SQS、ElastiCache、Lambdaで作る高可用なアラート通知システム
インフラのいわほり(@egmc)です。
サーバ監視を構成するシステムは色々ありますが、今回はAWS環境上での監視に使われているアラート通知の仕組みについて紹介させて頂きます。
監視システムの構築そのものは2015年頃、AWSの本格的な利用に伴い、AWS環境を対象とした新規システム(AWSモニタリングシステム)の構築プロジェクトにて作成されたものですが、稼働から約2年が経過し、それなりに実績が積めてきたのではないかと思います。
通知システムにはYusuraという名前がついていて、機能的には過去のエントリで紹介されていたAWACSに近いものとなります。
主な機能としては
- 設定に基づいた通知先の振り分け
- アラートの集約(summarize)
- 同一アラートの抑制(suppress)
- インスタンスのタグ情報に基づいたignore処理(特定のタグがついているインスタンスを通知の対象とする)
を行います。
AWS環境におけるアラートのフロー
AWS環境上のアラート通知は下図のようなフローで行われます。
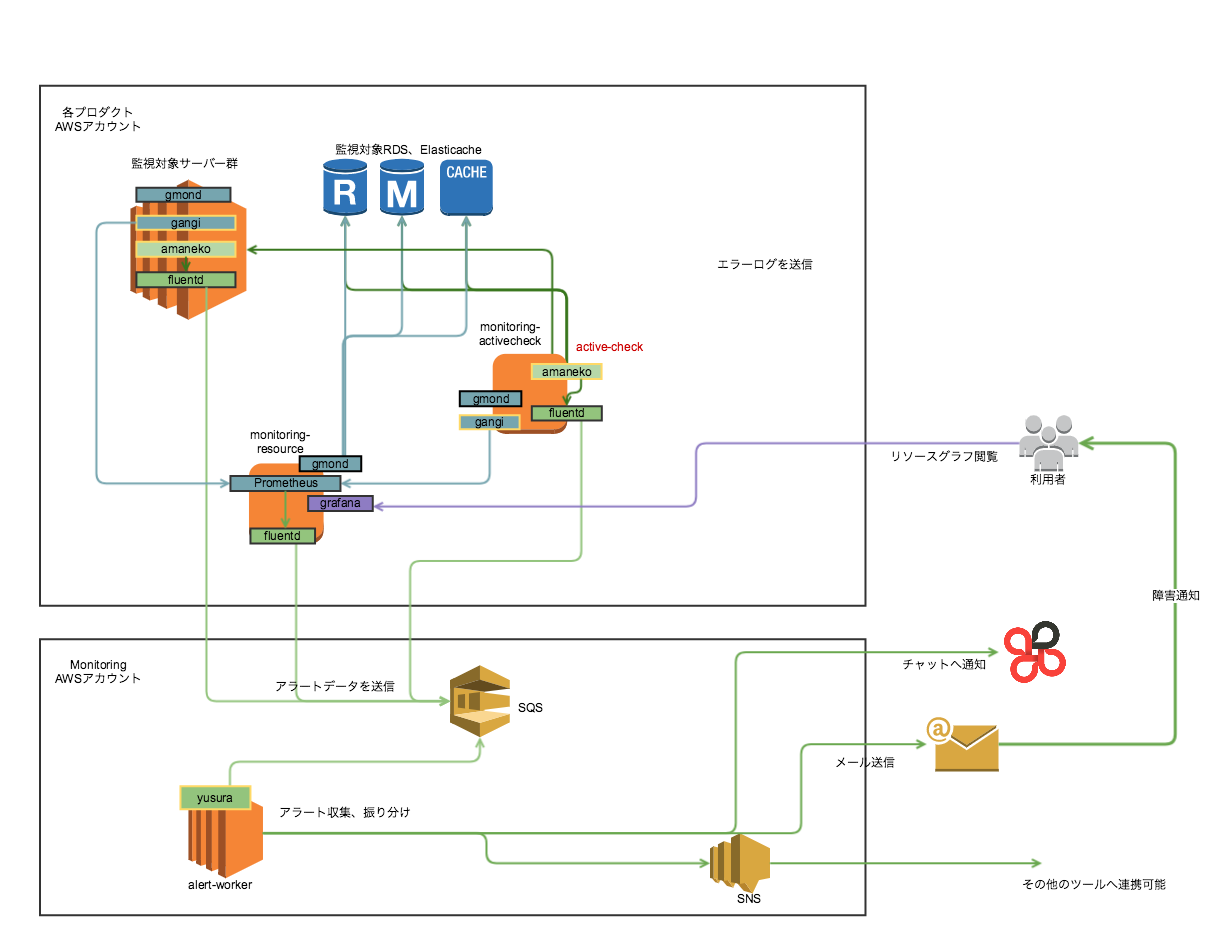
登場人物が多いですが、
- gmond
- gangi(内製)
は各インスタンスからメトリクスを収集し、Prometheusへ送る役割を担っており、アラートの通知元としては
- amaneko(内製) - プロセスの死活監視や簡易ログチェックなどを行うツール
- Prometheus - リソース監視。
- fluentd - ログ監視
がそれぞれAWSモニタリングシステムで定めた所定のjsonフォーマットに従いアラートを監視用アカウントのSQSキューに送り、Yusuraがそれらを処理し、メール、チャットワーク等に通知する構成となっています。
jsonフォーマットの定義は独自のものですが特に難しいものでもなく、アラートメッセージの他に
- プロダクト名
- インスタンスタイプ(ec2、rdsなど)
- インスタンスID
- ホスト名
- リージョン
- 時刻情報
- チェック元のタイプ(ログ系かリソースモニタリングを表すものか等)
- チェックソース(ログ名、チェックスクリクト名、アラート設定名など)
- 強制送信用のフラグ
などのメタデータを含めたものとなります。
Yusura自体はrubyで実装され、キュー処理を行うワーカーとして、shoryukenを採用しています。
グリーではプロダクト毎にAWSアカウントを分ける運用を行っているため、SQS側で各アカウントからのクロスアカウントアクセスを許可しています。
また、監視状態を管理するタグ情報を収拾するため、Monitoringアカウントから監視対象アカウントに予め設置した専用のIAM Roleに対してAssumeRoleによるクロスアカウントアクセスを行っています。
AWSモニタリングシステムにおけるYusuraの要件
役割としては「アラートの流量を抑えつつ低遅延で適切に振り分ける」といったことになるかと思います。 その他に求められた要件として
- なるべくYusura自体の運用はあまりしないで済むよう、メンテナンスフリーな構成とする
- そのために適切なマネージドサービスがあれば活用する
- 規模の拡大に対応出来るようスケールアウト可能な構成とする
が挙げられていました。
アラートのコントロール
大量のアラートをそのまま流してしまうと通知先サービスのAPI制限を越えてしまったり、そもそも通知として人間がチェック出来るものではなくなってしまうため、同種のアラートをまとめたり間引く処理をYusuraで行っています。
- 同一アラートで異なるインスタンスからのアラートをまとめる(summarize)
- 類似アラートのサマライジング(アラートメッセージの内容に応じたsummarize、ログ系のみ使用)
- 同一アラートかつ同一インスタンスの間引き(suppress)
基本的にはまず新規のアラートは必ず発報対象となり、その後同種のアラートが来たら一定時間溜め込み、まとめて通知をするような挙動となります。
アプリケーションログやphpログなどのパターンマッチに引っかかったアラートは、同一のエラー内容であってもタイムスタンプなどがログレコードに含まれることによって差異が出てしまうため、先に発報されたアラートとの類似度を見てしきい値を越えていたら(現在は70%程度)まとめるようにしています。
仕組みとしては単純ですが、設定で細かくメンテせずとも未知のアラートに対してそれなりにうまく機能していると思います。
Yusuraの構成
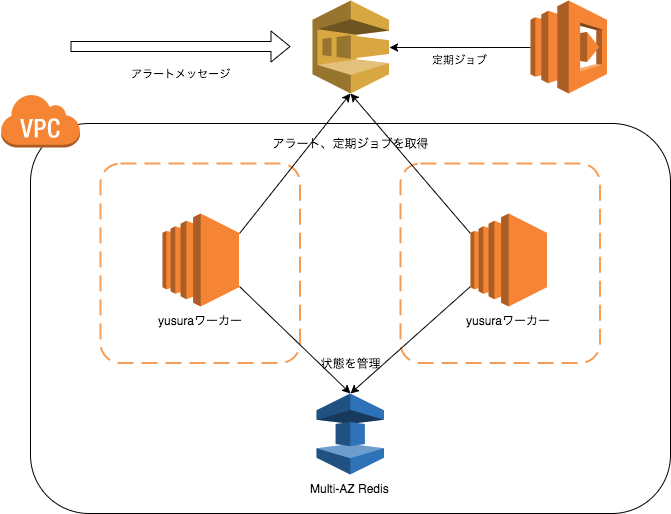
アラートを扱うという性質上、可用性を担保するためYusuraは可能な限り冗長構成を取っています。
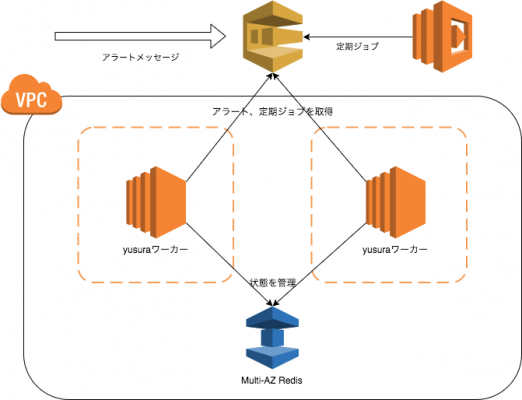
ワーカーを動かすEC2インスタンスはAZを分け、それぞれにNATを配置して通信、RedisはMult-AZでそれぞれ冗長化しています。
リリース当初はcronで定期ジョブを実行していたのですが、Lambdaファンクションの定期実行がサポートされ、Lambdaから定期的にSQSへ実行すべきジョブをjsonでエンキューし、いずれかのワーカーが拾って処理を行う、という形式にすることで特定のバッチサーバなどに依存せずに実行しています。
SQSのキューが唯一SPOFに見えますが、こちらはAWSのマネージドサービスであり、基本的にAWS側で冗長化されているであろうということで任せています(SQSエンドポイントのIPは定期的に変化しており、リクエスト先の分散を行っていることが窺えます)。
少なくとも約2年間の稼働においてSQS側が起因となっての問題は特に起きてはいないです。
なお、Yusura自体の障害は他に稼働しているインスタンスがそこから通知されるようになっています。
仮に全台がサービス停止してしまっているような場合は、各インスタンスからcronで送信しているプロセスチェックに異常があることがCloudWatch側で検知され、別経路にてアラートが発報されます。
実装面の話
Yusuraのワーカーは複数のサーバに分散しているため、各ワーカー内では極力状態を持たずRedisに寄せるようにしています。
例えばサマライズされたアラートの発報ジョブが各ワーカーで同時に処理された場合や、サマライズ対象のアラートデータが既に存在しているかどうか、などの判定はatomicな処理が必要となるため、そういった部分はRedisのAPIレベルで保証するようにしています。
また、基本的にYusuraで扱うデータは定期的に収集されるインスタンスのタグ情報や各アラートの一時的な状態管理などなので、扱うデータにはすべてexpireを設定するようにしています。
オートスケーリング
アラート通知は遅延してしまうと検知が遅れ、アラートとしての価値がなくなってしまうため、可能な限り速やかにキューを溜めずに処理を行う必要があります。
AWS上の監視対象サーバはそれなりに多いため、アプリケーションの不具合や、AWS上での大規模な障害が発生すると数万単位での大量のアラートが発生し、ワーカーの処理が追いつかないとキューに溜まってしまい、結果遅延が発生してしまうことになります。
基本的にワーカーの増設で処理能力を上げて対応するのですが、当初はCloudWatchアラームで検知し、人力でワーカーの追加などを行うことで対応していました。
現在はオートスケーリングの仕組みを導入し、キューが溜まりはじめたことをトリガーとして動的に処理が追いつくまでスケールさせることにより、人力での対応を行わずに捌けるようになりました。
まとめ
AWSのマネージドサービスを活用しつつ、アラートの通知システムという高可用性が求められるシステムを構築し、運用してきました。
当然マネージドサービスも落ちますし、万能ではありませんが、落ちた場合の復旧が早く自動化されている、アーキテクチャ的に特定のインスタンスに依存していない、などの特性を活かしそれなりに可用性の高いサービスを提供することが容易に実現できるようになってきているのではないかと思います。
AWSのサービスは日々進歩しているのでベストプラクティスも変わっていきますが、こちらも一つの事例として参考になりましたら幸いです。