Capistrano ではじめるオートスケーリング
インフラの駒崎です。
Capistrano を使ったデプロイから、オートスケーリングをスムーズに導入するための弊社事例を紹介させていただきたいと思います。
こんな方へ
本稿で想定するのはこのような状況です。
- Capistrano を使って中央管理型デプロイをしている
- AWS などのクラウドインフラを使ってオートスケーリングをやりたい
- オートスケーリング時のデプロイをどうするか検討している
- コンテナベースのデプロイやブルーグリーンデプロイには準備が足りない
理想は見えているもののなかなか進まない状況から、できるだけスムーズに改善を重ねることを目指します。
本稿のゴールは AWS でオートスケーリングを実現することです。
過度な一般化を避けるため、本稿では AWS 環境を前提として記述します。
オートスケーリングに必要なもの
スケーリングのサイクルは、おおまかに次のように考えられます。
- イメージからインスタンスを起動する
- 起動したインスタンスを最新の状態にする
- ロードバランサに関連付けサービスイン
- 不必要になったらサービスアウト
- ログの確実な回収など終了処理を行う
- インスタンスを破棄する
AWS の Auto Scaling Group (ASG) を使うと、2, 5 を除く全てを AWS に任せることができます。
さらに ASG の Lifecycle Hook を使うことで、2, 5 のタイミングでユーザが任意の処理を行えるようになりますし、 AWS CodeDeploy が使えるのであれば、AWS ブログで紹介されているベストプラクティスのように、このプロセスも AWS に任せることができます。
連続的な移行
実際のところ、例えば、Capistrano ベースから CodeDeploy ベースへ既存のデプロイフローを刷新することは不連続で劇的な変化になりがちです。この時に直面する課題の一つは、変化に対する関係者の不安を取り除くことであり、そのためのコストは膨らんでしまうこともあります。
そこで、導入に対する心理的な障壁を下げ、安全性を保ち続けるための連続的な変化を考えていきます。
今回は既存の Capistrano ベースのフローを残しながら、オートスケーリングに対応できる小さな修正を追加し、連続的な移行を行う例を示します。実際に一部の商用環境に導入した際の事例です。
前提
弊社では、運用中に変更がないミドルウェア等を設定した AMI をサービス毎に用意しています。
起動したインスタンスに Capistrano デプロイを行うことでサービスインできる状況です。
Capistrano 下準備
簡単のため、アプリケーション用に設定された Capistrano コードを cap コードと書くことにします。
通常と同じ cap を使って、起動したインスタンスが自分自身へデプロイできるようにしておきます。
まずは cap 設定ファイルへ
- 自分へのデプロイ指示
capコードを S3 へ保存
する処理を追記します。後者は起動したインスタンスが cap コードを取得できるようにするためです。これらは非破壊的な変更になります。
コードの変更部分は、リモートサーバを定義する部分です。Capistrano を AWS で使っている場合は、細部は違えど対象を取得するコードがあるのではないでしょうか。
|
1 2 3 4 5 6 7 8 9 |
# ... # 変数設定などなど… # ... # EC2 API を叩いて対象を取得するようなコード ec2_describe_instances_etc(params).each do |instance| server instance.private_ip_address, roles: [...], user: 'xxx', ssh_options: {...} end |
この部分に、deploy_local=1 があれば自分へデプロイするよう設定を追記します。Capfile に gem も追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# ... # 変数設定などなど… # ... if ENV['deploy_local'] server 'localhost', roles: [...] else set :release_deploy, true # EC2 API を叩いて対象を取得するようなコード ec2_describe_instances_etc(params).each do |instance| server instance.private_ip_address, roles: [...], user: 'xxx', ssh_options: {...} end end |
|
1 2 3 |
# In Capfile require 'capistrano-locally' |
ここでは localhost への SSH を簡略化する capistrano-locally という gem を使っていますが、各インスタンスへ SSH 鍵を配置してログインする通常の方法でも問題ありません。
次に、Capistrano コード自身と、最後にデプロイ成功したリビジョンを S3 に置いておくタスクを追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# In lib/capistrano/tasks/xxxx.rake namespace :deploy desc "Store current deployed revision" task store_revision: :set_current_revision do if fetch(:release_deploy) run_locally do info "Store #{fetch(:current_revision)} to s3://#{fetch(:bucket_name)}/metadata/#{fetch(:stage)}/release_version" options = fetch(:s3_client_options, { region: 'ap-northeast-1' }) Aws::S3::Client.new(options).put_object(bucket: fetch(:bucket_name), key: "metadata/#{fetch(:stage)}/release_version", body: StringIO.new(fetch(:current_revision)) ) end end end desc "Upload deploy tool to S3" task :upload_deploy_tool do tool_root = Pathname(__FILE__).dirname.parent.parent.parent run_locally do execute :aws, 's3', 'sync', '--exclude "vendor*", --exclude ".git*", --exclude "中略" --no-follow-symlinks --delete', tool_root, "s3://#{fetch(:bucket_name)}/autolaunch/deploy_tool" end end after :finished, :store_revision after :finished, :upload_deploy_tool end |
Capistrano 側はこれで十分です。これまでのデプロイも問題なく行えます。
スケーリングサイクルへの適用
さて、ここからはどのようにスケーリングサイクルを実現するかを考えます。 前述したように、ASG を使うのであればユーザが行うのは起動したインスタンスへのデプロイと終了処理だけです。
一つは cloud-init による起動時のデプロイが考えられますが、起動時の実行順番の制御や失敗時リトライをケアするのが面倒です。 せっかくの自動化ですので、インスタンスが状況を判断し自律的に動き、状態の収束を図ってくれると良さそうです。
インスタンスの自律化
インスタンスが状況判断を行えるようにします。 と言っても、エージェントプロセスを配置するほどでもないので、cron で済ませます。インスタンスが行ってほしい自律行動は下図です。
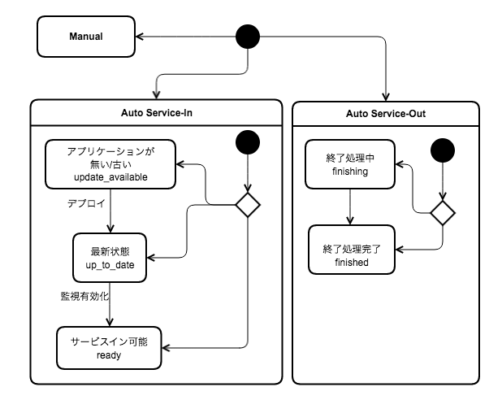
こちらはそれを行なうためのシェルスクリプト実装の一部です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
critial_section_begin # ... # EC2 のタグなどからインスタンスのメタデータを取得しておく # ... case $automode in # インスタンスが起動中か終了中かを判断 'in'|'once') if is_up_to_date $environment; then if [ "$monitoring" = 'on' ]; then state='ready' else state='up_to_date' fi else state='update_available' fi case $state in 'update_available') update $environment retry=true ;; 'up_to_date') enable_monitoring retry=true ;; 'ready') if [ "$auto" = "once" ]; then disable_automode fi service_in ;; esac ;; 'out') if is_finalized; then state='finished' else state='finishing' fi case $state in 'finishing') finalize $environment $role retry=true ;; 'finished') service_out ;; esac ;; *) log "$automode が特定の値でなければ何もしない" ;; esac # ... retry 処理、失敗が続いた場合のアラートなど critical_section_end |
こちらで使われている主なシェル関数の実装概要は次のようになります。
is_up_to_date: S3 にある指定リビジョンと、自身のdeploy_to/revisions.logを比較update: S3 にあるcapコードを取得、deploy_local=1でデプロイservice_in: ELB Health Check が通る状態にし、cron の間隔調整finalize: ログバッファの flush などを実行is_finalized: 残っているログバッファが無いかなどの確認service_out: ASG に Lifecycle Hook が完了したことを伝える (complete-lifecycle-action)
終了中かどうか?の判断には、後述する Lifecycle Hook を使います。Lifecycle Hook の状態が Terminating:Wait になっていたらサービスアウトを示す状態にセットします。
cron スクリプトができたらこれも S3 に入れておきます。
ASG へ組み込む
ASG へ組み込むには、Launch Configuration でユーザデータに先ほどの cron スクリプトを設定するだけです。
|
1 2 3 4 5 6 7 8 9 10 |
#!/bin/bash /usr/local/bin/aws s3 sync s3://yourbucketname/autolaunch/scripts /home/deployuser/scripts chown -R deployuser:deployuser /home/deployuser/scripts chmod +x -R /home/deployuser/scripts/*.sh { echo "* * * * * deployuser /home/deployuser/scripts/main.sh" } > /etc/cron.d/autolaunch |
ここでの cron は分毎にしていますが、先ほどのシェル関数中の遷移が落ち着いたタイミングで間隔を調整しています。
起動時は以上です。
終了処理は Lifecycle Hook を使います。Lifecycle Hook は 2016/06 現在、Web コンソールで設定できないので CLI で設定します。
|
1 2 3 4 5 6 |
$ aws autoscaling put-lifecycle-hook \ --lifecycle-hook-name AppFinalize \ --auto-scaling-group-name yourgroupname \ --lifecycle-transition autoscaling:EC2_INSTANCE_TERMINATING \ --notification-target-arn arn:aws:sns:ap-northeast-1:************:yournotifyname \ --role-arn arn:aws:iam::************:role/YourAsgNotificationRole |
Hook の名前は cron スクリプトの実装と合わせてください。これでスケールイン時、インスタンスが破棄されるまえに Terminating:Wait で止まるようになります。
フローのまとめ
ここまでで、本稿タイトルである「Capistrano ではじめるオートスケーリング」は実現できました。
一度、実際の動作をまとめます。
- 平常時
capの設置されているサーバからデプロイ- デプロイ成功時、
capコードとリビジョンを S3 に保存
- ASG 動作時
- スケールアウト
- ASG がインスタンス起動
- cloud-init (ユーザデータ) で cron スクリプト設置
- cron スクリプトが
capコードを使いインスタンスを最新に - 最新状態になったことで ELB Health Check を pass, サービス開始
- スケールイン
- ASG がインスタンス終了処理開始
- Lifecycle Hook がインスタンスを終了中に設定
- cron が終了中状態を検知、ログのフラッシュなど終了処理
- cron が ASG に処理が終わったことを通知、インスタンスの破棄
- スケールアウト
注意点
連続的な変化を主張して書いておりましたが、一つ既存のフローと互換性が無くなる点があります。 スケーリング時にそれぞれのインスタンスが個別にデプロイされるため、Capistrano の "#{deploy_to}/releases" の構成がグループで統一されなくなります。これにより、deploy:rollback が実質使えなくなることには注意しなければなりません。
次のステップ
Capistrano を使った既存の中央管理型デプロイを(ほぼ)有効にしたまま、AWS でオートスケーリングを実現できました。この先は運用形態に応じて進む方向を考えることになります。
分散型へ
非常にアプリケーションサーバの台数が多く、デプロイの時間が問題になる場合は分散型デプロイを考えるのが良さそうです。例えば、邪道ではありますが、CodeDeploy を使う設定を雑に書くとすると、cap ディレクトリに以下のようなファイルを設置すればよいでしょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
$ cat scripts/deploy.sh #!/bin/bash SCRIPT_ROOT=$(cd $(dirname $0) && pwd -P) TOOLS_ROOT=$(dirname $SCRIPT_ROOT) ( cd $TOOLS_ROOT && \ bundle install –path vendor/bundle && \ bundle exec cap production deploy deploy_local=1 2>&1 | tee /tmp/deploy.log ) $ cat appspec.yml version: 0.0 os: linux files: - source: / destination: /var/tmp/deploy/local permissions: - object: /var/tmp/deploy owner: deployuser group: deployuser hooks: AfterInstall: - location: scripts/cd_deploy.sh timeout: 300 runas: deployuser ApplicationStart: - location: scripts/atosyori.sh $ cat scripts/cd_deploy.sh #!/bin/bash /var/tmp/deploy/local/scripts/deploy.sh |
これは CodeDeploy を使ってアプリケーション本体ではなく cap を配り実行する設定です(が、弊社では商用環境でこのアプローチを使用している環境はありません)。あくまで分散型へうつる過渡期として、 Capistrano とのハイブリッドを用いることで、CodeDeploy や Surf / Consul ベースのデプロイツールといった、完全な分散型デプロイへ移るための心理的障壁を下げる効果はあるかと思います。
アプリケーションレポジトリの負荷を軽減する
Capistrano はデフォルトで、リモートサーバから GIT レポジトリへアクセスしアプリケーションを取得する動作をします。規模が膨れないうちは問題になりませんが、分散型を考えるような規模の大きいケースでは レポジトリサーバの負荷がネックになってきますし、スケーリングのタイミングでは SPOF となってしまいます。
この点において AWS CodeDeploy では、アプリケーションを ZIP アーカイブとし S3 から取得させることで、S3 の可用性とスケーラビリティを活用しています。
弊社では、Capistrano のプラグインとして
- Capistrano の deploy フローで配布したコードから ZIP を作成して S3 に上げる gem
- S3 から ZIP を取得し
deployで配布する gem
を作成し、S3 を経由したデプロイを行っています。
中央管理型を使い続ける
アプリケーションサーバの台数が多くなく、中央管理型のデプロイ時間が問題になっていないのであれば、無理に分散型を取り入れる必要性は低いかと思 います。
個人的には、小さなアプリケーショングループのフローにおいては中央管理型の方が手軽で適していると考えています。実際、最近の弊社サービスでは 小規模多数の構成へと変化してきており、多様な要件に対応するために個別の Capistrano レポジトリが多く生まれております。
AWS 以外で適用する
冒頭で書きましたように本稿では AWS を前提として設定を行っており、AWS を活用しているのは以下の点です。
- インスタンスを条件に応じて自動的に起動、終了 (ASG)
- 起動、終了時にユーザフックが挿入可能 (ASG, Lifecycle Hook)
- インスタンスからアクセス可能な高可用性のストレージ (S3)
- インスタンスに設定可能なメタデータ (EC2 タグ)
これらと同様の機能が使えるインフラであれば、シェルスクリプト部分の対応で流用は可能と考えます。
さいごに
先にも少し書きましたが、理想と現実との間に印象的な変化がある場合には、心理的な障壁が生まれやすく余計な力が働いてしまうことがあります。
関係者が思う不連続な箇所はどこなのか?に注目し、連続的な変化を重ねることで安全かつスムーズな移行を進めることができると考えます。