(OpenStack juno) ホストスケジューラの仕組み
はじめに
こんにちは。『GREE Advent Calendar 2014』の 23 日目の記事を担当しますインフラストラクチャ本部開発部の大山です。昨年の AdventCalendar で OpenFlow コントローラ Trema について書き、少し前には WhiteBox について の記事を書いてみたりとし、最近はずっと OpenStack の構築と運用を行っています。
OpenStack は AWS や Google Cloud, Microsoft Azure といったものに代表されるような IaaS クラウド基盤環境を実現する OSS として知られ、ヤフーや楽天といった大手サービスプロバイダや、GMO インターネットといったクラウドホスティングサービスを提供する会社などで採用されています。また、ニーズの増加や OpenStack の機能面・実績面での強化に伴い、今後ますます利用されてゆくと予想されます。グリーにおいても 1 年以上前から様々な検証を経てプロダクション環境への導入を実施しており、これについては 今年の AdventCalendar の松橋さんのエントリ が詳しいです。
今回は OpenStack の中でも、VM インスタンスをどのホストで起動するかを選択する nova-scheduler という機能の仕組みと実装について見てゆきます。サービスの運用形態によっては、あるインスタンスは特定のホスト群で動作させたい(あるいはさせたくない)といった要求が出てくることがあると思います(例えば、特定のサービスを提供するインスタンスはホスト分散、あるいはラック分散させたいといったように)。
今回の内容を把握することによって、ホストスケジューリングのカスタマイズや scheduler 自体や関連ドライバを独自に実装する方法といった、より実践的なカスタマイズについて理解できるようになると思います。
nova-scheduler の位置づけ
図1 が OpenStack を説明する際によく用いられる OpenStack の主要なコンポーネントとそれらの相互関係を表した図になります。
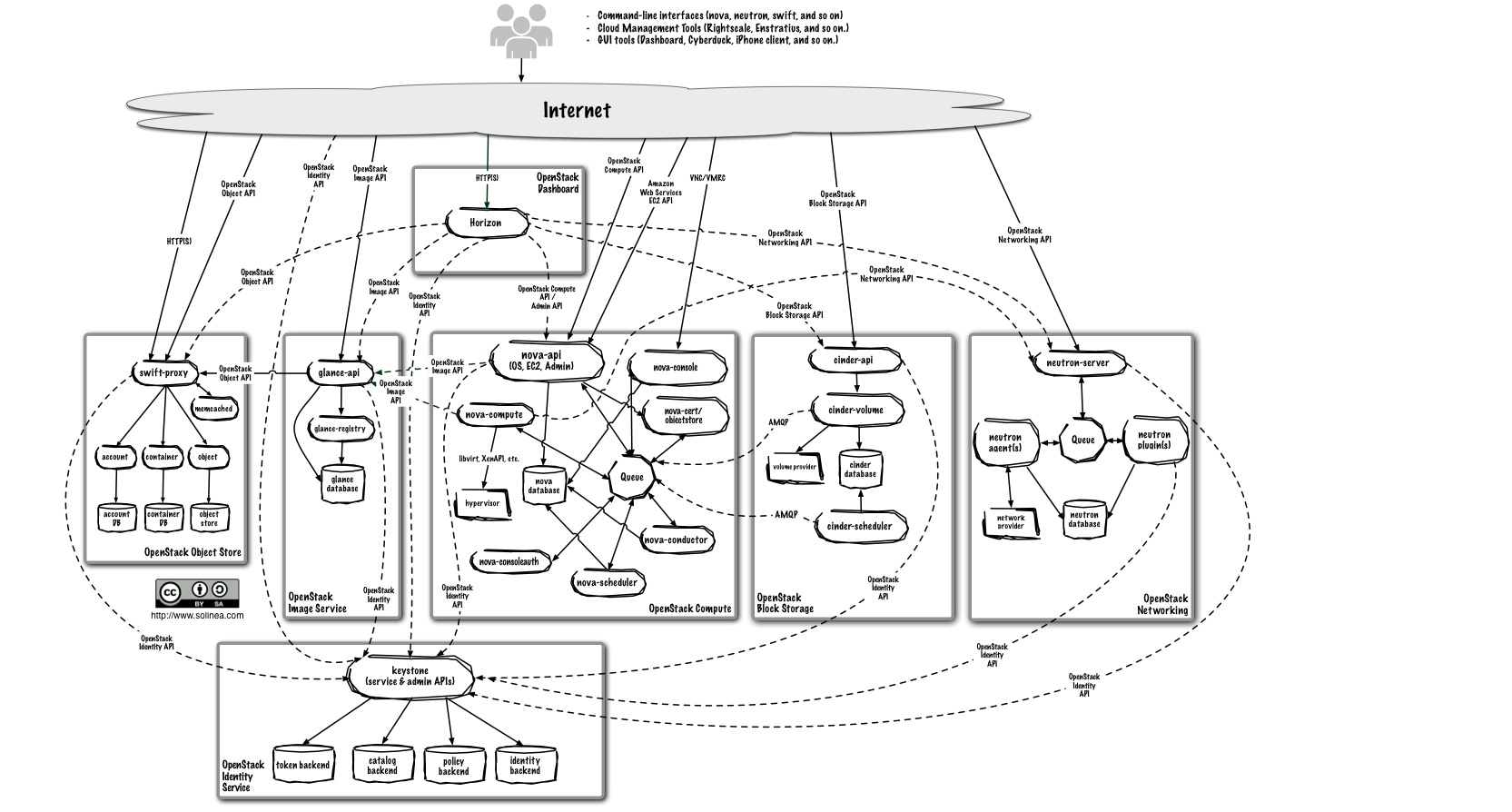
図1. OpenStack のアーキテクチャ
(出典:OpenStack Administrator Guide -Logical Architecture-)
そして図2 が、今回フォーカスする VM インスタンスを管理するコンポーネント nova に注目した図になります。
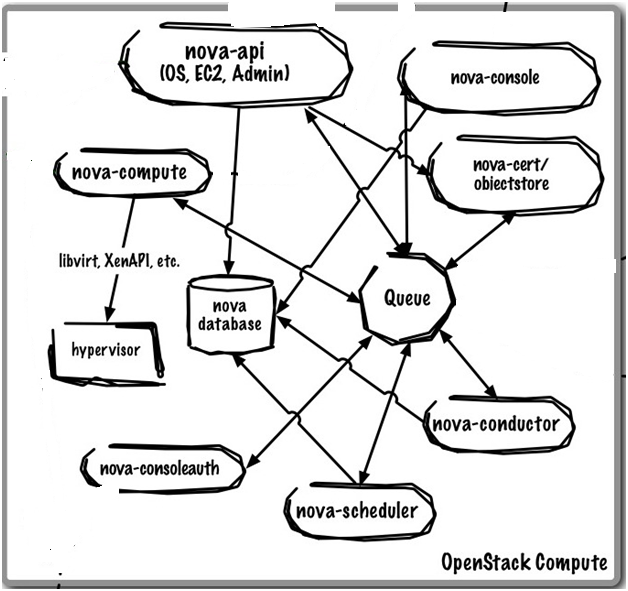
図2. nova コンポーネントの拡大図
(出典:CLOUD ARCHITECT MUSINGS -ARCHITECTURAL OVERVIEW-)
一見複雑に見えますが、今回のお話で登場するのはこのうち nova-api と nova-compute そして、nova-scheduler の 3 つになります。このうち nova-scheduler の内部の構成を表したものが図3になります。
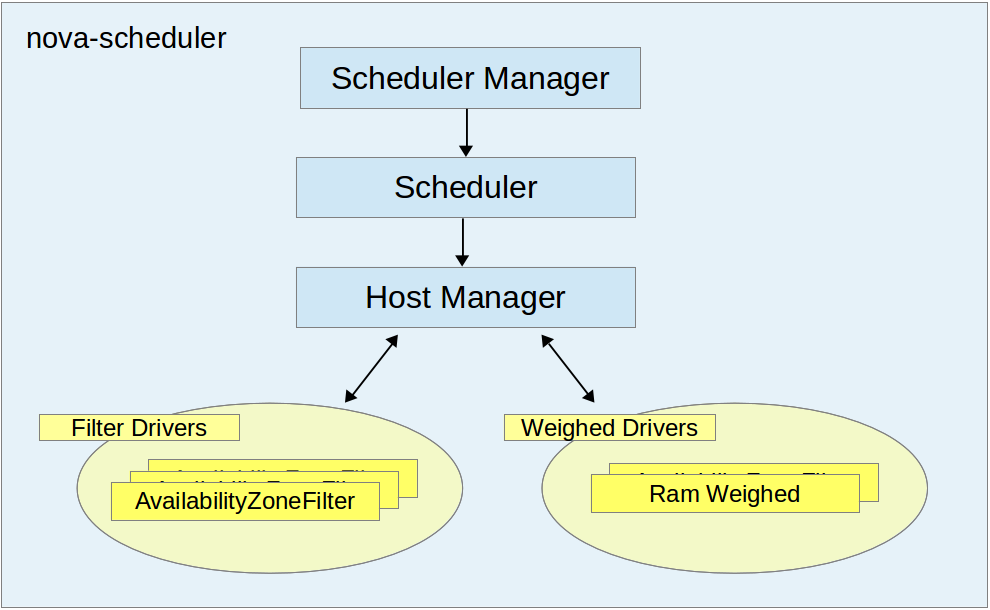
図3. nova-scheduler の内部構造
これらがどういう仕組みでどのように動作しているか、実装を見ながら追ってゆきます。
nova-scheduler の概要
実際のコードを追う前に nova-scheduler の動作を簡単に把握しておきたいと思います。nova-scheduler は nova-api からの VM インスタンスの作成要求に対して、大きく以下の2つの処理を行います。
* インスタンスが起動できるホストの洗い出し (Filtering)
* インスタンスを起動するホストの優先度付け (Weighting)
これらの処理を説明する図が OpenStack の開発ドキュメントにありましたので引用します。

図4. スケジューリング処理概要
(出典:OpenStack Developer Manual -Filter Scheduler-)
まず Filtering 処理では、controller が把握している全ての vmhost のうち、要求されたインスタンスを起動させることのできる全てのホストのリストを返却します。
次に Weighting 処理によって、起動可能なホストのうち、優先的に起動させたいホストの選択を行います(ex. メモリが多く搭載されているホスト、CPU 利用率が低いホストなど)。
これらの結果、選び出されたホストで動作する nova-compute manager に対してインスタンスを起動させる rpc 要求を送ります。
実装
OpenStack は様々なコンポーネントが独立したプロセスとして存在しており、それらが rpc によって有機的に結合していることで大きな集合を成しています。こうした設計によって、将来起こりうる様々な変化に柔軟に対応できるようになっています。これはコンポーネント間に限ったことではなく、コンポーネント内部においても、様々な状況や要求に対して、カスタマイズやパラメータ調整によって動作を変更できる柔軟な設計になっています。
以下が、今回触れる nova-scheduler の動作を決定付けるパラメータになります。nova-scheduler で定義されているパラメータはこの他にもたくさんありますが、説明の都合上さらに詳細なパラメータについては、説明の都度紹介します。
| 設定パラメータ | 設定内容 |
|---|---|
| scheduler_manager | スケジューラマネージャ。 スケジューラドライバを呼び出しインスタンスを起動させる |
| scheduler_driver | スケジューラドライバ。ホストマネージャを呼び出し、 インスタンスを起動するホストを選択する |
| scheduler_host_manager | ホストマネージャ。 起動する VM に適したホストを選択する処理を行う |
これらのパラメータは nova-scheduler の動作の基幹部分の実装を指定するもので、通常デフォルト値を指定します。この後に紹介する各実装内部のパラメータを調整することで、様々な要求に応じたホストの選択を行えるようになると思います。
以下では、これらデフォルトのパラメータの実装によって、どのようにホスト選択が行われるのかの処理の仕組みを見てゆきます。
スケジューラマネージャー
nova-api がインスタンスの起動要求を受けると nova-scheduler の select_destination に対して rpc 要求を送ります。以下がスケジューラマネージャーの select_destinations API の実装になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class SchedulerManager(manager.Manager): """Chooses a host to run instances on.""" def select_destinations(self, context, request_spec, filter_properties): """Returns destinations(s) best suited for this request_spec and filter_properties. The result should be a list of dicts with 'host', 'nodename' and 'limits' as keys. """ dests = self.driver.select_destinations(context, request_spec, filter_properties) return jsonutils.to_primitive(dests) |
スケジューラマネージャーは、インスタンスの起動ホストを選択するためにスケジューラドライバの select_destinations メソッドを呼び出します。
以下では、デフォルトのスケジューラドライバ (nova.scheduler.filter_scheduler.FilterScheduler) における select_destinations メソッド以下の処理の詳細について見てゆきます。
スケジューラドライバ
以下デフォルトのスケジューラドライバの select_destinations メソッドの抜粋になります。
|
1 2 3 4 5 6 7 8 9 10 11 |
class FilterScheduler(driver.Scheduler): """Scheduler that can be used for filtering and weighing.""" def select_destinations(self, context, request_spec, filter_properties): """Selects a filtered set of hosts and nodes.""" selected_hosts = self._schedule(context, request_spec, filter_properties) dests = [dict(host=host.obj.host, nodename=host.obj.nodename, limits=host.obj.limits) for host in selected_hosts] return dests |
select_destinations メソッドは、要求されたインスタンスのスペック (reqeust_spec) 及びユーザ指定条件 (filter_properties) に基づいて、最適なホストの選択を行います。以下、ホストの選択を行う内部メソッド (_schedule) の抜粋になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def _schedule(self, context, request_spec, filter_properties): """Returns a list of hosts that meet the required specs, ordered by their fitness. """ ... # Find our local list of acceptable hosts by repeatedly # filtering and weighing our options. Each time we choose a # host, we virtually consume resources on it so subsequent # selections can adjust accordingly. hosts = self._get_all_host_states(elevated) ... # Filter local hosts based on requirements ... hosts = self.host_manager.get_filtered_hosts(hosts, filter_properties, index=num) weighed_hosts = self.host_manager.get_weighed_hosts(hosts, filter_properties) scheduler_host_subset_size = CONF.scheduler_host_subset_size if scheduler_host_subset_size > len(weighed_hosts): scheduler_host_subset_size = len(weighed_hosts) if scheduler_host_subset_size < 1: scheduler_host_subset_size = 1 chosen_host = random.choice( weighed_hosts[0:scheduler_host_subset_size]) selected_hosts.append(chosen_host) |
まず _get_all_host_states 内部メソッドによって、OpenStack Controller が把握する全ホストのうちアクティブなホストのリストを取得します。その後、ホストマネージャーの get_filtered_hosts メソッドを呼び出し、先に述べた Filtering 処理を行います。
ここまでの処理によって、インスタンスを実行可能なホストのリストが得られましたが、最終的にインスタンスを起動させるホストを 1 つに絞り込まなければなりません。その絞り込み処理の前処理 (Weighting 処理) がホストマネージャーの get_weighted_hosts メソッドになります。ここでは get_filtered_hosts によって得られたホストのリストに対し、ユーザ指定条件で与えられる優先度に基づいてソート処理を行います。これによって、もっとも優先度が高いホストが先頭に来るように降順にホストがソートされます。
その後、ホストの絞り込み処理が行われます。優先度でソートされたホストのリストの先頭から scheduler_host_subset_size で指定された数だけホストを取得し、その中からランダムに一つのホストを選択します。ここで選ばれたホストが最終的にインスタンスが起動されるホストになります。尚、この scheduler_host_subset_size は、設定ファイル /etc/nova/nova.conf から変更でき、デフォルトの値は 1 になります。
それでは最後に、ホストマネージャーによる Filtering 処理と Weighting 処理の実装がどうなっているかについて見てゆきます。
ホストマネージャ
ホストマネージャーは各 nova-compute ノードの状態スペック等の情報を持ち、スケジューラドライバからの要求に対してインスタンスを起動する適切なホストを返します。以下では、デフォルトで指定される nova.scheduler.host_manager.HostManager における Filtering 処理、及び Weighting 処理の実装について見てゆきます。
Filering 処理
Filtering 処理は、get_filtered_hosts メソッドで実行されます。以下が当該メソッドにおける Filtering 処理を抜粋したものになります。実際のコードは nova boot 時の --availability-zone パラメータなどによって渡されるホストの指定等の例外処理がごちゃごちゃと書かれておりますが、処理の本質的な部分は以下の 2 つだけです。
|
1 2 3 4 5 6 7 8 9 |
class HostManager(object): """Base HostManager class.""" def get_filtered_hosts(self, hosts, filter_properties, filter_class_names=None, index=0): """Filter hosts and return only ones passing all filters.""" ... filter_classes = self._choose_host_filters(filter_class_names) ... return self.filter_handler.get_filtered_objects(filter_classes, hosts, filter_properties, index) |
まず でホストが起動かのうかどうかを判定するフィルタクラスと呼ばれるドライバを取得し、各ホストに対してこれらを適応する処理を行います。フィルタクラスは、"空きメモリ容量は足りているか", "空きストレージは十分か", "コア数は十分か" など無数のドライバが標準で用意されており、これらを組み合わせてインスタンスを起動可能なホストの選定を実施します。尚、適応するドライバは、設定ファイルの以下パラメータを調整することによって変更できます。
| 設定パラメータ | 設定内容 |
|---|---|
| scheduler_available_filters | 利用可能なホストフィルタのリスト (デフォルト値:nova.scheduler.filters.all_filters) |
| scheduler_default_filters | ホストのフィルタリング処理で実際に利用するフィルタのリスト |
デフォルトでは nova.scheduler.filters 以下で定義されている全てのフィルタクラスを利用することができ、実際には上記ので示すフィルタクラスが適応されます。
フィルタクラスの実装は、以下 BaseHostFilter を継承し host_passes メソッドを定義します。以下はフィルタクラスの親クラス BaseHostFilter の定義になります。
|
1 2 3 4 5 6 7 8 |
class BaseHostFilter(filters.BaseFilter): """Base class for host filters.""" ... def host_passes(self, host_state, filter_properties): """Return True if the HostState passes the filter, otherwise False. Override this in a subclass. """ raise NotImplementedError() |
host_passes メソッドは、ホストのスペック、起動インスタンス数、使用メモリ容量等のホストの状態を表す HostState オブジェクトと、インスタンスのスペックとユーザ指定条件をマージした filter_properties の 2 つの引数を受け取ります。そして当該ホストでインスタンスが起動可能であるならば True を返し、そうでなければ False を返します。
こうしてフィルタリングされたホストのリストが次の Weighting 処理に回されます。
Weighting 処理
Weighting 処理は、get_weighed_hosts メソッドによって実施されます。以下が実装の全文になります。
|
1 2 3 4 |
def get_weighed_hosts(self, hosts, weight_properties): """Weigh the hosts.""" return self.weight_handler.get_weighed_objects(self.weight_classes, hosts, weight_properties) |
Filtering 処理同様、ローダブルなドライバによって優先度付けソートを行っています。設定ファイルの scheduler_weight_classes パラメータによって、使用するドライバリストを指定できます。デフォルトでは、nova.scheduler.weights 配下にある全てのドライバを利用できるように設定されています。
Filtering 処理の場合と違い、Weighting 処理では Ram と Metrics の 2 つのドライバだけが用意されています。RAM ドライバによる重み付けを行う場合には、ram_weight_multiplier 設定パラメータを調節します。またユーザ定義メトリック値の重み付けを行う Metrics ドライバを使用する場合には、weight_setting 設定パラメータにより、注目するホストのメトリック値及び重み値のリストを設定します。
但し、デフォルトでは全ての重み値は 1.0 に設定されているため、Weighting 処理によるホストのソートは実施されません。
まとめ
nova-scheduler の内部の仕組みがどうなっているかや、インスタンスを実行するホストがどのように選ばれているホストの実装がどうなっているか、そしてどの部分をどうカスタマイズすれば、どのような事が出来そうかということが分かっていただけたでしょうか。
OpenStack では、近年話題のクラウドオーケストレーションを担う Heat プロジェクトや、従来の仮想インスタンスの管理だけではなく、物理サーバのプロビジョニングを担う Ironic プロジェクトなど様々な機能が追加され、IaaS クラウドの領域における OpenStack の有用性はますます広がっています。また冒頭で触れたように、我々や他の大手コンテンツプロバイダーがこぞって採用し始めたことで、その重要性も増しています。
こうした背景から OpenStack の運用ノウハウを蓄積する重要性は今後ますます高まってゆくと思われます。今回のエントリがそのお役にたてたなら幸いです。
最後まで読んでくださり、ありがとうございました。
---
明日は Ruby コミッタの高野光弘さんの記事になります。お楽しみに。