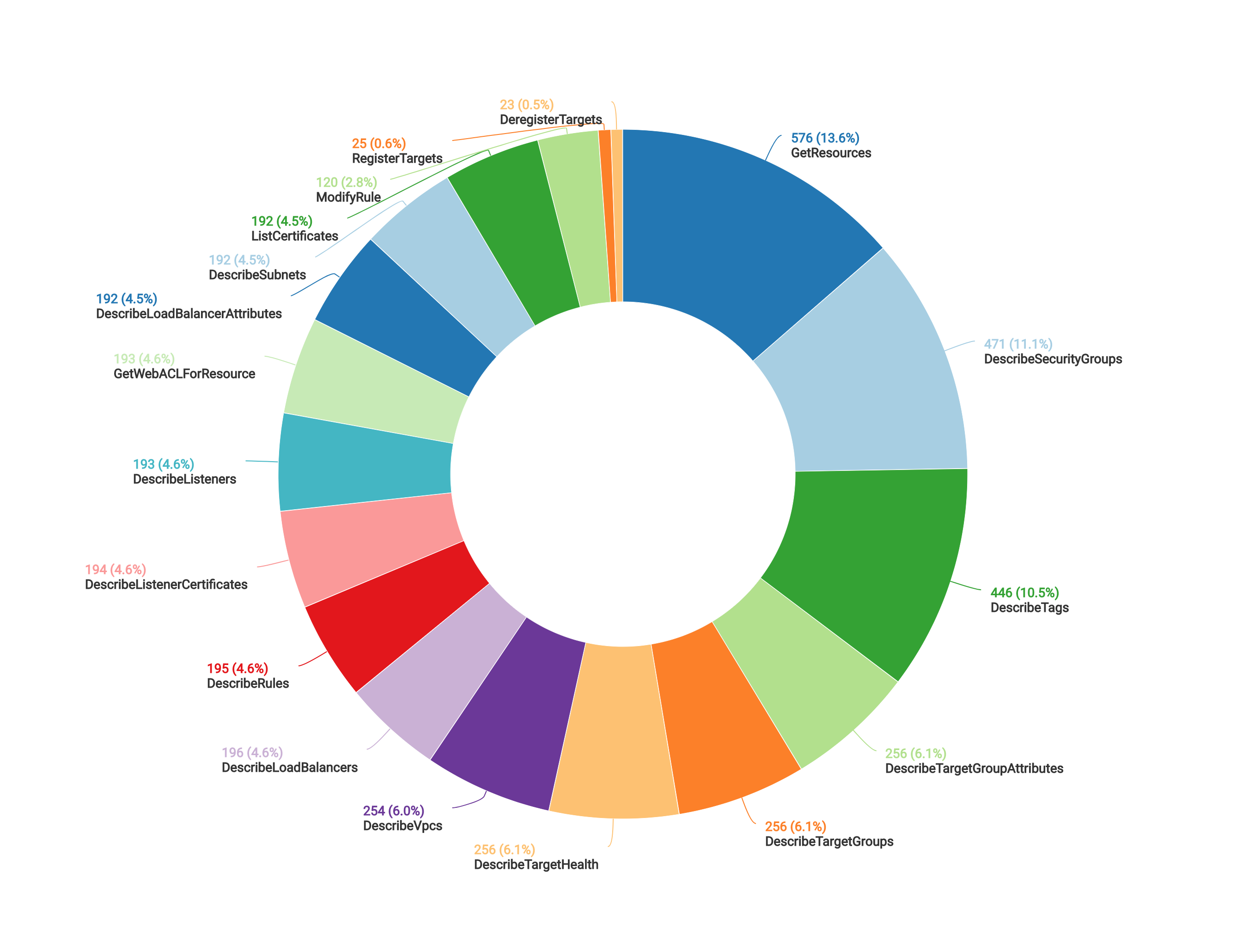
ローリングアップデート時において重要かつ専念してほしいのは、ターゲットグループからターゲットを追加・削除する API コール(RegisterTargets, DeregisterTargets)ですが、それ以外の API にもまんべんなくアクセスしており、Pod が入れ替わる度に ALB 周り全てを Reconcile ループで調整するという仕組みや使い方だとオーバーヘッドが大きいことが分かります。
根本的な解決のため、instance モードでの利用やそもそも ALB Ingress Controller を使わない構成についても今後の課題としています。
この問題については EBC やサポートを通じてサービスチームにフィードバックして頂いたので、今後の改善に期待しています。
他にも
- CloudWatch Logs に全ての stdout / stderr ログを送っていたら、取り込み(Ingest) 料金が高くなった
- アプリケーション Pod が stdout に吐いている分析用の JSON ログをワーカーノードの /var/log/containers 以下から回収していたところ、JSON ログが 16KB を超えたあたりで分割されてしまいパースできなくなる
といったことはありましたが使い方の問題によるものが多いので、今回は詳細をスキップします。
上で挙げた問題以外は大きな問題もなく、サービス停止メンテナンスが必要となるようなシステムトラブルもなく運用開始できております。
おわりに
EKS の進化は著しく、直近では Managed Node Groups や EKS on Fargate といった Node 周りのマネージド化がだいぶ進みました。
AWS のコンテナロードマップを見ると、今回導入にあたり検討が必要だったことも将来的には不要となるような改善が予定されています。
例えば、VPC の IP アドレスが多く消費される課題に対しては「Next Generation AWS VPC CNI Plugin」だったり、Kubernetes バージョンのアップグレード時に自分たちで入れているアドオンのバージョン互換性という問題に対しては「Managed Cluster Addons」がある程度解決してくれそうです。
- [EKS]: Next Generation AWS VPC CNI Plugin #398: https://github.com/aws/containers-roadmap/issues/398
- [EKS]: Managed Cluster Addons #252: https://github.com/aws/containers-roadmap/issues/252
本番環境での導入事例が増えればフィードバックが増えてさらに良くなっていくと思いますので、採用事例がもっと増えてくれると良いなと思っています。