10年もののメトリクス収集機構をリプレースした話
インフラのいわほり(@egmc)です。
久々のエントリとなりますが、今回はインフラのMonitoring Unitとして長期的に取り組んでいた監視システムのリプレースについてのお話になります。
背景含めて長いエントリとなりますが、監視システムの長期的な運用の考え方、リプレースにあたって考慮した点などなにがしか参考になる点があれば幸いです。
何を移行したか?
グリーのインフラ環境では冒頭で述べたMonitoring Unitというインフラ横断で監視システムを提供するチームが商用環境向けの共通システムの提供/運用を行っています。
監視システムにおけるリソースモニタリングシステムの構成として、オンプレ環境ではGanglia、AWS環境ではPrometheus/Grafanaスタックを採用、運用してきました。
規模感としてはざっくりと監視対象ノードがオンプレサーバが約1500台、AWS側は台数変動がありますがざっくりと数千台程度となります。
オンプレは複数台で構成されたGanglia1クラスタで全台を、AWS側はアカウントごとに監視インスタンスをたてる構成でリソースモニタリングを行っています。
両環境はそれぞれ独立しており技術スタックも異なるのですが、グリーのAWS環境での監視スタックとして2015年にPrometheusを採用した際、オンプレ側で開発した内製のメトリクス収集のための資産であるGangliaのプラグイン(python module)をAWS側でも利用するため、Gangliaのエージェントであるgmondから収集したメトリクスをexporter形式に変換、開示するエージェント(gangi)を開発しました。
これによりオンプレとAWSで違うシステムを採用しつつ、メトリクスとしては共通のものをベースとして5年以上運用を続けてきました。Gangliaを使い始めたのが2010年頃なので使用しているpython moduleのうち初期からあるものは10年ものということになります。
今回はこのメトリクス収集のコア部分であったGangliaプラグインの仕組みを完全にリプレースし、AWS/オンプレともに標準的なprometheus exporterを利用した仕組みへと移行しました。
また、オンプレ側の環境においてGanglia自体のスタックそのものをリプレースし、メトリクスの収集資産を活かしつつ長期的な運用コストを下げるためSaaSのGrafana Cloudを利用することとしました。
AWS環境移行概要
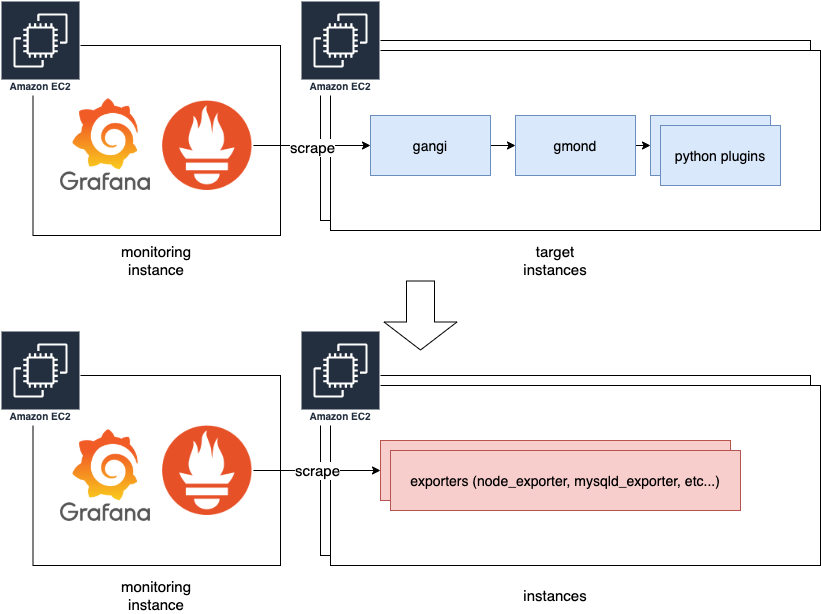
オンプレ環境移行概要
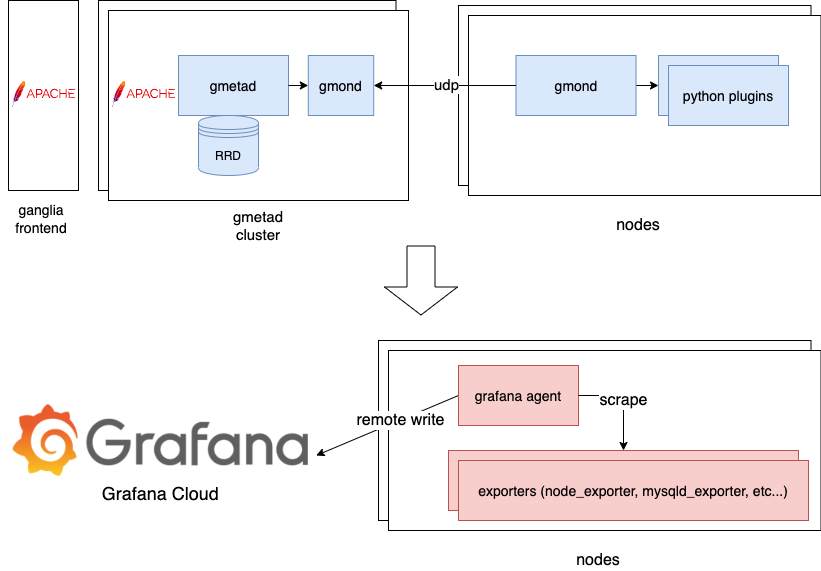
※ 青->赤がリプレースした部分、オンプレは全リソースモニタリングスタックをリプレース
本記事ではリプレースの背景、監視システムの長期的な運用についての考え方、監視システムというクリティカルな機構の移行にあたって考慮した点、取り組んだ点などについて共有していきたいと思います。
なぜ移行したか?
背景としては複数の理由が挙げられますが、もっとも大きなものとしてはpython2のEOLです。
python2.7は2020/1/1にEOLを迎えました。
Gangliaのプラグイン機構はpython2系を利用しており、かつグリーで採用しているUbuntuのLTSにおいてもそもそもpython2パッケージが2020/4リリースの20.04 LTS (Focal Fossa)においてpython2の削除をいかに進めるかといった議論がなされていました。
https://lists.ubuntu.com/archives/ubuntu-devel/2020-February/040918.html
結果的にFocalにもganglia-monitorパッケージ、および ganglia-monitor-pythonパッケージは提供されることになりましたが依然python2パッケージに依存しており、upstreamの更新が止まった処理系に依存してしまうことには変わりはないためFocalのプロダクション利用を開始する前にリプレースを行う方針ですすめることとしました。
また、上記はもっとも大きくEOLに対する対応というネガティブな理由がベースになっていますが、ポジティブな理由もあります。
グリーでAWS環境でPrometheusを採用したのは2015年でしたが、その後Prometheus/Grafanaスタックは業界的なスタンダードといえる状態となり、当時と比べて圧倒的にexporterも充実しました。
リプレースを開始した2020年時点で内製のGangliaプラグインで賄ってきたものと同等のメトリクスをOSSベースのExporterでもほぼ取得することができましたし、不足があっても対応出来るであろうという目算がありました。
また、メトリクスをOSSベースのExporterに寄せることで、今まで独自メトリクスであったが故に使うことができなかったコミュニティのダッシュボードなども活用することができます。
こうした背景を踏まえ、既存の10年を担ったシステムから、次の10年を担うシステムとして年単位でのリプレースプロジェクトをすすめる事となりました。
移行の流れ
どちらの環境もおおまかには準備、並行運用、切り替え、撤去という流れです。
可能な限り並行運用期間中に問題を潰せるようにしつつ、アラートルールの切り替えなどあるポイントで切り替える必要があるものについては切り戻しが可能なサイズに分割して段階的に実施するという進め方をしました。
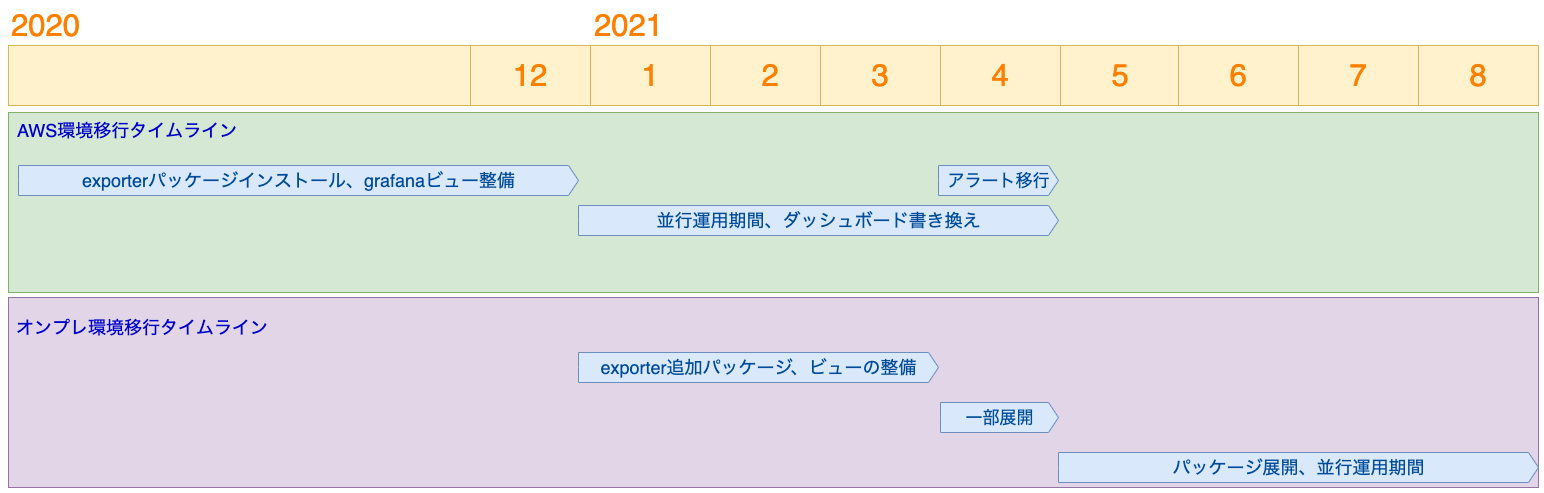
AWS環境の移行
AWS環境の移行はおおむね以下のステップで進めました
- exporterのパッケージ整備
- exporter版のGrafanaビューの整備
- 全環境に対するexporterのパッケージインストール
- 並行運用(3ヶ月程度)
- 旧環境からのリンク切り替え
- アラートルールの切り替え(一ヶ月)
- 旧環境の停止
いくつかポイントとなった点についてピックアップしていきたいと思います
exporterのパッケージ整備
node_exporter、mysqld_exporter等のバイナリをデーモン管理するスクリプトも含めてパッケージングし、配布するというのが基本的な流れです。
exporterはOSSのものを基本としつつ、旧システム側で取得しているメトリクス相当で不足のあるものについては追加で取得をするようにしました(mysqld_exporterなど)。
また、新規にexporterを開発するほどではないがOSSのexporterでは取得できていないメトリクスについては、node_exporterのtextfile collectorやscript-exporter用の簡易スクリプトを追加する形で対応しています。
デーモン管理は先行して導入していたnode_exporeterではsupervisorを使用していましたが、移行ターゲットとなる環境はシンプルにUbuntu Xenial以降を前提としてsystemdに管理させるという方針に決定し、パッケージ化をしました。
exporterのパッケージが各環境に配られた段階でスクレイプを開始し、既存のもの、exporter版の両方のメトリクスを収集することで並行運用を可能にしました。
並行運用期間中はダブルライトとなるため、後述のTimeSeries数を抑える対応を行っても環境によっては保存領域の拡張が必要となります。
EBSの拡張はSaaSのカスタムメトリクスの利用などに比べれば相対的に費用増は少なく済みますが必要となる環境において個別に対応を相談、実施しました。
Grafana上のViewの整備
移行においてこのパートが一番負荷が高かったのではないかと思います。
メトリクス名は変更となり、グラフを描画するためのPrometheusに対するクエリも書き換える必要があるため、ビューは全面的に再作成を行う必要がありました。
また、旧システムでは基本的にすべてのメトリクスはGaugeとして保持されていたのですが、Prometheusの世界においてはCounterのまま保持し、クエリのタイミングでGaugeへと変換するといったスタイルが推奨されているため、業界標準となるべく合わせるという方針でクエリの書き換えをすることとしました。
ビューはインフラのMonitoring Unitで作成しているベースとなるもの、インフラ内の各チームが作成しているもの、プロダクトチームで独自に作成しているものがあるため、それぞれ以下のように進めました。
- Monitoring Unit管理ダッシュボードのexporter版を作成し先行して並行運用
- 上記のクエリ書き換え方式をベースにガイドラインを作成し、並行運用期間中にそれ以外のチームにクエリの書き換え依頼を作成
その他、新旧のクエリの結果差分を表示するダッシュボードも作成し、exporter版のダッシュボードで値の異常があった場合に比較することで問題の切り分けを行えるよう整備しました。
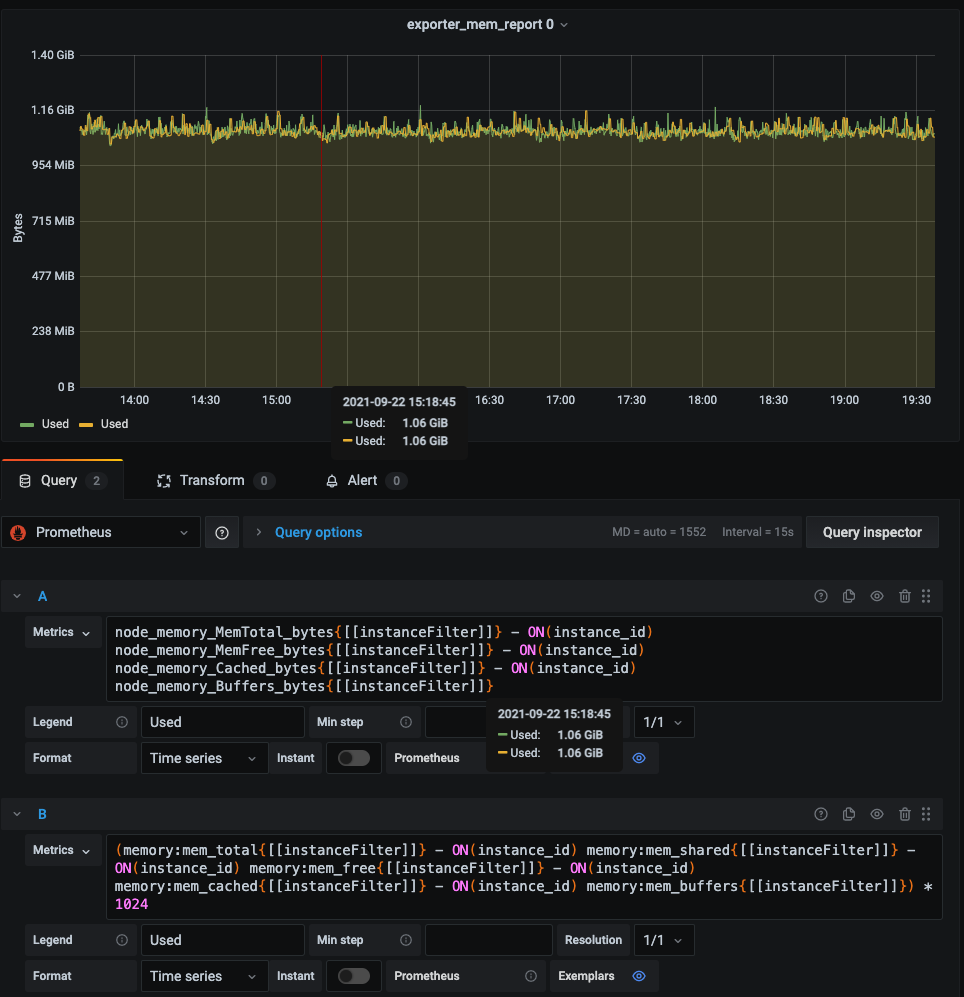
※ このような形の新旧のクエリでの比較用グラフを作成して新旧を比較
アラートルールの切り替え
メトリクス名、クエリの式が変更となるので、当然アラートルールも切り替えていく必要があります。
基本的には対応するメトリクスをベースとした新規のルールを作成し切り替える形となりますが、アラートルールの切り替えに失敗した場合大きな影響が想定されるため、以下のように進めました。
- 切り替え先のアラートルールを「Exporter」prefixを付与して追加し、特定のチャンネルへのチャット通知のみにルーティング(dry-run)
- 実際に発報されたアラートの件数と比較し、切り替え前と同じ水準でアラーティングされているかを事前に検証
- 一ヶ月の間に週次での段階的な切り替え
dry-run方式は実際に有効に機能し、未然にアラートルールの見直しをすることができました。
具体的にはグリーの負荷に対する標準メトリクスであるsysloadの算出方法をPrometheusのレコーディングルールを用いた方法に変更したのですが、切り替え後のアラートルールではインスタンス起動直後の値が既存のものより高く出ることによる誤検知が増えることがわかったため、アラートルールに起動経過時間を考慮したルールを追加する対応を行いました。
アラートルールの段階的な切り替えは切り戻しを考慮し、毎週月曜日に新ルールを展開する方式としました。
こちらは幸い切り戻しを行うことなく、無事新ルールへの切り替えを行うことができました。
オンプレ環境の移行
オンプレ環境の移行はAWS側の移行によって得られる成果物を再利用するため、概ね2、3ヶ月後に進むようなスケジュールで進行しました。
- grafana-agent、各種exporterのパッケージ整備
- サーバーロールごとに数台ずつ展開
- メトリクス数の調整
- 全環境に対するパッケージインストール
- Grafanaビューの整備
- 旧環境からのリンク切り替え
- 旧環境の停止
パッケージはAWS側と共通のものを使用し、オンプレ固有で追加で必要になるものについては同様に新規exporter、textfile collector、script-exporterのスクリプト追加にて対応しました。
grafana-agent、exporterのパッケージインストール
オンプレ環境はGrafana Cloudへのメトリクスを送信するため、各サーバにGrafana Agentエージェントをインストールしてリモートライトを行います。
Grafana Agentは主要なexporterをビルトインで持っているのでそれを使うこともできますが、exporter自体に手をいれているものもあるという点と、Grafana Agentのバージョンと各exporterのバージョンは独立して扱いたいという点によりこちらは使用せず、単純に収集したホストのメトリクスをリモートライトするためのものとして利用する方針としました。
メトリクス数の調整
オンプレ環境では運用コストを下げるためGrafana Cloudを採用しましたが、SaaS利用の宿命としてTimeSeries数がダイレクトに費用に反映されるため、ホスト一台あたり平均何TimeSeries以内におさえるか、という点を運用上必要なメトリクスの数と費用を事前に検討し、node_exporterのTimeSeries数は平均約500、それ以外はサーバロールごとにバラつきがありますが約300程度をターゲットとし、不要なメトリクスはフィルターする対応を行いました。
node_exporterはCPUのコア数やブロックデバイス、ネットワークインターフェースの数などでも変動しますが例えばオンプレのテスト環境においてはデフォルトの設定でホストあたり2000を超えるTimeSeriesを取得していました。
基本的には既存のダッシュボードで利用しているメトリクス(または代替となるもの)を残すという方針で、以下のようなメトリクスをPrometheusのrelabel configでdropし削っていきました。
- 全exporterにおけるexporter自身のメトリクスをフィルター(go_など)
- node_exporeterにおけるnode_filesystem_の使用していないマウントポイントのもの、node_interrupts_など
- mysql_global_status_commands_totalの不要なコマンド群、global_status、global_variables系など
dropがきちんと反映されているかはjobごとのscrape_samples_post_metric_relabelingを利用し、予め対象を絞り込んだホストで概算のサンプル数をダッシュボードに表示&デフォルトのbilling dashboardでactive seriesが想定と合っているか確認しました。

その他発生した課題と対応など
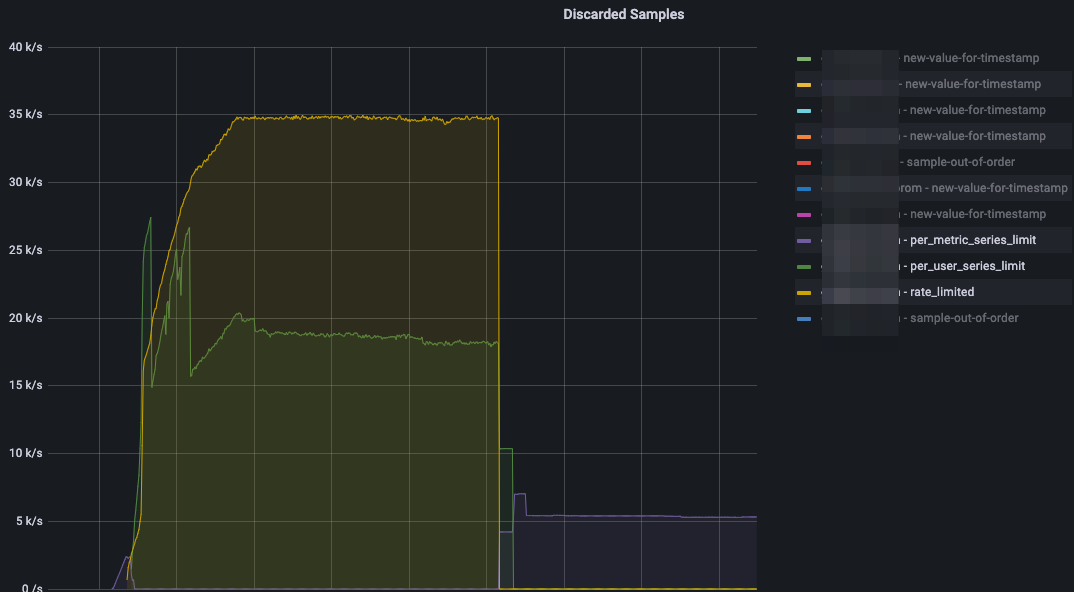
Grafana Cloudのrate limit対応
Grafana Cloudはインスタンスごとにrate limitが存在し、150kのPer-user series limit(UserとなってますがHosted Prometheusインスタンスごとです)とPer-metric series limitがあります。
limitを超過するとremote writeの際にエラーとなり、超過分のメトリクスは保存されなくなります。
有効な対応としては「サポート連絡でlimitを上げてもらう」になりますが、送信時のエラーログ以外に現在のlimitを知る方法がなく気づきづらいです。
ドキュメントにもありますが提供されるbilling dashboardでDiscarded Samplesメトリクスをみることにより検知することができますので、こちらにアラートルールを設定しておくと良いでしょう。
レガシー環境の対応
AWSの方になりますが、Exporterの導入にあたり古い環境はOSバージョンアップまたは移行、Chef Cookbookの更新とイメージの再作成を伴う必要があり、これらに期間内に対応できないプロダクト環境についてはインフラ運用に支障をきたしてしまうため、新規ルールに追随を止め、旧ダッシュボードを参照するなどの例外対応を行うためのフラグを設け制御する対応を行いました。
これらの環境は移行完了次第、フラグを戻すことにより再び最新の設定に追随できるようにすることができます。
追加の手間もかかりますし例外を設ける判断は難しいところではありますが、結果的に猶予を設けることで移行を無理なく進めることができたので良かったのではないかとおもいます。
まとめと今後について
時間と手間はかかりましたが、結果的に大きな事故もなく10年間利用したメトリクス収集の仕組みをリプレースし、次の10年を見据えた仕組みに移行することができました。
リプレース後のシステムは引き続きsysloadに代表されるような独自のメトリクスもあるものの、基本的にはOSSのexporterをベースとしているものとなったため、今まで使いづらかったコミュニティベースのダッシュボードの取り込みや、逆に我々の利用しているリソースを公開していくこともやりやすくなりました。
10年前には取れるメトリクスが世の中的にまだ少なく、結果的に多くの収集のためのプラグインが内製で実装されましたが、2021年現在はPrometheusを中心としてコミュニティベースで多くのメトリクスを収集するExporterが作成され、取得できる大量のメトリクスの中から自分たちの技術的な意思決定に必要なものを適切に選択していく、必要に応じてフィルターしていくことが求められる時代になったと感じています。
今回のリプレースにより長期運用に向けたベースの仕組みは整いましたが、障害対応などの問題の特定、コストの最適化などをはじめより効果的に価値を提供していくことが出来るよう、ダッシュボードの最適化など引き続き取り組んでいきたいとおもいます。