Prometheusによる数百台規模のモニタリングで直面した問題について
インフラの反田 (@mtanda) です。
GREEでは、多くのサービスをAWS環境で運用しており、それらサービスのモニタリングシステムとしてPrometheusを利用しています。
Prometheusを導入してから約2年がたち、1台のPrometheusで数百台規模のインスタンスをモニタリングするなかで、さまざまな問題に直面しました。
それら問題の原因を分析し、設定や利用の仕方を改善することで、ある程度安定して運用できるようになりました。
これらの知見が少しでもお役に立てばと思い、ここで共有いたします。
なお、対象とするPrometheusのバージョンは1.xです。Prometheus 2.0では、これら問題のほぼ全てに対して改善されています。そのため、2.0でどういった点が改善されているかを知るためにも有用だと思います。
Prometheusのストレージ実装の基礎知識
Prometheusを運用するにあたって、事前にストレージの実装を理解しておくことで、問題の原因分析がしやすくなると思います。
コマンドラインフラグの"-storage.local.path"で指定されたディレクトリには、以下のようなファイルが保存されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
% find data -type f data/6e/ba9261f76a4de1.db data/6f/74c9f9d4d9c41b.db data/archived_fingerprint_to_metric/000001.log data/archived_fingerprint_to_metric/CURRENT data/archived_fingerprint_to_metric/LOCK data/archived_fingerprint_to_metric/LOG data/archived_fingerprint_to_metric/MANIFEST-000000 data/archived_fingerprint_to_timerange/000001.log data/archived_fingerprint_to_timerange/CURRENT data/archived_fingerprint_to_timerange/LOCK data/archived_fingerprint_to_timerange/LOG data/archived_fingerprint_to_timerange/MANIFEST-000000 data/heads.db data/labelname_to_labelvalues/000001.log data/labelname_to_labelvalues/CURRENT data/labelname_to_labelvalues/LOCK data/labelname_to_labelvalues/LOG data/labelname_to_labelvalues/MANIFEST-000000 data/labelpair_to_fingerprints/000001.log data/labelpair_to_fingerprints/CURRENT data/labelpair_to_fingerprints/LOCK data/labelpair_to_fingerprints/LOG data/labelpair_to_fingerprints/MANIFEST-000000 data/mappings.db data/VERSION |
"data/6e/ba9261f76a4de1.db"のような命名規則のファイルが、Prometheusの1 time seriesに対応しています。
各time seriesにつけられたラベルの組み合わせから一意なfingerprintが生成され、fingerprintに対応したファイルパスにtime seriesが記録されます。
time seriesの中は固定長1024バイトのchunkという単位で細かく分けられていて、chunkの単位で読み書きされます。
Prometheusのメモリ上に展開されたchunkは、chunkが含むデータの期間といった情報と共にchunkDescという構造体で管理されています。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/chunk/chunk.go#L79-L118
Prometheusのメトリクス
Prometheus自体が運用に役立つメトリクスを出力しているので、これらをモニタリングすることで、問題の早期検知や原因調査ができます。
time series、chunk、chukDescに対するoperationの発生回数は、突発的な負荷上昇といった問題の原因調査に役立ちます。
- prometheus_local_storage_series_ops_total
- prometheus_local_storage_chunk_ops_total
- prometheus_local_storage_chunkdesc_ops_total
各インスタンスから収集されたメトリクスをディスクへ書き出す処理に遅延がないかは、以下のメトリクスが役立ちます。
- prometheus_local_storage_persistence_urgency_score
- prometheus_local_storage_rushed_mode
urgency scoreが0.8を超えると、rushed modeになり、メモリ上にあるchunkを強制的に書き出します。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/storage.go#L1865
1を超えると、メトリクスの収集自体がされなくなります。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/storage.go#L971
Prometheusが開くコネクション数にも注意が必要です。
process_open_fdsがprocess_max_fdsを超えないように、OS側の設定を調整します。
- process_max_fds
- process_open_fds
また、Prometheusの内部処理で発生したエラー回数のメトリクスを監視しておくと、内部で起こっている問題を早期に検知できます。
ストレージに起因する問題、アラート通知やアラートルール評価の失敗など、いずれも監視が正常に動いているか確認するために重要なものばかりです。
alertmanagerを利用している場合は、alertmanagerのメトリクスも収集して監視しておくとよいと思われます。
- prometheus_local_storage_inconsistencies_total
- prometheus_local_storage_non_existent_series_matches_total
- prometheus_local_storage_persist_errors_total
- prometheus_notifications_dropped_total
- prometheus_notifications_errors_total
- prometheus_rule_evaluation_failures_total
問題の事例集
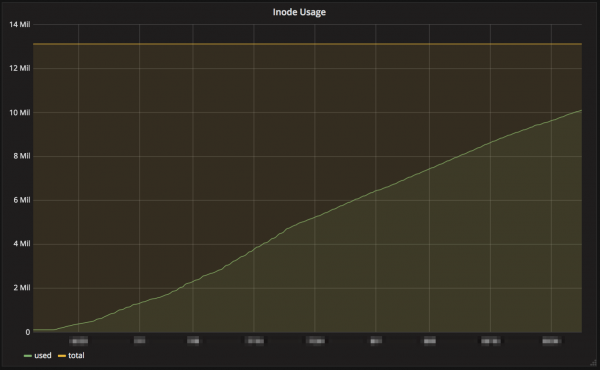
事例1 inodesが枯渇(しそうになる)
問題: inodesの不足
影響: inodes数の監視により枯渇前に検知できたため、影響はなかった
原因: Auto Scalingでの頻繁なインスタンス起動によるtime series数の急増
対応: 不足するinodesを補うため、EBSの容量を拡張
日毎に数十台のインスタンスを起動していることで、time series数 (= inodes数)が10万単位で増えていました。
前もって必要数を見積もることも難しいので、監視にひっかかった場合は、都度EBSを拡張して対応しています。
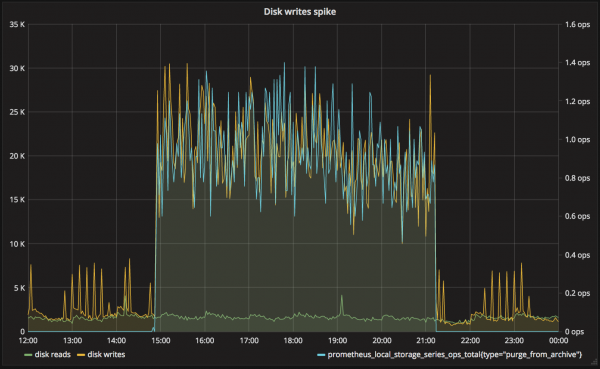
事例2 突発的に発生する大量のディスク書き込み
問題: 運用開始から数ヶ月後に発生する大量のディスク書き込み
影響: メトリクス書き出しの遅れ
原因: retention期間が切れたchunkの削除
対応: storage.local.series-file-shrink-ratioの調整
retention期間が切れたchunkの削除処理では、切れた部分だけを読み飛ばして、それ以降の部分を一旦別ファイルに書き出し後、元のファイルに上書きします。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/persistence.go#L876-L1067
そのため、1 time seriesのファイルサイズが大きくなると、それだけ書き出すデータ量が増える傾向にあります。
削除処理は、頻度が多くなりすぎないように、都度sleepをいれながら実行されていますが、sleep時間は最長でも10秒とハードコーディングされているため、負荷が高くなりすぎてしまう場合があります。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/storage.go#L44
とくに以下のような環境で問題になりやすいと思われます。
- storage.local.retentionを1ヶ月以上など長く設定している
- オンプレミス環境などで、1 time seriesが長期間にわたって記録される傾向にある
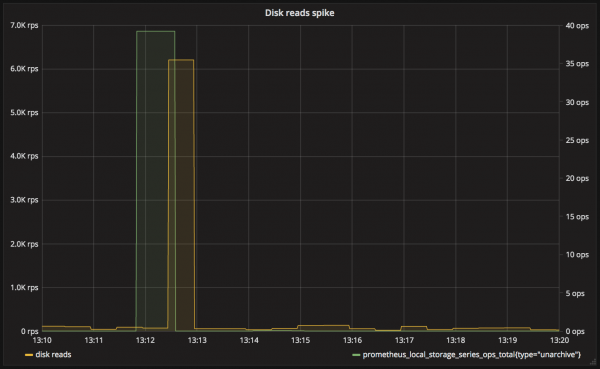
事例3 クエリ実行時に発生する大量のディスク読み込み
問題: クエリ対象の期間を1日以上などとすると、大量の読み込みが発生する
影響: クエリのレスポンスタイム悪化、メモリ不足によるOOM
原因: 1ヶ月以上の長さを持つtime seriesのunarchive
対応: 別のPrometheusに精度をおとしてメトリクスを保存し、数日以上過去のメトリクスはそちらを参照させる
query.staleness-delta (デフォルト5分)を超えて、新規書き込みがないtime seriesはarchiveの対象になります。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/storage.go#L1640-L1657
一度archiveされたtime seriesは、unarchive時にtime series全体を読み出して、chunkDescを再構築する必要があります。
https://github.com/prometheus/prometheus/blob/v1.8.0/storage/local/storage.go#L1027-L1070
そのため、毎日何台もインスタンスをterminateしているような状況で、1週間など長い期間を対象にGrafanaのダッシュボードを表示すると、unarchiveが発生して、負荷が跳ね上がります。
メモリに展開する際に、一時的にメモリ使用量も上がるので、場合によってはメモリ不足になりOOMが発生します。
社内では、こういった問題への対応として、15秒精度で記録しているメトリクス以外に、別のPrometheusに1時間精度で同じメトリクスを記録しています。
Grafanaで表示する期間に応じて、datasource plugin側でどちらのPrometheusに対してクエリを発行するか切り替える仕組みを作り、利用者側が意識しなくても高負荷にならないようにしています。
事例4 インスタンス一括terminateにより、コネクション溢れ発生
問題: 数十台のインスタンスをまとめてterminateした際に、"Series quarantined”エラーが発生
影響: time seriesへの新規書き込み時に失敗し、書き込み済みのtime seriesごと消える
原因: terminate済みのインスタンスがメトリクスのpull対象として登録されており、タイムアウト待ちのコネクションが大量に発生、新規コネクションが開けなくなる
対応: terminate済みを対象外とするよう、relabel_configsに設定を追加
ec2_sdを利用している場合に問題になります。ec2_sdが内部で呼び出しているec2:DescribeInstances APIの結果には、しばらくの間terminate済みのインスタンスが"terminated"という状態で残ります。これらインスタンスに対してpullをしようとして、コネクションが滞留してしまいました。scrape_timeoutを短くすれば改善する可能性もあったと思いますが、とくに不都合がなかったため、pull対象から外すようにしました。
設定例
|
1 2 3 4 5 6 7 |
ec2_sd_configs: - region: ap-northeast-1 port: 19100 relabel_configs: - source_labels: [__meta_ec2_instance_state] regex: ^running$ action: keep |
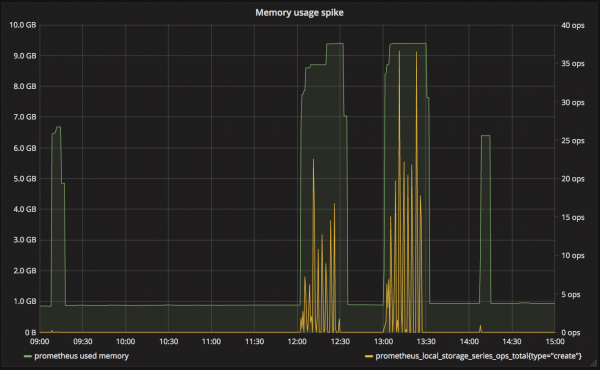
事例5 Auto Scalingによるインスタンス起動後に発生するメモリ使用量のスパイク
問題: 新規time series生成時にメモリ使用量がスパイクする
影響: メモリ不足によるOOM
原因: (おそらく)LevelDBのインデックスサイズの肥大化
対応: Prometheusを起動しているインスタンスのスケールアップ
はっきりとした原因はわかってはいませんが、Auto Scalingを導入しているサービスで、インスタンスが起動した直後に、Prometheusのメモリ使用量がスパイクする問題が発生しました。
日増しにスパイク時の変動幅が大きくなり、メモリ不足によりOOMが発生してしまうこともありました。
プロファイラで解析した結果、Prometheusが利用しているLevelDBのライブラリで、新規エントリ登録時に大量のメモリを確保しているということがわかりました。
設定で対処できる問題ではないと判断し、スケールアップで対応しています。
まとめ
Prometheus導入初期のころは、それほど台数規模が多くないサービスへの試験導入であったため、負荷が問題になることはありませんでした。
しかし、台数規模が多くなり、また保存しているメトリクスが長期間になるにしたがって、負荷が上がり、さまざまな問題に直面しました。
AWS環境でのモニタリングシステム導入時に重視したポイントの一つとして、モニタリングシステム自体の運用がしやすく安定していることがありました。
実際に振り返ってみると、さまざまな問題があったものの、Prometheus自体のメトリクスが充実していること、また内部の処理もソースコードを読めば比較的理解しやすいことは、運用する上でとても助けられました。
運用のつらい側面ばかり取り上げてしまいましたが、Prometheus1台で数百台規模のモニタリングができること、またPromQLにより柔軟な集計ができることは、自社で運用する価値があるほど素晴らしい点だと思います。
こちらで共有した知見が少しでもお役に立てれば幸いです。
参考資料
https://schd.ws/hosted_files/cloudnativeeu2017/ce/Slides.pdf
https://promcon.io/2016-berlin/talks/the-prometheus-time-series-database/
https://promcon.io/2017-munich/talks/monitoring-cloudflares-planet-scale-edge-network-with-prometheus/