サービスを支えるプライベートクラウド基盤 OpenStack の舞台裏
こんにちは!インフラストラクチャ本部の松橋です。このエントリは GREE Advent Calendar 2014 3日目の記事です。本日より 2日間 OpenStack の記事がつづきます。
私からは、グリーのサービスを支えるプライベートクラウド基盤として OpenStack を導入し、運用、改善を続けてきた日々の奮闘についてご紹介させていただきます。振り返ればちょうど 2年前のクリスマスシーズンに本腰を入れて仕掛かり、今では運用も安定してきたので良い節目でもあります。読者のみなさまの一助となる知見が少しでも提供できれば幸いです。
はじめに
パブリッククラウドの台頭により、オンプレミスを基盤にサービスを展開してきたグリーにおいてもクラウドが有用な選択肢となるなかで、運用ノウハウが蓄積されたオンプレミスの資産を活用してインフラストラクチャを最適化するニーズもまた高まりました。
サーバー仮想化は、プール化した物理サーバー群から仮想サーバー(以下、VM)を払い出すことによりインフラストラクチャの最適化をはかる手段を提供し、従来より運用しているミドルウェアやアプリケーションを改変することなく導入することができる基礎技術です。サーバー仮想化を導入するにあたり、仮想化に付随して生じる煩雑なリソース管理を担うプライベートクラウド基盤が必要となりました。
OpenStack は仮想化されたリソースの管理を一手に担い、既存のオンプレミスの資産上にも展開できる拡張性を備えたクラウド基盤ソフトウェアでした。OpenStack で管理されたサーバープールから、API を通してオンデマンドに必要とされる量のリソースを払い出すことで、インフラストラクチャの最適化をはかります。図 1 に、目指したサーバープール運用を一般的なプロダクトのインフラ構成をもとに示します。

図 1. サーバープール運用
導入に向けて
ここからは導入に向けて開発したシステムについてご紹介させていただきます。
全体構成
システムの全体構成を図 2 に示します。OpenStack は既存のシステムとの親和性を保ちつつ、VM リソースをオンデマンドに払い出せるように拡張しています。VM を払い出した後は、物理サーバと同様にミドルウェアのプロビジョニングやコンテンツデプロイなど従来の運用操作ができます。
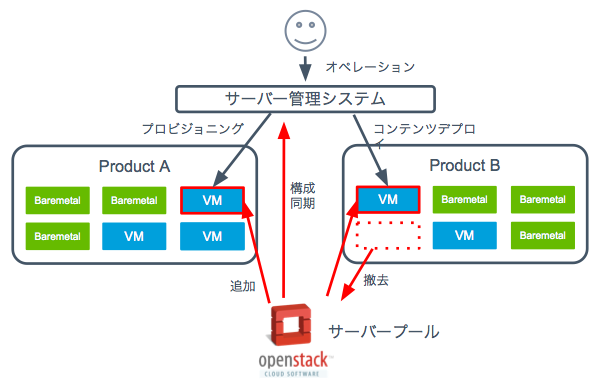
図 2. システム構成図
VM
サーバーリソースを仮想化するにあたって、仮想化のオーバヘッドが少なからず生じます。仮想化の方式としてコンテナ型とハイパーバイザー型が上がりますが、前者はオーバヘッドこそ少ないもののリソースの独立性が低く運用観点でも制約がでてきてしまうため当時は検討対象から外しました。後者は I/O 仮想化によるオーバーヘッドが大きい点を許容すれば、従来の物理サーバーと同じような使い勝手で利用できるため、運用観点で受け入れやすい構成が実現できます。I/Oリソースを使い切るようなところはそもそも仮想化しないとの割り切りもあり後者を選択しています。
ハイパーバイザーとしては Xen hypervisor と KVM が候補に上がり、前者はパフォーマンスの観点で優位性は見られたものの、後者でもチューニングを施すことでおおむね同等のベンチマーク結果が得られた上、OpenStack のサポート状況としても HypervisorSupportMatrix より KVM が優位であることもあり後者を選定しました。
ネットワーク
従来の物理サーバーのネットワーク延伸上に VM を配置するという要件のもと、図 3 に示すように、プロダクト毎にネットワークを分離させたシンプルなマルチテナント環境を構築しました。ハイパーバイザー内におくソフトウェアスイッチには Open vSwitch を採用し、プロダクト毎にネットワークを分離しています。
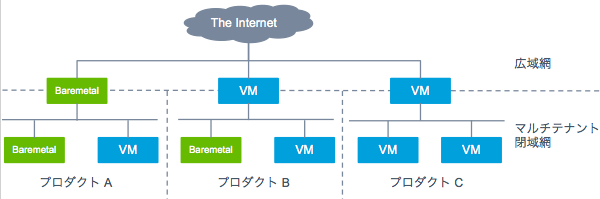
図 3. ネットワーク構成
ストレージ
VM のストレージには、LVM で管理されたローカルストレージを利用しています。LVM の他にも raw ベースのパーティションやファイルベースのイメージを検討しましたが、利便性とパフォーマンスのバランスがとれた LVM を採用しています。パフォーマンスの観点では特に、ハイパーバイザーの I/O オーバヘッドが大きく、複数 VM が同居する場合にはさらにディスクヘッドの奪い合いが起きるためランダム I/O が頻発し、性能低下につながります。そこでディスク I/O を激しくつかうような DB には無理せず物理サーバを使うといった割り切りをすることでリソース配分の最適化をはかっています。
OpenStack システム
最重要であることは、ユーザのみなさまにサービスを届ける VM を安定的に動かすことです。幸い OpenStack 自体が止まってもただちに VM に影響はありませんが、VM に対する操作が一切できなくなったり、VM を取り巻く構成情報に不整合が起こると途端に復旧が困難になりますので、OpenStack API やミドルウェアのエンドポイントには SPoF が無い構成をつくっています。図 4 にその冗長化構成を示します。API の前段には LB を配置し、冗長化と負荷分散をさせています。DB やメッセージキューでは、active / standby の冗長化構成をとっています。
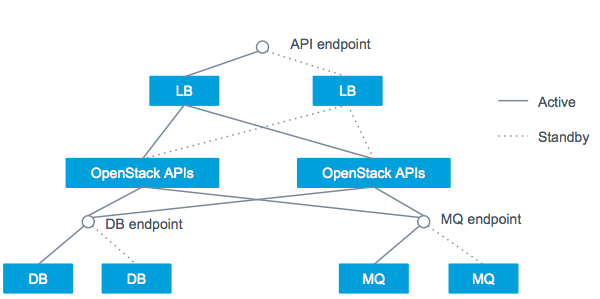
図 4. OpenStack 冗長化構成
運用を通して
ここからは日々の運用を通して得られた知見などをご紹介させていただきます。
リソースプール運用
OpenStack で管理されたサーバープール上のリソースは全て API でコントロールできるため、日常の運用で繰り返されるような作業はこの API をもとにシステム化しています。ブラウザから OpenStack を操作できる OpenStack Dashboard というオフィシャルのプロジェクトがありますが、既存のシステムと連携させる上で要件に合わなかったため独自に開発しています。VM の払い出しや撤去の際はポータルサイトで操作をするだけで済むようになりました。
OpenStack を操作するための SDK は数多く提供されており、開発は容易です。Python であれば本家 SDK がありますが、マルチクラウドに対応した libcloud や Ruby 製の fog といったライブラリなどもあり、用途応じて柔軟に開発できます。
OpenStack には VM の配置を司るスケジューラがありますが、物理サーバーが故障した際のサービスの冗長性を担保するという観点で配慮不足でした。当時のスケジューラーでは、同一サービスのウェブサーバ群が同じハイパーバイザー上に配置されてしまう問題がありました。そこで、サービスの可用性を担保するルールを適用するスケジューラーを開発しました。現在では Instance Group が実装されたため、OpenStack 本体でも同様の機能が実現できるようになりました。
ハイパーバイザー障害時の影響範囲特定
物理サーバーに障害はつきものですので、障害によってはハイパーバイザーもダウンします。サービスの冗長構成はミドルウェアで担保していますが、その影響範囲を即座に特定し、通知する仕組みが必要とされてきます。ハイパーバイザーの死活監視は別途行っていますが、障害がわかってもその上で稼働している VM が即座にわからないと困るので、OpenStack API を呼んで影響範囲を特定するようにしています。
以下に、ホスト名 “example-hostname” がダウンした際の影響範囲を特定する API 操作の例を示します。
- OpenStack Identity Service から OpenStack Service にアクセスするためのトークンを取得します
123456789101112$ curl -H "Content-Type: application/json" \> -d '{"auth": {"tenantName": "tenant","passwordCredentials": {"username": "user","password": "password"}}}' http://openstack-api-service:5000/v2.0/tokens 2>/dev/null | jq '.access.token.id'"094b634b4f25aace38d6e5bc52b774a4" - OpenStack Compute Service に対して指定したハイパーバイザー上の VM 一覧を問い合わせます※1
123456789101112131415161718192021$ curl -H "Content-Type: application/json" \> -H "X-Auth-Token: 094b634b4f25aace38d6e5bc52b774a4" \> http://openstack-api-service:8774/v2/<tenant-id>/os-hypervisors/example-hostname/servers | jq ‘.’{"hypervisors": [{"id": 1,"hypervisor_hostname": "hostname","servers": [{"uuid": "f27bedd8-212c-4920-9381-d53414da76eb","name": "instance-00000002"},{"uuid": "e8f1d7b9-7417-0a4e-1eb2-66a8fe62203a","name": "instance-00000004"}]}]} - OpenStack Compute Service に対して VM の UUID をキーにしてハイパーバイザー情報を問い合わせ、稼働中の VM 群の IP アドレスを特定します
123456789101112131415161718$ curl -H "Content-Type: application/json" -H "X-Auth-Token: 094b634b4f25aace38d6e5bc52b774a4" http://openstack-api-service:8774/v2/<tenant-id>/servers/f27bedd8-212c-4920-9381-d53414da76eb 2> /dev/null | jq '.server.addresses'{"tenant-network": [{"version": 4,"addr": "192.0.2.2"}]}$ curl -H "Content-Type: application/json" -H "X-Auth-Token: 094b634b4f25aace38d6e5bc52b774a4" http://openstack-api-service:8774/v2/<tenant-id>/servers/e8f1d7b9-7417-0a4e-1eb2-66a8fe62203a 2> /dev/null | jq '.server.addresses'{"tenant-network": [{"version": 4,"addr": "192.0.2.4"}]}
※1 余談ですが、OpenStack Compute API v2 / v3 ではハイパーバイザー検索はホスト名の部分一致にしか対応していません。そこで完全一致と部分一致双方の検索に対応できるパッチを作りましたが、API の挙動が変わってしまうこともあり本家へのマージは見送りました。パッチはこちらから - https://review.openstack.org/#/c/95378/2/nova/db/sqlalchemy/api.py
OpenStack コントローラーの負荷対策
OpenStack は物理サーバー群を Region や Cell という単位で管理しています。これらの構成を設計する上で、メッセージキューや DB の負荷を考慮しておく必要があります。これらに対する負荷の大部分は、ハイパーバイザー内で動作するエージェントが定期的に実行する periodic_task に起因するものです。periodic_task には、VM の稼働状況などハイパーバイザーのステータス、OpenStack サービスの死活監視を定期的にレポートする、などのタスクが積まれています。periodic_task から流れるメッセージ量は、ホストの台数に応じて線形に増加し、メッセージキューを詰まらせる要因となります。一方で、このメッセージの流量を調整することで、収容台数を大まかに決められます。
メッセージの流量はパラメータで調整できます。OpenStack Juno (2014年10月版) では report_interval により実行間隔を調整します。いくらメッセージの流量を下げても、実行タイミングが重なってしまうと瞬間的にスパイクが出てしまいますので、periodic_fuzzy_delay パラメータによる調整や、jitter による実行タイミングの揺らぎも実装されています。OpenStack サービスの死活監視は、今では Compute Service Group ZooKeeper を使って分散化する手法もあります。
さいごに
OpenStack の運用をはじめた当初は課題山積の状態ではありましたが、2年間使い込む中で使い勝手の良いツールとなり、日々の運用においても手間もかからないものになりました。
仕掛かりから 2年が経過し周辺技術も発展する中で、また視点を変えて最適な構成を再考する時期になってきた頃合いでもありますので、さらに新しい挑戦を経て、有用な知見を共有できるようになれればと思います。
明日は竹辺さんによる OpenStack Swift の記事です。お楽しみに!